Revenue and Expenses: Year-to-Year Overview
Let's start by reviewing TPRF's revenue and expenses over the years.
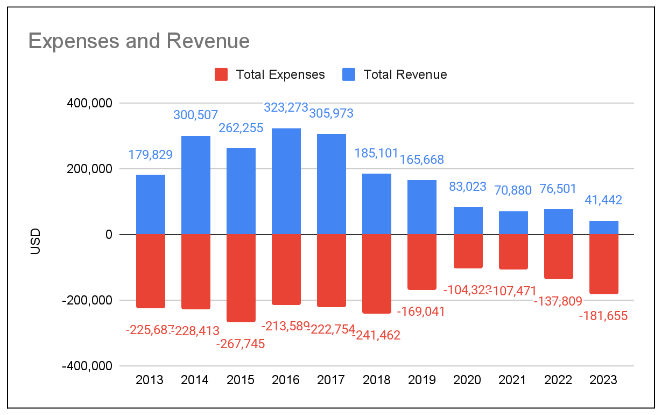
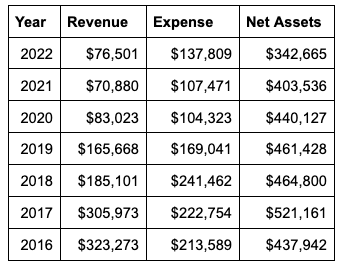
Until 2019, both revenue and expenses fluctuated. However, in 2020, the financial landscape changed significantly, with both revenue and expenses dropping sharply. This trend continued into 2021, largely because TPRF held its conferences virtually, reducing costs but also potentially limiting revenue opportunities.
In 2023, TPRF experienced another sharp decline in revenue while expenses surged, leading to a large deficit of $140,213.
Here's a comparison of key financial figures over three years:
Revenue
2017: $305,973
2020: $83,023 (27% of 2017)
2023: $41,442 (50% of 2020)
Expenses
2017: $222,754
2020: $104,323 (47% of 2017)
2023: $181,655 (174% of 2020)
Assets
2017: $521,161
2020: $440,127 (84% of 2017)
2023: $200,215 (45% of 2020)
TPRF has faced financial challenges in recent years.
Expense Breakdown
Now, let's take a closer look at the breakdown of expenses:
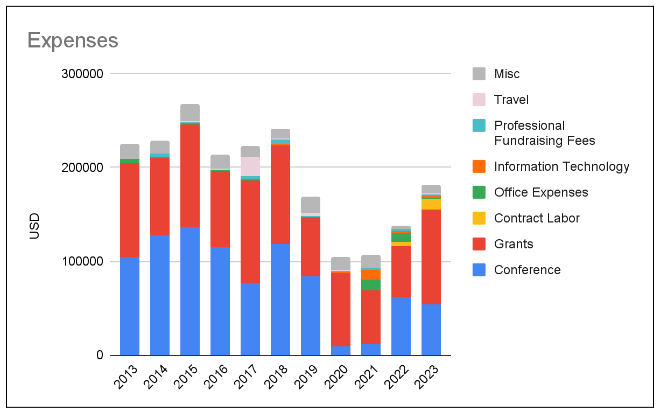
The largest portion of TPRF's expenses is related to conferences, which are the foundation's flagship events. While conference costs dropped in 2020 and 2021 when the events were held virtually, expenses rose again as in-person events resumed. Thanks to Ruth's careful planning, the budget for the 2025 in-person conference is similar to that of 2021.
Another significant category is grants. It's encouraging to see TPRF's ongoing commitment to supporting developers in the Perl and Raku communities. However, tax filings don't explain the doubled grant expenses between 2022 and 2023. After consulting with Peter, the TPRF treasurer, I learned the increase was due to a raise in both the number of Perl core grantees and their hours.
According to the tax filings, in 2021, TPRF spent $10,789 on information technology. In addition, $20,348 was allocated to office expenses in 2021-2022. Peter said they were used for contract labor, including accountants.
Revenue: Contributions and Program Services
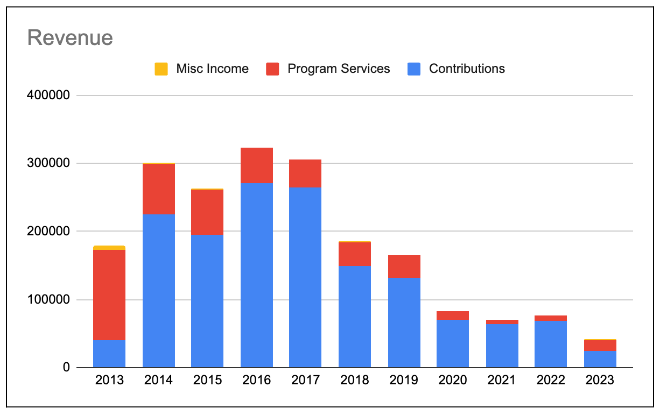
TPRF's revenue primarily comes from two sources: contributions (donations) and program services (mainly conference ticket sales).
Contributions peaked in 2016 at $270,517 but have been steadily declining. By 2023, contributions had dropped to just $24,395. This dramatic reduction is a clear indicator of the need for more proactive donor engagement and retention. In 2024, TPRF hired a part-time staff member to focus on fundraising.
My Thoughts
In hindsight, there are several key areas where TPRF could have taken steps to improve its financial health:
- Transparency: TPRF could have been more transparent. While tax filings are publicly available, it took me a week to decipher the financial data from the last decade. Publishing detailed and accessible financial reports could have yielded greater engagement from the community.
- Board Budget Review: Until recently, most board members had no visibility into the annual budget. In December 2023, for the first time during his tenure, the president presented the budget to the rest of the board, including me. This is a positive step.
- Donor Retention: The drop in revenue cannot solely be attributed to Perl's declining popularity. While some companies may have shifted their donations to other programming languages, TPRF could have done more to retain donors. For example, TPRF does not send personalized thank-you letters signed by the president, which is a missed opportunity to express gratitude and maintain positive relationships with the supporters.
- Sustainability of Rising Expenses: While it's great to see TPRF's continued investment in grants and even internships, the rising expenses will not be sustainable without a corresponding increase in revenue. The foundation's financial future is at risk if current trends continue.
- Realistic Budgeting: TPRF's 2024 budget set both revenue and expenses at $150,000. While I don't have the most recent figures, I suspect that the revenue fell short of this target while the expenses were met as planned. Going forward, TPRF should avoid relying on optimistic revenue forecasts and instead base its spending on confirmed income. Although this may mean the painful approach to temporarily pause grant disbursements when funds run low, it's a healthier approach than overspending based on projected―but not realized―revenue.
Conclusion
Analyzing TPRF's financial data has provided good insights. While there are clear strengths, such as TPRF's commitment to supporting developers through grants, the decline in revenue and increase in expenses signals a serious risk. It's time for TPRF to be more transparent, improve donor retention, and make sure expenses are aligned with sustainable revenue streams. I welcome any thoughts or suggestions on how TPRF can improve its financial standing and continue supporting the community.
Acknowledgments
I would like to extend my sincere thanks to my friend and former board member, Dave Rolsky, for his valuable input. His insights and support gave me the energy I needed to complete this difficult article. I also appreciate Peter Krawczyk for answering my questions and making suggestions for this article.
]]>