Hi!
For those whom it may concerns Sparrow announces move to Perl6. I've have started the reddit thread to explain what and why.
Thank you
Alexey
]]>
Hi!
For those whom it may concerns Sparrow announces move to Perl6. I've have started the reddit thread to explain what and why.
Thank you
Alexey
]]>Regards
Alexey Melezhik
]]>Outthentic - is universal, language independent framework to encourage scripts development in easy and fun manner.
Here is short introduction into it - "Outthentic – quick way to develop users scenarios".
]]>https://sparrowdo.wordpress.com/2017/02/01/sshscp-commands-with-sparrowdo/
Regards.
Alexey
]]>Well, I have dropped a small sparrow plugin to handle with this task. At least it works for me. It lists ( in plain text format ) all the repositories for given project and team. There a lot of option of plugin you will find at documentation but the usual workflow is:
$ sparrow plg install bitbucket-repo-list
Here you lists repositories for given project and team. You should supply your Bitbucket credentials to request team/project information:
$ sparrow plg run bitbucket-repo-list \
--param login=superuser --param password=keep-it-secret \
--param team=heroes \
--param project=humans
That is it. Hopefully will be useful for someone deal with BitBucket repositories.
]]>Here is my latest post about Sparrowdo configuration management tool written in Perl6 - Sparrow plugins vs ansible modules - an attempt of informal comparison of sparrow and ansible eco systems.
Regards.
Alexey
]]>In this post I am going to show how you can use Sparrow to test Mojolicious applications.
Sparrow approach to test things differs from convenient unit tests approach, practically this means:
A tested code is treated as black box rather than unit test way where you rely deeply on inner application structure.
A sparrow test suites are not a part of CPAN distribution ( the one you keep under t/* )
A sparrow test suite code is decoupled from tested application code and is better to be treated as third party tests for your application
Sparrow tests suites have it's own life cycle and get released in parallel with tested application
Sparrow acts like toolchain to choose proper tools and then analyze script output
IMHO writing sparrow tests sometimes is much simpler and takes less efforts and time, but I don't say you don't need a unit tests but sometime it worths it to take an alternative testing approaches / tools and see the difference , so if you are interested , please read below ...
Ok, let's go to the practical example.
A Mojolicious comes with some handy tools to invoke a http requests against web application.
Consider simple mojolicious code:
#!/usr/bin/env perl
use Mojolicious::Lite;
get '/' => {text => 'hello world'};
app->start;
Now we can quickly test a GET / route with help of mojolicious get command:
./app.pl get /
[Sun Dec 11 17:23:38 2016] [debug] GET "/"
[Sun Dec 11 17:23:38 2016] [debug] 200 OK (0.000456s, 2192.982/s)
hello world
That's ok. This is going to be a base for out first sparrow test:
$ nano story.bash
$project_root_dir/app.pl get /
$ nano story.check
hello world
$ strun
/ started
[Sun Dec 11 17:45:28 2016] [debug] GET "/"
[Sun Dec 11 17:45:28 2016] [debug] 200 OK (0.000469s, 2132.196/s)
hello world
ok scenario succeeded
ok output match 'hello world'
STATUS SUCCEED
What we have done here.
GET / against mojolicious application - file named story.bashMore about stories and check files could be found at Outthentic - a module for execution sparrow scripts.
Consider a negative result here, when test fails. For this let's change a check file to express we need another string returned from calling GET / route:
$ nano story.check
hello sparrow
$ strun
/ started
[Sun Dec 11 18:18:07 2016] [debug] GET "/"
[Sun Dec 11 18:18:07 2016] [debug] 200 OK (0.001237s, 808.407/s)
hello world
ok scenario succeeded
not ok output match 'hello sparrow'
STATUS FAILED (256)
As our test is just bash script it easy to add some debugging facilities into it:
$ nano story.bash
set -x
$project_root_dir/app.pl get /
And run the script:
/ started
++ /home/melezhik/projects/mojolicious-app-smoke/app.pl get /
[Tue Dec 13 13:16:07 2016] [debug] GET "/"
[Tue Dec 13 13:16:07 2016] [debug] Routing to a callback
[Tue Dec 13 13:16:07 2016] [debug] 200 OK (0.000328s, 3048.780/s)
hello world
ok scenario succeeded
ok output match 'hello world'
STATUS SUCCEED
Right now it looks pretty useless but becomes very handy for more complex scripts.
As your application grows it comprises many routes, let's how we organize our test suite layout to test them all.
$ cat app.pl
#!/usr/bin/env perl
use Mojolicious::Lite;
get '/' => sub {
my $c = shift;
$c->render( text => 'welcome page')
};
get '/hello' => sub {
my $c = shift;
$c->render( text => 'hello '.($c->param('name')))
};
get '/bye' => sub {
my $c = shift;
$c->render( text => 'bye '.($c->param('name')))
};
app->start;
Here is the story modules:
$ mkdir -p modules/welcome-page modules/hello modules/buy
# welcome page
$ echo '$project_root_dir/app.pl get /' > modules/welcome-page/story.bash
$ echo 'welcome page' > modules/welcome-page/story.check
# GET /hello
$ echo '$project_root_dir/app.pl get /hello?name=sparrow' > modules/hello/story.bash
$ echo 'hello sparrow' > modules/hello/story.check
# GET /bye
$ echo '$project_root_dir/app.pl get /bye?name=sparrow' > modules/bye/story.bash
$ echo 'bye sparrow' > modules/bye/story.check
And main story-container to call them all:
$ echo 'Smoke tests for app.pl' > meta.txt
$ nano hook.bash
run_story welcome-page
run_story hello
run_story bye
$ strun
/ started
Smoke tests for app.pl
/modules/welcome-page/ started
[Sun Dec 11 19:34:08 2016] [debug] GET "/"
[Sun Dec 11 19:34:08 2016] [debug] Routing to a callback
[Sun Dec 11 19:34:08 2016] [debug] 200 OK (0.00091s, 1098.901/s)
welcome page
ok scenario succeeded
ok output match 'welcome page'
/modules/hello/ started
[Sun Dec 11 19:34:09 2016] [debug] GET "/hello"
[Sun Dec 11 19:34:09 2016] [debug] Routing to a callback
[Sun Dec 11 19:34:09 2016] [debug] 200 OK (0.000871s, 1148.106/s)
hello sparrow
ok scenario succeeded
ok output match 'hello sparrow'
/modules/bye/ started
[Sun Dec 11 19:34:09 2016] [debug] GET "/bye"
[Sun Dec 11 19:34:09 2016] [debug] Routing to a callback
[Sun Dec 11 19:34:09 2016] [debug] 200 OK (0.001051s, 951.475/s)
bye sparrow
ok scenario succeeded
ok output match 'bye sparrow'
STATUS SUCCEED
What we have done here.
strun to execute test suiteMore about story modules and story containers be found at Outthentic - a module for execution sparrow scripts.
We hardcoded a string sparrow get passed as parameter to routes GET /hello and GET /buy.
Let's parametrize out test suite:
$ nano modules/hello/story.bash
name=$(story_var name)
$project_root_dir/app.pl get '/hello?name='$name
$ nano hook.bash
run_story welcome-page
run_story hello name Mojolicious
run_story bye
And then run our test suite:
# some output truncated ...
/modules/hello/ started
[Mon Dec 12 12:42:04 2016] [debug] GET "/hello"
[Mon Dec 12 12:42:04 2016] [debug] Routing to a callback
[Mon Dec 12 12:42:04 2016] [debug] 200 OK (0.000845s, 1183.432/s)
hello Mojolicious
ok scenario succeeded
not ok output match 'hello sparrow'
/modules/bye/ started
Obviously our test failed as we need to change a check list:
$ nano modules/hello/story.check
generator: [ "hello ".(story_var('name')) ]
Generators are way to create story check list in runtime. More on this read at Outthentic doc pages.
story_var is bash helper function letting our stories to get the parameter they are called from story container. By the way as sparrow is kind language agnostic framework we could write our code on plain Perl:
$ nano modules/hello/story.pl
my $name = story_var('name');
my $cmd = project_root_dir()."/app.pl get '/hello?name=$name'";
print `$cmd`
Or even Ruby:
$ nano modules/hello/story.rb
name = story_var 'name'
puts `#{project_root_dir}/app.pl get '/hello?name=#{name}'`
I did not tell you, one day I am going to add Python support ... :)
Ok, now let's make our name parameter configurable via configuration file
Sparrow test suites maintain three well known configuration formats:
Let's go with Config::General. As our example quite trivial the configuration won't be too complicated:
$ nano suite suite.ini
name Sparrow
$ nano hook.bash
name=$(config name)
run_story welcome-page
run_story hello name $name
run_story bye name $name
We can even use nested configuration parameters:
$ nano suite suite.ini
<name>
bird Sparrow
animal Fox
</name>
$ nano hook.bash
bird_name=$(config name.bird)
animal_name=$(config name.animal)
run_story welcome-page
run_story hello name $bird_name
run_story bye name $animal_name
And finally we can override parameters via command line:
$ strun --param name.animal='Bear'
As I said we could use another configuration formats, like for example JSON:
$ nano suite.json
{
"name" : {
"bird" : "sparrow",
"animal" : "bear"
}
}
$ strun --json suite.json
Sometimes we need to process output data to make it testable via Sparrow. It's very common when dealing with application emitting JSON:
$ cat app.pl
#!/usr/bin/env perl
use Mojolicious::Lite;
get '/echo-name' => sub {
my $c = shift;
$c->render( json => { name => $c->param('name') } )
};
app->start;
Sparrow does not provide any built in capabilities to parse JSON, but it rather acts as tool where one can add any desired modules into "pipeline":
$ nano hook.bash
name=$(config name)
run_story echo-name name $name
$ mkdir -p modules/name
$ nano modules/echo-name/story.bash
name=$(story_var name)
$project_root_dir/app.pl get '/echo-name?name='$name \
| perl -MJSON -e 'print decode_json(join "", <STDIN>)->{name}'
Now let's run the test:
/ started
Smoke tests for app.pl
/modules/echo-name/ started
[Tue Dec 13 12:00:18 2016] [debug] GET "/echo-name"
[Tue Dec 13 12:00:18 2016] [debug] Routing to a callback
[Tue Dec 13 12:00:18 2016] [debug] 200 OK (0.00054s, 1851.852/s)
sparrow
ok scenario succeeded
ok output match 'sparrow'
STATUS SUCCEED
This approach could be generalized to any data processing like YMAL/XML/CSS. Instead of defining data parsing at test logic we filter/process output data to "map" it to sparrow testing format - just a lines of text where we could make regexp/text search.
Ok let's keep moving. Prepare our test suite for distribution.
A one thing we should pay attention to. A mojolicious application we write tests for in practice is distributed separately from sparrow test suite. There are some cases:
Whatever case we consider it's not hard to adopt our test suite to new reality. For example
if there is script called our_mojolicious_application we just need to change small bit of code
to rely on system wide installation instead of local:
$ nano modules/hello/story.bash
name=$(story_var name)
our_mojolicious_application get '/hello?name='$name
That is it.
Sparrow works smoothly with Perl/Ruby well known dependency managers to work out on this, just create a cpanfile with dependencies in case of Perl:
$ nano cpanfile
requires 'JSON'; # indeed not required for recent Perls
This is important point where we define some data to make it possible upload our test suite to SparrowHub - a sparrow scripts repository
$ nano sparrow.json
{
"name" : "mojolicious-app-smoke"
"description" : "smoke tests for our Mojolicious application",
"version" : "0.0.1",
"url" : "https://github.com/melezhik/mojolicious-app-smoke"
}
We name our test suite, give it a version, provide short description and provide source code link (github).
Also let's provide a small README.md to let other understand what it is:
$ nano README.md
# SYNOPSIS
Make some smoke tests against our mojolicious application
# INSTALL
$ sparrow plg install mojolicious-app-smoke
# USAGE
$ sparrow plg run mojolicious-app-smoke
# Author
Alexey Melezhik
Now let's commit our changes
$ git init
$ git add .
$ git commit -a 'first commit'
$ git remote add origin https://github.com/melezhik/mojolicious-app-smoke.git
$ git push -u origin master
Finlay we are ready to upload a test suite to SparrowHub:
$ sparrow plg upload
sparrow.json file validated ...
plugin mojolicious-app-smoke version 0.000001 upload OK
Once you make changes to your test suite you bump a version and release a new stuff into Sparrowhub. As I told you a sparrow test suite has it own life cycle separated from application being tested.
Finally If for security reasons you don't want to make your test suite public Sparrow allow you to host your scripts at private git repositories ( github/bitbuket).
Ok. Now having a test suite as sparrow plugin we could easily install and run it somewhere we need:
$ sparrow plg install mojolicious-app-smoke
$ sparrow plg run mojolicious-app-smoke
We can even override a test suite parameter via command line:
$ sparrow plg run mojolicious-app-smoke --param name.bird=woodpecker
Or create a configuration via sparrow task:
$ sparrow project create webapp
$ sparrow task add webapp smoke-test mojolicious-app-smoke
$ sparrow task ini webapp/smoke-test
<name>
bird Woodpecker
animal Fox
</name>
To get plugin documentation simply run:
$ sparrow plg man mojolicious-app-smoke
Or view plugin page at SparrowHub site - https://sparrowhub.org/info/mojolicious-app-smoke .
There are many other fun things you could do with Sparrow API, please follow Sparrow documentation.
What we have just learned:
Regards
Alexey Melezhik
]]>Preamble: CPAN is great. This post in no way should be treated as Sparrow VS CPAN attempt. Sparrow is just an alternative method to distribute your scripts. Ok, let's go.
So let’s say I’ve got this Perl script:
$ cat story.pl
use strict;
use warnings;
use DateTime;
my $text = 'bar';
my $dt = DateTime->now;
if ($dt->mon == 1 && $dt->day == 31) {
$text = reverse $text;
}
print "$text\n";
exit 0;
Notice I have called my script story.pl? This is a naming convention for sparrow scripts.
Ok, let's move on.
All we need is to:
Sparrow scripts should be accompanied by a check file. It's just a text file with some patterns to match against stdout emitted by an executed script. For example:
$ cat story.check
regexp: (bar|rab)
Here we just require that script yields into stdout one of two lines - bar or rab. That is it.
Sometimes we don't need to check script stdout , that's ok just leave the story.check file empty:
$ echo > story.check
As we have an external dependency (the DateTime module) let's put it in a cpanfile:
$ cat cpanfile
requires 'DateTime'
Sparrow uses carton to run script with dependencies. That is it.
In a plugin meta file one defines essential information required for script upload to SparrowHub. The structure is quite simple, there should be a JSON format file with these fields:
In other words the sparrow meta file is the way to "convert" an existing script into sparrow plugin:
$ cat sparrow.json
{
"name" : "bar-script",
"version" : "0.0.1",
"description" : "print bar or rab",
"url" : "https://github.com/melezhik/bar-script"
}
You might want to add some documentation to the script. Simply create a README.md file with documentation in markdown format:
$ cat README.md
# SYNOPSIS
print `bar` or `rab`
# INSTALL
$ sparrow plg install bar-script
# USAGE
$ sparrow plg run bar-script
# Author
[Alexey Melezhik](melezhik@gmail.com)
# Disclosure
An initial script code borrowed from David Farrell article [How to upload a script to CPAN](http://perltricks.com/article/how-to-upload-a-script-to-cpan/)
Finally we have the following project structure:
$ tree
.
├── cpanfile
├── README.md
├── sparrow.json
├── story.check
└── story.pl
0 directories, 5 files
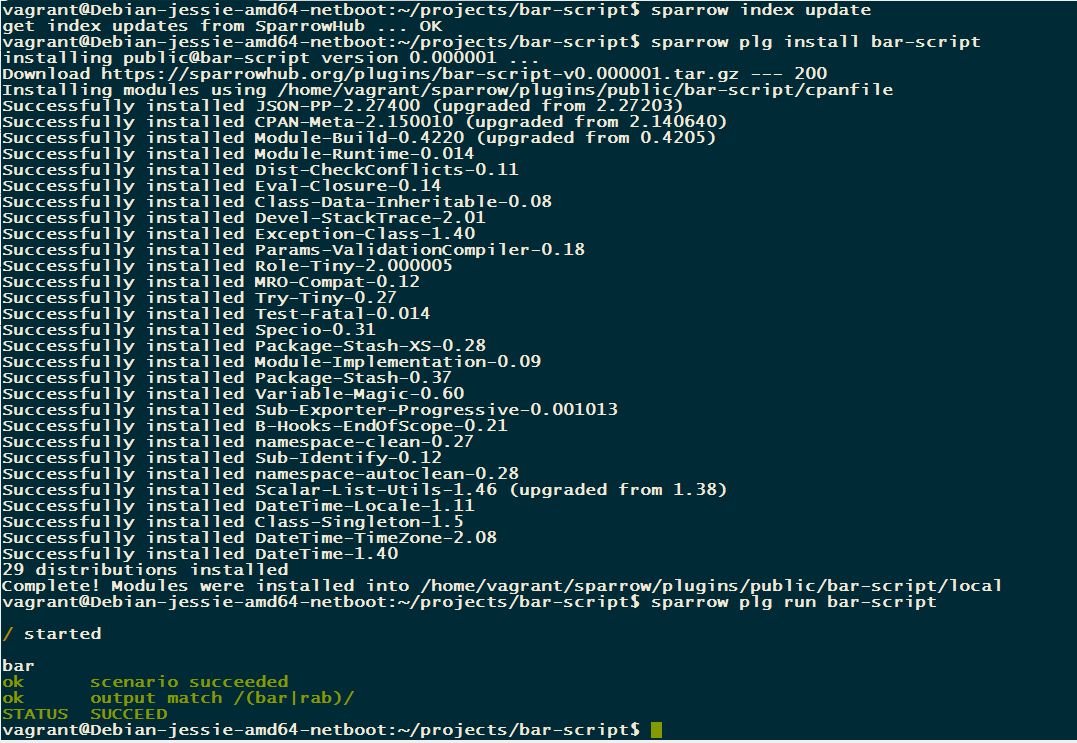
To see that the script does what you want simply run strun inside the project root directory:
$ carton # install dependencies
$ carton exec strun
/ started
bar
ok scenario succeeded
ok output match /(bar|rab)/
STATUS SUCCEED
Strun - is utility comes with Sparrow to run sparrow scripts, it is used by plugin developers.
Provided you have an account on SparrowHub, just do this:
$ sparrow plg upload
sparrow.json file validated ...
plugin bar-script version 0.000001 upload OK
Now you can browse the script information at SparrowHub.
To run the script you need to install and run it with the sparrow client:
$ sparrow index update
$ sparrow plg install bar-script
$ sparrow plg run bar-script
PS. Thanks to David Farrell for "giving" an idea of writing this post ( after reading his article ) and for fixing some typos and style errors in this document.
]]>Give me list of available plugins:
$ sparrow plg search
type name
public app-cpm
public bash
public bitbucket-repo
public check-tomcat-deploy
public chemaxon-check
public cpan-package
public df-check
public directory
public docker-engine
public file
public foo-generic
public foo-test
public git-async-push
public git-base
public git-svn-export
public gitprep
public group
public http-status
public logdog
public minion-check
public module-release
public mongodb
public nano-setup
public net-ping
public nginx-check
public nginx-example
public outth-mysql-cookbook
public package-generic
public perl-app
public perlbrew
public proc-validate
public ruby-test
public sendmail
public service
public sph-check
public ssh-sudo-check
public ssh-sudo-try
public sshd-check
public stale-proc-check
public svn-to-git-submodules
public swat-nginx
public swat-pintod
public swat-test
public templater
public user
private package-generic-dev
This plugin makes a trivial nano.rc file configuration:
$ sparrow plg install nano-setup
Project is just a container for plugins to group them logically:
$ sparrow project create utils
Task is a plugin with parameters, in other words task bind plugin with parameters to project:
$ sparrow task add utils nano-rc nano-setup
$ sparrow task ini utils nano-rc
tabsize 2
Now let's run our task:
$ sparrow task run utils nano-rc
<nano-rc>
/ started
rc file generated from template
rc file updated
ok scenario succeeded
ok [b] output match 'rc file generated from template'
ok [b] output match 'rc file updated'
STATUS SUCCEED
You can even override task parameters via command line:
$ sparrow task run utils nano-rc --param tabsize=4
A task initialization process could be the same if we want to reuse not only scripts but configuration. Every time I ssh on new server I want to apply the same nano.rc as it good for me. Here are remote sparrow tasks:
$ sparrow remote task upload utils/nano-rc 'my nano.rc setup'
task updated
task ini data updated OK
I have just uploaded a nano-rc task and it's configuration to my SparrowHub account. Now having this I could ssh to another server and re-apply my task:
$ ssh some-server
$ sparrow remote task run utils/nano-rc
task meta data saved to /home/vagrant/sparrow/cache/meta/utils/nano-rc.json ...
public@nano-setup is uptodate (0.1.0)
project utils already exists - nothing to do here ...
task utils/nano-rc already exists, update task parameters
task - set plugin to public@nano-setup
task utils/nano-rc successfully created
loaded test suite ini from /home/vagrant/sparrow/cache/meta/utils/nano-rc.ini OK
<nano-rc>
/ started
rc file generated from template
rc file updated
ok scenario succeeded
ok [b] output match 'rc file generated from template'
ok [b] output match 'rc file updated'
STATUS SUCCEED
Pretty handy, huh?
Once remote task gets run for the first time , later you can run it as local sparrow task :
$ sparrow task run utils nano-rc
Ok, if I find my task quite common I even can share it with others:
$ sparrow remote task share utils/nano-rc
task nano-rc shared OK
now everyone could see it!
Everyone now can run my task:
$ sparrow remote task run melezhik@utils/nano-rc
The list of available remote tasks could be fetched like this:
$ sparrow remote task public-list
2016-10-24 12:59:06 melezhik@packages/toplist | install my favorite packages
2016-10-24 12:58:22 melezhik@utils/nano-rc | my nano.rc setup
The list of private remote tasks related to your account is taken as:
$ sparrow remote task list
You may take other actions on your remote tasks:
$ sparrow remote task hide app/secure # to hide task from others ( make it private )
$ sparrow remote task remove app/secure # to remove task
Follow sparrow docs on remote tasks API. Or create useful task and share with others!
At the end of my post is a simple but illuminative example of remote task to install my favorite packages:
$ sparrow project create packages
$ sparrow task add packages toplist package-generic
$ sparrow task ini packages toplist
list nano mc ncdu telnet tree
$ sparrow remote task upload packages/toplist 'installs my favorite packages'
Regards
Alexey Melezhik
]]>Perl/Bash scripts gives me a lot of results.
As developers we more think about modules and libraries when talk about software reuse. But in our day-to-day life scripts still take a vital part. Scripts like little, but useful commands to get our job done. This is why people from many programming languages/environments tend to create a places for such a tools called repositories, so other could easily find, install and run scripts or utilities. To list a few:
Well. A SparrowHub is a attempt to make a such effort in Perl communities to create a repository of useful automation scripts. Sparrow is Perl friendly in many ways:
Well let me now turn to the essential point of my post.
I know there are a plenty of cool software written by Perl community we know as CPAN, and many, many Perl modules get shipped with some useful scripts, even more some module's are only public interface - some command line scripts. So why not to upload such a script into a repository so other could use it? I know not all the cases are good fit, but let me outline some criteria if your script could be a good candidate to be uploaded as sparrow plugin:
you have some command line tools based on existed Perl/CPAN/Bash scripts and want to share it somehow with others or even keep it for yourself so to repeat script installation / execution process in the same way every time you setup a new server.
script takes a lot of input parameters or parameters with the structure is hard to be expressed in command line manner ( Hashes, Lists, Groups, so on ).
you need to add some middle-ware steps to your script logic , but don't want to add this into scripts source code.
you need to build a more complex tool based on your low level script/utility.
script possibly gets run often and / or on multiple servers.
script requires some extra checks so one could run it safely.
script is a generic tool acting differently depending on input parameters.
So if this sounds like about your scripts, you may start playing with SparrowHub. After all it's just distribution platform, having minimal impact at your script code:
If this sounds interesting there are simple `how to contribute' steps:
In case you still have a questions or need help on converting your scripts into sparrow plugin, please:
Finally, if you feel like you have no time to dive into new things and study docs, but you are still interested in the subject, just let me know ( creating an issue at sparrow/github ) about script you wish add sparrowhub to and I will try to do it soon.
Regards.
Alexey Melezhik
]]>On my production server I use Minion to send emails to my clients. For some reasons there are faults on executing minion tasks or even minion workers get stopped sometimes for reasons unknown. As sending emails is a vital part of the service registration system I need to know if everything goes bad with my email system. Here is minon-check sparrow plugin to risqué.
$ cpanm Sparrow
$ sparrow index update # get latest plugins index from Sparrowhub
$ sparrow plg install minion-check # install plugin
$ sparrow project create webapp # create a projects to hold web applications tasks
$ sparrow task add webapp minion-health minion-check # this is
# minion health task which is "tied" to minion-check plugin
$ EDITOR=nano sparrow task ini webapp minion-health # set task parameters.
# on my server this will be:
# I use carton install, so:
command = cd /path/to/your/mojo/app && carton exec ./app.pl minion
# sets worker footprint to lookup at processes list
worker_cmd = minion worker
A few comments on plugin setup here:
A command parameter define a system command to handle your minion jobs/tasks , An app.pl is Mojolicious application to run my web application, so I set my minion command as mojolicious command.
A worker_cmd parameter is just a string to look up inside a process list, to identify that minion worker is alive. A simple stings minion worker works for me.
Let's run a task and see the output:
$ sparrow task run webapp minion-health
<minion-tasks>
/modules/check-worker/ started
look up {{{minion worker}}} at proccess list ...
web-app 2748 0.3 3.4 202704 35216 pts/0 S 23:17 0:00 perl ./app.pl minion worker -m production -I 15 -j 2
done
ok scenario succeeded
ok output match 'done'
/modules/last-task/ started
Q=0
ok scenario succeeded
ok output match /Q=(1|0)/
/ started
no failed tasks found
ok 0 failed jobs found
STATUS SUCCEED
So what sparrow plugin minion-check does?
check if your minion worker(s) is running.
check if you have no tasks marked as FAILED for the given period of time. ( I do not set it up explicitly here, but for default it uses 10 minutes interval , for details follow minion-check documentation ).
Finally I setup cron job to run a sparrow plugin every 10 minutes:
$ sparrow task run webapp minion-health --cron
A --cron flag makes sparrow client silent unless any errors happen during execution.
Regards.
Alexey Melezhik
]]>