Converting Complex SVN Repositories to Git - Part 4
Cleaning up and simplifying merges
After the previous steps, the git repository has an accurate history of what was done to the SVN repository. It is a direct translation though, and shows more the process and tools that were used, rather than developer intent. I proceeded to simplify how the merges were recorded to eliminate the convoluted mess that existed and make the history usable.
Two main classes of these problems existed. There were branches were merged one commit at a time, as that was one way of preserving the history in SVN. The other case was trunk being merged into a branch, and immediately merging that back into trunk. Some other issues match up with those two merge styles and the same cleanup will apply to them.
Here is a section of the history of the 'DBIx-Class-resultset' branch being merged, one commit at a time. Obviously not ideal, but you can mostly tell what is happening.
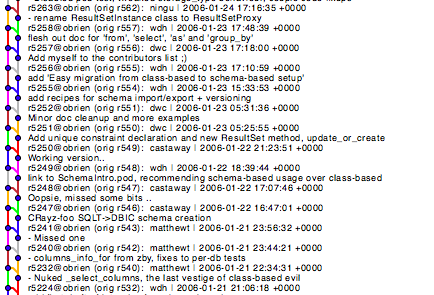
The merge of the 'DBIx-Class-current' branch was somewhat less straightforward.

...

...

This smaller example of the 'resultset_cleanup' branch helps show how these can be dealt with.
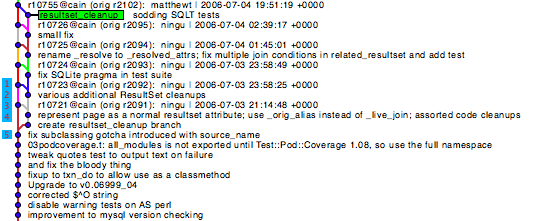
If we search for merges, starting from the earliest point in the repository history, we will find the commit noted as 4. We don't want to remove the record of this branch being merged, so initially we will leave it alone. The next merge we find however, 1, makes the first redundant. There is no need to maintain the first merge now that we know that this one exists. This process continues forward, eventually resulting in a single merge commit for the branch.
The code for this is in 43.graft-merges-simplified.
# get a list of all of the merge commits and their parent commits, space separated
my @merges = `git log --all --merges --pretty=format:'%H %P'`;
# to record all of the commits we intend to alter
my %altered;
# to record all of the merges we've seen so far
my %merges;
# start at the earliest point
for my $merge ( reverse @merges ) {
chomp $merge;
my ($commit, @parents) = split / /, $merge;
$merges{$commit} = \@parents;
# checking our merge [1]
# this repo only contains merges with two parents
my ( $left_parent, $right_parent ) = @parents;
# check if our first parent [3] is a merge
if ( my $left_grandparents = $merges{ $left_parent } ) {
# find the grandparent [4] on the opposite side of the merge [2]
my $right_grandparent
= `git show -s --pretty='format:%P' $right_parent | cut -d' ' -f1`;
chomp $right_grandparent;
# if it is the same as the grandparent ([4] again) on the left side
if ($right_grandparent eq $left_grandparents->[1]) {
# we know we want to simplify this merge
$altered{$commit}++;
# switch the left parent (was [2]) to the left grandparent [5]
$parents[0] = $left_grandparents->[0];
# our left parent shouldn't be part of the history anymore,
# so we don't want to match it
delete $merges{ $left_parent };
# nor do we need to change it
delete $altered{ $left_parent };
}
}
}
# many of these merges exist only because they were calculated in previous steps
# we don't want duplicate grafts, so we simple comment out the old ones.
my $regex = '(?:' . (join '|', keys %altered) . ')';
system "perl -i -pe's/^($regex )/# \$1/' $GIT_DIR/info/grafts";
# record the grafts
open my $fh, '>>', "$GIT_DIR/info/grafts";
print { $fh } "# Simplified merges\n";
for my $commit ( keys %altered ) {
print { $fh } join(q{ }, $commit, @{ $merges{$commit} }) . "\n";
}
close $fh;
# we're modifying these merge commits. whatever their commit
# messages were initially won't be accurate anymore.
# later, when we rewrite the commit messages, we want to just
# record these as branch merges.
# this just keeps track of which commits we want to simplify the
# commit messages in this manner.
use Data::Dumper;
$Data::Dumper::Indent = 1;
$Data::Dumper::Terse = 1;
$Data::Dumper::Sortkeys = 1;
@altered{ keys %$simplified_merges } = values %$simplified_merges;
open $fh, '>', "$BASE_DIR/cache/simplified-merges.pl";
print { $fh } Dumper(\%altered);
close $fh;
The end result is obviously much nicer.
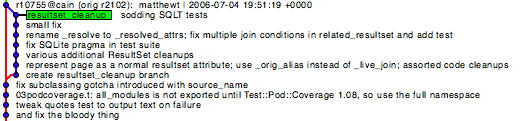
It turned out that while these calculations caught the majority of the cases, a couple complex, ugly cases were missed. The 'DBIx-Class-current' case was one of these. Rather than spend the extra effort to find an additional strategy to automatically detect such cases (if it was even possible), I manually figured out the best way to record the merges and put them in the 42.graft-merges-simplified-manual file.
Here we see a merge into a branch, followed immediately by a merge into trunk.

Another case that makes the history harder to follow. And while this example is relatively straightforward, cleaning up this type of merge helps in much uglier cases as well. The process for simplifying these merges may eliminate the commits our branches are referring to, but we don't have any need to maintain the branches that have been merged, so we delete them here (46.delete-merged-branches, the same script as 60.delete-merged-branches).
The 47.graft-merges-redundant script simplifies these. It follows a similar structure to the previous simplification script.
my @merges = `git log --all --merges --pretty=format:'%H %P'`;
my %altered;
my %merges;
for my $merge ( reverse @merges ) {
chomp $merge;
my ($commit, @parents) = split / /, $merge;
my $f;
# for each merge [1]
$merges{$commit} = \@parents;
# check each parent [2] in turn ([3] will be checked first, but fail
# a later test)
PARENT: for my $p ( 0 .. 1 ) {
my $parent = $parents[ $p ];
# check against the other parent [3]
my $check_ancest = $parents[ 1 - $p ];
# we only care if it is merge
my $ancest = $merges{ $check_ancest } || next;
ANCEST: for my $c ( 0 .. 1 ) {
# if the first parent [3] is also a parent of the second parent [2]
if ($parent eq $ancest->[ $c ]) {
$altered{$commit}++;
# we don't need the current second parent [2], so switch
# it to that commit's other parent [4]
$parents[1 - $p] = $ancest->[1 - $c];
# don't match or change the commit we are clipping out
delete $merges{ $check_ancest };
delete $altered{ $check_ancest };
# and skip to the next commit
last PARENT;
}
}
}
}
The redundant merge is now gone.

The history simplification is now basically complete. Instead of the convoluted mess that resulted from a direct translation of the SVN repository, it now has a mostly understandable history showing what the developers intended, rather that the exact method they used to do so. All that is left to do is clean up the commit messages and attribution, fix the tags, and a few other minor cleanups.
Next: Commit message and other final cleanups, and baking in grafts
