Threaded Forum SQL
I previously wrote about threaded forums and threatened to share some code with you. Basically, I want to get this in a single SQL call:
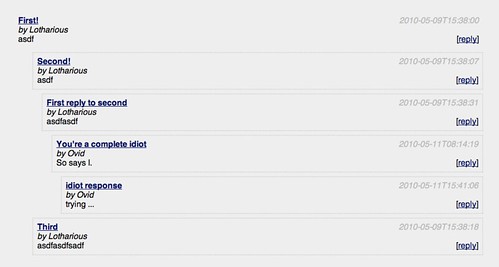
As it turns out, a lot of people want to get that in a single SQL call and some of the answers seem fairly complicated. I can't say my answer is necessarily the best one (and there are some caveats to it), but compare my stored procedure to the one in the previous link.
First, I assume that each post has a parent post and the root post should point to itself as the parent.
Then, each post should have a materialized path (and a tip of the pen to Matt Trout for describing them to me). A materialized path is simply the path to the current node, formed by concatenating parent ids with a separator. For example, if post 3's parent is post 2 and its parent is post 1 and that's the root path, post 3's materialized path might be 1.2.3. Then, to fetch a post (post 1 in this example) and all children, the SQL is simply:
SELECT * FROM posts WHERE id = 1 OR matpath LIKE '1.%';
However, this doesn't allow us to properly order our posts. When people post replies higher up a tree, it's very easy to get the posts returned in the wrong order. To handle this, I've added a 'sortpath' field. Since I automatically have a 'created' column, I can use dates and ids (the dates get me my sorting, but I append an ID to guarantee a deterministic sort order in case two posts come in at the same time). I then append the current created date (resolved to seconds) and the id to the parent sort path. I've chosen to do this with a PostgreSQL stored procedure. It looks like this:
CREATE OR REPLACE FUNCTION post_sortpath() RETURNS TRIGGER AS $BODY$
DECLARE
new_sortpath text;
parent_post forum_post%ROWTYPE;
BEGIN
new_sortpath = date_trunc('second', NEW.created) || '-' || NEW.id;
IF NEW.parent_id IS NULL THEN
NEW.parent_id := NEW.id;
NEW.matpath := NEW.id;
NEW.sortpath := new_sortpath;
ELSE
SELECT * INTO parent_post FROM forum_post WHERE id = NEW.parent_id;
NEW.matpath := parent_post.matpath || '.' || NEW.id;
NEW.sortpath := parent_post.sortpath || '.' || new_sortpath;
END IF;
RETURN NEW;
END;
$BODY$ LANGUAGE 'plpgsql';
CREATE TRIGGER post_sortpath BEFORE INSERT ON forum_post
FOR EACH ROW EXECUTE PROCEDURE post_sortpath();
My DBIx::Class code to get replies for a given post now looks like this:
sub replies {
my $self = shift;
return $self->result_source->schema->resultset('ForumPost')->search(
{
topic_id => $self->topic_id,
matpath => { like => $self->matpath.".%" },
},
{ order_by => 'sortpath' }
);
}
(Note that the topic id is not strictly necessary, but if there's an index on that, it should filter forum posts much faster than the LIKE will).
There are a couple of caveats with this. Deeply nested replies will create a huge sortpath, so switching to a shorter implementation might be good. Also, because I populate this via a stored procedure, it means that every time I create a post, if I need this immediately I need to call $post->discard_changes to reload this from the database. However, it's not needed in my app, so that's not an issue. Your mileage may vary.
Another benefit of moving this from the database into your code (using DBIx::Class, you'd override the insert() method) is that you move load from the database to the application. Generally I would discourage this because it would be possible for rogue code to insert bad data. However, profiling database applications is always tricky and if you need to shift load from the server to the app, this might be one of those areas (for low-use forums, this is probably a very bad optimization).
Update: Peter Rabbitson pointed out to me that github has a DBIx::Class example of this being done in a single column. It's at DBIx::Class::Tree::Recursive, but the actual package is DBIx::Class::Tree::Ordered::MatPath. I think my implementation could also use a single column, but you'd want to get the sortpath column to have much shorter sort values rather than $date-$id for each segment.
 Freelance Perl/Testing/Agile consultant and trainer. See http://www.allaroundtheworld.fr/ for our services. If you have a problem with Perl, we will solve it for you.
And don't forget to buy my book! http://www.amazon.com/Beginning-Perl-Curtis-Poe/dp/1118013840/
Freelance Perl/Testing/Agile consultant and trainer. See http://www.allaroundtheworld.fr/ for our services. If you have a problem with Perl, we will solve it for you.
And don't forget to buy my book! http://www.amazon.com/Beginning-Perl-Curtis-Poe/dp/1118013840/
I wonder if you can't solve this better with a nested set:
http://dev.mysql.com/tech-resources/articles/hierarchical-data.html
The URL is a mysql.com site, but the solution works everywhere. And there is a DBIC module for it too.
I meant to mention this to you before, but I forgot. I solved this problem years ago, and it may or may not be interesting to you now. In WebGUI we use a special kind of matpath called "lineage". It basically works like this:
Each node in the lineage is made up of a six digit number. If the number is not 6 digits it's prepadded with zeros. Each of these nodes is called a "rank". Since the rank is fixed width we have no need for a separator character, and we can also use it to order our result set.
The first post would have a lineage of:
000001
The second would be:
000002
And a reply to to the first would be:
000001000001
And a reply to that would be:
000001000001000001
And pretty soon you end up with:
000001 000002 000001000001 000001000001000001 000002000001 000001000002 000001000002000001 and so on.
So now I can get the original post and the replies in order if I want simply by saying:
select * from post where lineage like '000001%' order by lineage;
And a single indexed column provides a speedy response.
This does have a limitation in that you can only have 999,999 direct replies to a post or replies to a reply, but that is an acceptable limitation for us.
And with lineage if I know that my current node is 000001000047000006, then I also know that it's parent's lineage is 000001000047, it's grand parent's lineage is 000001, and that it's descendants will all start with 000001000047000006, just like a material path.
See Depesz's take on trees for a really nice tree graph solution in PostgreSQL.
@Pedro: frankly, I didn't like the complexity of the queries for nested sets. Plus, they're reputed to be slow for adding and deleted nodes -- that's not a good thing for me :)
@David: Tomas Doran sent that to me a while ago. I like it, but it seemed liked overkill for me. I'm not going to be moving or deleting any node entries. A "deleted" entry will have its text cleared but still remain in the heirarchy so that a semblance of context is preserved (I can't just drop one lest a reply appears to be replying to the wrong thing).
@JT: just to make sure I understand, the lineage for, say, the fourth reply to the first reply of the second post would be 000004000001000002? If so, that would also solve things nicely. I can still play around with my implementation and I don't think I'd be losing any information this way.
Traditional nested sets require updating half the nodes in the tree on average. You can partition the tree into a forest by another key though – in your case, each thread would be a separate tree. Then you need to update half the nodes of half an average-sized thread, on average (roughly).
That’s not ideal, but it’s not terrible.
Nested set forests like this are very fast to query, though. You simply ask for all rows with the right thread ID, ordered by left-edge value – and that’s it. It’s about as trivial as it gets (which benefits not only performance but also DBMS portability). And it’s very easy to thread the result set.
So it depends on your traffic. If you have relatively heavy write traffic on large trees, then nested sets are going to be suboptimal. If you have many small trees and a significant bias toward read traffic, then nested sets are a better bargain. I think a forum is usually going to fall in that category.
(I know that the board of the User Friendly comic uses nested set forests, f.ex.)
@Aristotle: by why is the proposed solution suboptimal? The query is ridiculously simple and easy to understand. It should also be very fast. If I go with the "lineage" solution mentioned by JT, it would be even simpler and faster.
@Ovid, close but just the reverse. The first element shows the "root" node, and so on. So it would be 000002000001000004. You're always tacking the next rank on the right, that way your "order by" clause is just "order by lineage". If you need any help feel free to contact me. I think you have my email addy, but in case you don't jt at plainblack dot com.
@Aristotle, nested sets are actually a terrible way to go if you have lots of data. We used them for a while in WebGUI, and they were SLOW, because of all the extra writing you have to do as the tree changes.
I gather you've seen Joe Celko's (of "SQL for Smarties" fame) article about his method to represent hierarchies in SQL?
He even made a book out of it.
It's an interesting approach, though I would never go as far as ordering the whole forum using only this approach; instead, I'd give each thread a sequence number, and use this L/R "nested sets" approach only for inside each thread.
The problem with nested sets is writing to the database. The ENTIRE tree has to be updated on every change. It's really useful for read heavy databases, but for writing, it can be rather a pain in the ass. Even matpath can be a pain in the ass, as it requires two writes for every read. I found a Postgres solution using WITH RECURSIVE, but it's a long ways off from me being able to implement it using DBIC.