CHI Saves The Day
The Server Is Down
- No it isn't, I didn't get paged.
- Wait a minute, why didn't I get paged?
- FUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUU--
- CHALLENGE ACCEPTED
Diagnosis
The client reported that the site sometimes took more than a minute to load. Doesn't respond very slowly to me, and the pager is only primed to ping me if there is a sustained downtime (hiccups are not something I want to wake up for every night at 3:00am).
Strangely, load hovered around 7 most of the time, only spiking to 13 every few minutes. With a 16-core processor, this was well within operating parameters, if just a little worrisome. Nothing in the log files.
Oops, now I get a slow page load. Takes 30 seconds to load a page. Refresh again, and the page loads just fine. Clear browser cache, and the page still loads just fine.
top kept MySQL at the top of the CPU list. Not surprising, as this server is the master database server for a two node cluster. So I keep an eye on top as I poll mysql for its process list.
A pattern emerges: The load spikes and server goes unresponsive when this happens:
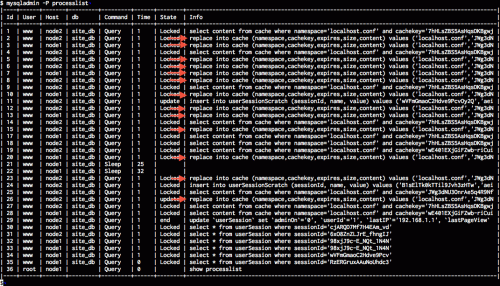
This table shows 12 different processes are trying to update the same cache location (process ID 2-3, 5-8, 10, 12-13, 18, 23, and 26). Because of MyISAM's table-level lock, any request to get from the cache has to wait for 12 REPLACE INTO requests to complete. They've already taken 1 second, if each replace takes 2 seconds, that's 24 seconds of non-responsive website.
These 12 processes all saw that the cache item had expired and are trying to update it. This is called a "cache stampede". Only one of them needs to update the cache, the rest are just wasting resources. Worse, they're doing all the work to update the cache, which is much more expensive than getting the value from the cache. If it's expensive enough, the site goes down hard.
Management
How can we stop the cache stampede? One way is to mildly randomize the actual expiration date when checking if the cache is expired:
sub is_expired {
my ( $self, $key ) = @_;
my $expires = $self->get_expires( $key );
# Randomize the expiration by up to 5% +/-
# by first removing 5% and then adding 0-10%
$expires = $expires - ( $expires * 0.05 ) + ( $expires * 0.10 * rand );
# Compare against now
return $expires > time;
}
In this very simple case, if you are within 5% of the expiration time, you have a chance to have an expired cache item. The chance grows as time passes, reaching 50% at the actual expiration time, and 100% at 5% past the expiration time.
Rather than add this expiration variance to our custom database cache, I instead opted to move this site over to CHI, which has this protection built-in.
my $cache = CHI->new(
driver => 'DBI',
namespace => 'localhost',
dbh => $dbh,
expires_variance => '0.10',
);
This stops the cache stampede, but we're still hitting the database a lot. Remember we have two web nodes hitting one database node. The fewer database hits we make, the better performance we can get without having to ask for more hardware from the client (which takes time, and forms, and more forms, and meetings, and forms, and more meetings, and probably some forms).
Because this is a distributed system, we need a distributed, synchronized cache. We cannot use memcached, as WebGUI 7.x does not support it (but WebGUI 8 does). So for now we must use the database as our synchronized cache, but what if we put a faster, local cache in front of the slower, synchronized cache?
CHI has an awesome way to do this: Add an l1_cache
my $cache = CHI->new(
driver => 'DBI',
namespace => 'localhost',
dbh => $dbh,
expires_variance => '0.10',
l1_cache => {
driver => 'FastMmap',
root_dir => '/tmp/cache',
},
);
Now we're using FastMmap to share an in-memory cache between our web processes, and if the L1 cache is expired or missing, we look for content from the DBI cache. If that cache is missing or expired, we have a cache miss and have to recompute the value.
Hurdles
I had to install the DB tables myself, which was not difficult, just undocumented (bug report filed). MySQL only allows a 1000-byte key, and the CHI::Driver::DBI tries to create a 600-character key. This is fine in the Latin-1 charset, but MySQL complains if you're using UTF-8 by default.
The driver also tries to create a TEXT field to hold the cache value, but MySQL expects a text field to hold characters in a known character set. After noticing that my cache values were empty, I changed to a LONGBLOB.
The full create table statements are below:
-- primary cache table: chi_<namespace> --
CREATE TABLE IF NOT EXISTS `chi_localhost` (
`key` VARCHAR(255),
`value` LONGBLOB,
PRIMARY KEY ( `key` )
);
-- CHI metacache table --
CREATE TABLE IF NOT EXISTS `chi__CHI_METACACHE` (
`key` VARCHAR(255),
`value` LONGBLOB,
PRIMARY KEY ( `key` )
);
Results
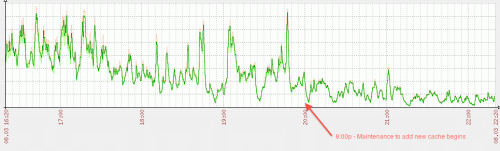
The server is stable again! Spikes do not turn into out-of-control loads and unresponsive server. We'll see how things go tomorrow during normal business hours (the peak time for this site), but right now it looks like CHI has saved the day!
Which storage engine are you using for your cache? InnoDB? You're paying a lot of overhead on each cache update if so (but you can't use memory due to the blob).
Also, if each replace takes 2s, is read access blocked while the replace is in progress?
We're using MyISAM, which has table-level locks. A write lock prevents all reading from the entire table.
Now that the emergency is over, we're looking into writing a CHI driver for HandlerSocket, which bypasses the MySQL query parser and just does direct key lookups at much faster speeds.
InnoDB wouldn't solve all my problems, but it would solve a couple I suspect. WebGUI 8 is InnoDB, we're currently looking at if it's possible in WebGUI 7 to move all the non-fulltext tables to InnoDB, along with other solutions like HandlerSocket, but these are more intense solutions. The CHI solution above took me no more than 30 minutes to hammer out.