Performance hacks
http://corehackers.perl.org/wiki/index.php5?title=Main_Page#Performance_Hacks lists some perl5 Performance hacks.
Most ideas are from me.
There's another Raw Array idea from Leon, for which I wrote Tie::CArray ages ago, but this can be made better of course. Tie::CArray does not need to do its own memory management.
That's what we have magic for. The array of I32/U32/NV/char[12]/.. can reside in the PVX and the getters/setters/... are just magic callbacks as in Tie::Array.
I just talked about some obvious illguts observations at the vienna perl workshop and was asked to eloborate.
Leave off xpv* structs
If you don't need any xpv struct, e.g. for short strings, you can leave it off. This will need a flag bit and can be set if MAGIC and STASH is empty.
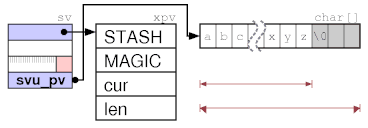
http://cpansearch.perl.org/src/RURBAN/illguts-0.35/index.html#svpv
CUR calls run-time strlen(PVX) then, not a lookup into ANY->CUR, so this will win only for short strings, where strlen is not needed that often. LEN is handled by malloc in the libc and not needed for the API.
Faster simple IV, NV. IVX == sv_u.svu_iv
Put the IV or NV value into the first struct at the sv_u (4th slot), and add additional xiv structs only if upgraded to PVIV/PVNV, and magic and stash are not empty.
old: #define SvIVX(sv) SvANY(sv)->xiv_iv new: #define SvIVX(sv) (SvTYPE(sv) & SVt_IV) && (SvFLAGS(sv) & SViv_simple) \ ? sv->sv_u.svu_iv \ : SvANY(sv)->xiv_iv
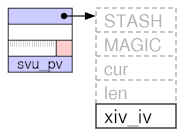
http://cpansearch.perl.org/src/RURBAN/illguts-0.35/index.html#sviv
Better Parser
Everyone looking at -MO=Concise vs -M=Concise,-exec observes how the perl parser creates the ops and sees that they are rather reversed in the run-time runloop, a linearization upfront would help the CPU prefetching the next ops radically.
Now the runloop is a ZigZag through our optree.
Note that a parser is recursive by nature, and a parse tree also. But the parse tree can be optimized and omitted in linear order easily with a parser rewrite.
Gerard Goossen already wrote it, but I haven't checked how linear the output is. Nobody at p5p seems the see the advantage of the new parser.
Jit
My unfinished Jit module is based on two ideas.
1. Linearize the ZigZag to consecutive op->next chains (plus local
op->other jumps) within the chain. See above, I just need memory for the assembled op chain.
2. Get rid of call far when calling the pp_ ops. Esp. if libperl is shared, the linker creates far calls, which stops the CPU code prefetching at all. Within Jit I caclulate the offset from my mprotected malloced area to the op in libperl.so and create much faster near calls by offset if possible.
Drawbacks:
More memory, slower compile-time (2 pass jit).
First Jit benchmark data:
benchtest - simple arithmetic in 24K$ make OPTIMIZE="-O3 -DPROFILING" && perl t/bench.pl $ perl -Mblib -MJit benchtest.pl jit pass 1: 0.000000015832 - calc size jit pass 2: 0.001000015764 - emit asm jit runloop: 0.000000088243 - run jitted loop vs. -jit runloop: 0.002000088338 - run unjitted loop
The real bottleneck are overblown pp ops, which discrimenate at run-time on the arg types. E.g. Lorita is trying to overcome this at parrot, but they are already having types.
This can be optimized for perl5 we get better types at compile-time to simplier and faster ops. And with Jit even on run-time.
use types; is the idea.
Add auxilliary structs to the head, no SvANY, faster run-time access
If all the auxiliary xpv structs are consecutive in memory after the fixed 4-byte head, we can get much easier and faster slot accessors. We can get rid of SvANY at all.
The drawback are upgrades, type changes, but they are slow already and do the neccessary reallocs already.
Drawback: sv alignment, different sizes. But I wonder how the CPU caching benefits at all from our current 4-byte sv_head alignment.
 Working at cPanel on cperl, B::C (the perl-compiler), parrot, B::Generate, cygwin perl and more guts, keeping the system alive.
Working at cPanel on cperl, B::C (the perl-compiler), parrot, B::Generate, cygwin perl and more guts, keeping the system alive.
Yeah, I should get back to my Raw Array patch, it has bitrotted a bit in the past year. It has some tricky edge cases, but it has a lot of potential to make modules like Tie::CArray and Judy a lot faster.