Perl QA Hackathon 2015
Last post - the post that hurts the most.
It's been a while that I blogged. Yet, it's a tradition now to write my report about the Perl QA hackathon as probably the last one of the attendees. The 2015 edition of the Perl QA hackathon was a lot of fun. I'm one of the less visible guys there so I want to give some visibility into my work.
My topic is benchmarking.
Benchmarking the Perl 5 interpreter.
Over the years, I narrowed down that topic beginning with the problem statement over several steps: the search for workloads, the creation of a framework for executing and producing meaningful numbers, the bootstrapping of Perl with CPAN, ensuring a stable CPAN, a system to store benchmarks together with general testing results, and the actual execution on dedicated hardware.
You can recapitulate some intermediate steps here:
Perl Workloads - YAPC::Europe 2010
Perl::Formance - YAPC::Europe 2011
Perl::Formance / numbers - YAPC::Europe 2012
With the 3 projects that hold my overall vision together being those:
bootstrap-perl
Perl::Formance
Tapper
This year I tried hard to spend my time on actual result generation.
From the 1st hackathon day I had set up my bootstrapping and quick sample benchmarking to ensure I can generate results. This basically ran continuously during the 4 days on all released major Perl versions since 5.8.9/5.10 to 5.20.2
I gradually increased the amount of meta information, polished CPAN bootstrapping on distroprefs and dependencies, resurrected Spam Assassin as interesting macro workload, finished some more benchmark plugins (matrix multiply, 5.20 function signature).
Unfortunately I didn't have a release of our scalable test infrastructure Tapper with its dedicated benchmarking subsystem ready by the hackathon start, so I just worked with local result files. However, I reworked the data schema to already prepare for the later n-dimensional evaluation of results, and concentrated on 4 dimensions for now: Perl release version, 64bit on/off, threading on/off, and the different workloads.
I integrated PDL::Stats to improve data confidence by simple repetition, and have aggregated values at hand. Although I concentrated on the simple mean when I then charted it using google's chart api we can do a more thorough evaluation later.
When I left the train at home I had all parts finished, yet with only the quick runs to proof the overall approach:
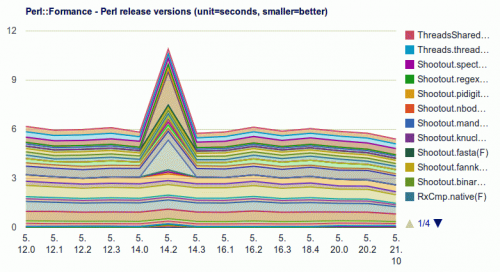
The actual benchmarks are much longer running for a couple of days now.
Stay tuned for the actual charts any time soon...
Leave a comment