blead Breaks CPAN a.k.a. BBC
Next week I will take part of the toolchain summit 2018 in Oslo, Norway.
This would be my second participation after last year event in Lyon, France, where I mainly focus on grep.metacpan.org prototype.
One recurring discussion during the last Perl events brought by kid51 is to improve detection of BBC - blead breaks CPAN. (note: blead is the branch tracking current perl development)
You can read more from kid51 on these topics here:
- What do we want and need for teting
- Do We Need a Tertiary Test Suite?
I think that we already have a lot of tools, matrix, smokers... in place. I've no intentions at this point to provide an extra smoking service. But I mainly struggle to get the vision I would like for these data.... It's a challenge to represent multidimensional data on a single webpage.
By gathering the data from matrix.cpantesters.org I think we could provide an easy way to see the state of the "CPAN River" across perl version
Here is a simple draft that could considerably evolve with ideas coming from you, the community over the next days.
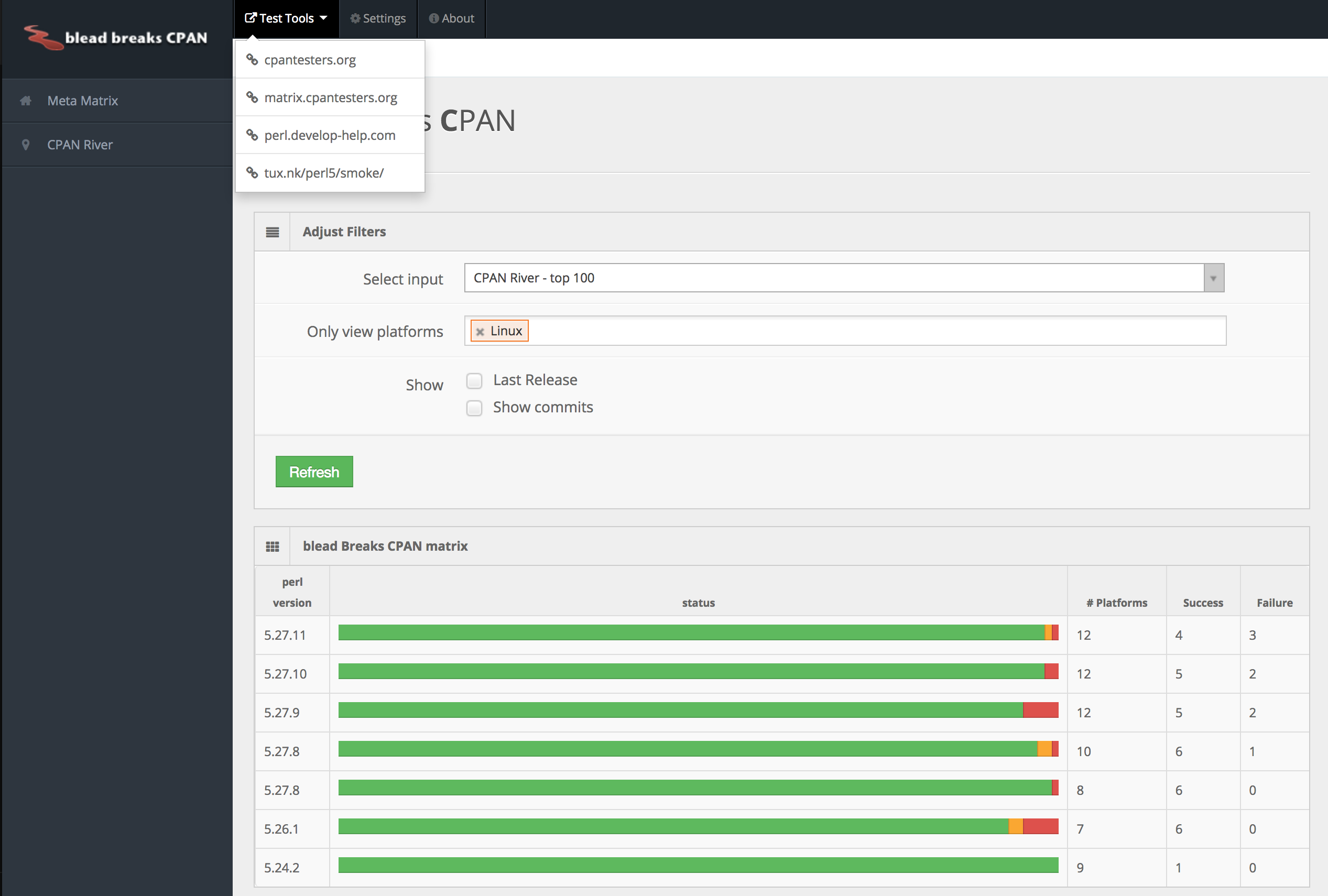
This project is not live at this point, but this is the first step. Feedbacks and Ideas are appreciated.
Note: "CPAN River" is a term which refers to the CPAN landscape and the idea that some modules are more used/common than others. Once you sort them by most used this gives a visual representation which looks like a "river".
More than one method exists to compute it, but you can have a look at, read this discussion here
A special thanks to all sponsors making this event possible:
NUUG Foundation, Booking.com, cPanel, FastMail, MaxMind, MongoDB, SureVoIP, Campus Explorer, Bytemark, Infinity Interactive, OpusVL, Eligo, Perl Services, Oetiker+Partner.
 I blog about Perl.
I blog about Perl.
Leave a comment