CY's Post on PWC#064 - my shortcomings
Task 1:
A runner has to run from the upper-left corner to the lower-right corner in a race. The stadium of this race is rectangular, and each square meter area has different level of difficulty (caused by sand, cement, grass, slope...). Our runner has to choose a path with the least difficulty to complete the race.
My description makes it look like something from a competitive programming problem. Maybe someone will discover sometimes I made sentimental names in the codes. (I was a long-distance runner in high school and university, by the way.)
The heart of my solution for this task is:
my $steps = $_[0];
my $hardship = $_[1];
if ( (length $steps) < $totsteps ) {
go($steps.'D', $hardship) if $M-1 > otimes($steps, 'D');
go($steps.'R', $hardship) if $N-1 > otimes($steps, 'R');
}
elsif ( $hardship <= $refmin) {
@min_path = tour($steps);
$refmin = $hardship;
}
}
where $totsteps = m+n-2.
Enumeration.
Task 2: Learn again from others' codes.
There are two topics I would like to share:
Code Performance
Tonight I look on the GitHub code base. Most PWCers have made use of regular expressions. It seems that I am the only PWCer make use of libaries of combinations and permutations. My code also have the worst performance. 😖
my $subject = Math::Combinatorics->new( count => $r , data => [@W] );
while (my @tsum = $subject->next_combination) {
if ($target == sum map {length $_} @tsum) {
my $psubject = Math::Combinatorics->new( count => $r, data => [@tsum]);
while (my @ptsum = $psubject->next_permutation) {
if ( $S eq (join "", @ptsum)) {
print "\"";
print join "\",\"", @ptsum;
print "\"\n";
$noofsoln++;
exit;
}
}
}
}
}
It seems that the main reason is: others apply "divide and conquer".
thequickbrownfoxjumpsoverthelazydogwoo is used as string input and the words input are theq,uickb,rownf,ox,jumps,over,the,lazy,dog,woo (total 10 words).
Mr Roger Bell_West has made use of index (do allow me to link his blogpost: Perl Weekly Challenge 64: summing paths and breaking words, one of keywords is "FIFO" )
$ time perl RBW_ch-2.pl
"theq", "uickb", "rownf", "ox", "jumps", "over", "the", "lazy", "dog", "woo"
real 0m0.008s
user 0m0.004s
sys 0m0.004s
(I ran it many times its performance is quite stable that it usually spends around 0.007~0.009 seconds.)
Mr Bartosz has made use of substr:
(do allow me to link his blogpost: Perl Weekly Challenge 64 solution)
$ time perl brtastic_ch-2.pl
"theq", "uickb", "rownf", "ox", "jumps", "over", "the", "lazy", "dog", "woo"
real 0m0.003s
user 0m0.003s
sys 0m0.000s
(I ran it many times its performance is very stable that it always spends 0.003~0.004 seconds.)
Mr E. Choroba has made use of grep and substr:
$ time perl choroba_ch-2.pl
thequickbrownfoxjumpsoverthelazydogwoo
real 0m0.006s
user 0m0.003s
sys 0m0.003s
$ time perl choroba_ch-2.pl
thequickbrownfoxjumpsoverthelazydogwoo
real 0m0.007s
user 0m0.007s
sys 0m0.000s
Mr Ulrich Rieke has made use of a segment of regular expression:
$ time perl rieke_ch-2.pl theq,uickb,rownf,ox,jumps,over,the,lazy,dog,woo
real 0m0.007s
user 0m0.007s
sys 0m0.000s
$ time perl rieke_ch-2.pl
theq,uickb,rownf,ox,jumps,over,the,lazy,dog,woo
real 0m0.009s
user 0m0.005s
sys 0m0.004s
My code is slower by an order of magnitude of 103, ooooops :
$ time perl CYF_ch-2_13thJun.pl "theq","uickb","rownf","ox","jumps","over","the","lazy","dog","woo"
real 0m9.345s
user 0m9.328s
sys 0m0.012s
$ time perl CYF_ch-2_13thJun.pl "theq","uickb","rownf","ox","jumps","over","the","lazy","dog","woo"
real 0m16.344s
user 0m16.334s
sys 0m0.000s
$ time perl CYF_ch-2_13thJun.pl "theq","uickb","rownf","ox","jumps","over","the","lazy","dog","woo"
real 0m9.089s
user 0m9.090s
sys 0m0.000s
$ time perl CYF_ch-2_13thJun.pl "theq","uickb","rownf","ox","jumps","over","the","lazy","dog","woo"
real 0m11.447s
user 0m11.437s
sys 0m0.004s
Best Algorithms?
I think of something mathematical. Are there data structures we can make and bring us a fast algorithm?
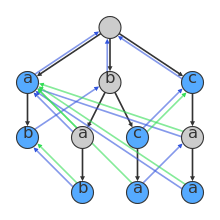
Knuth–Morris–Pratt algorithm is a well-known algorithm for looking for a string within a longer string. From wikipedia, I have been introduced to Aho–Corasick algorithm as a multiple string searching algorithm.
(Image: by wikipedian Dllu, license: CC BY-SA 3.0; description for Aho–Corasick algorithm)
The graph seems complicated and I get no time to study it at this moment.
For more, see Template:Strings - Wikipedia.
* * * * * * * * *
If the word order is irrelevent, it looks close to "Set Packing" problems, stated in The Algorithm Design Manual (by Steven S. Skiena); and the manual says that set packing is NP-complete.
* * * * *
Apart from unsuccessful codes, I am still thinking about a variant of
this task. "Binary strings" comes up to my mind. You know, there are 26
(lowercase) alphabets. Will there be some interesting optimization when
there are 2 alphabets only? How about 3 alphabets?
In short, I mean a task:
Write a script to find out if $S can be split into sequence of one or more words as in the given @W.
Print the all the words if found otherwise print 0.Leave it as an open challenge first.
Again, stay healthy and strong! Looking forward to next week's Weekly Challenge. Time to sleep in my timezone. □
 This blog is inactive and replaced by https://e7-87-83.github.io/coding/blog.html ; but I post highly Perl-related posts here.
This blog is inactive and replaced by https://e7-87-83.github.io/coding/blog.html ; but I post highly Perl-related posts here.
Leave a comment