Cloud Provider Performance Comparison - Perl & more
UPDATE: For the newer (2023) comparison see here.
Recently, I did an evaluation of our Google Cloud setup at work and, after some tests, I noticed that instance types affected performance significantly and sometimes in a way quite different from what you'd expect based on their price. I packaged my benchmarks in a single suite and over the holidays I run them against various GCP types to see where the best performance and/or value is. After that, I got curious and expanded to include more cloud providers and decided to try and make as best a comparison as I could and write it up, both for my own future reference, and for anyone looking for the best performance or value for various workloads. As a bonus, I threw in Geekbench 5 for a non-perl perspective and the laptops I had at home as a comparison basis.
Note that this became quite a long comparison as I found out various things, became curious and had to do more testing etc.
The Contenders
Most of the cloud providers have quite convoluted and unique pricing systems, in general I tried to get on-demand instances with at least 2 vCPUs (to measure scaling), 2GB/CPU, 20GB disk (balanced/SSD), preferably in a US or European region, and priced these for a month of usage, excluding network traffic. For the providers that offer discounted "reserved" instance pricing, I list the (fully prepaid) 1-year reservation cost for comparison.
- Google Compute Engine (GCE)
| Instance Type / Model | vCPU (# threads) / CPU type | GHz | Price $/ Month | Reserved $/ 1 Year |
| e2-medium | 2x Intel | 2.2 | 26.46 | 208.92 |
| e2-s2 (Broadwell) | 2x Broadwell | 2.2 | 44.38 | 329.28 |
| n2d-s2 (Milan) | 2x AMD Milan | 2.45 | 44.78 | 408.96 |
| n2d-s2 (Rome) A | 2x AMD Rome | 2.25 | 44.78 | 408.96 |
| n2d-s2 (Rome) B | 2x AMD Rome | 2.25 | 44.78 | 408.96 |
| n1-s2 (Skylake) | 2x Skylake | 2.0 | 44.99 | 466.44 |
| n2-s2 (Cascade L) | 2x Cascade Lake | 2.8 | 51.15 | 466.44 |
| n2-s2 (ice L) | 2x Ice Lake | 2.6 | 51.15 | 466.44 |
| c2d-s2 (Milan) | 2x AMD Milan | 2.45 | 56.72 | 437.64 |
| t2d-s2 (Milan) | 2x AMD Milan | 2.45 | 63.68* | 490.32 |
| n2d-s4 (Milan) | 4x AMD Milan | 2.45 | 87.56 | 793.80 |
| n2d-s4 (Rome) | 4x AMD Rome | 2.25 | 87.56 | 793.80 |
| c2d-s4 (Milan) | 4x AMD Milan | 2.45 | 111.44 | 851.40 |
| c2-s4 | 4x Cascade Lake | 3.1 | 123.97* | 1176.24 |
| n2d-s8 (Milan) | 8x AMD Milan | 2.45 | 173.12 | 1563.60 |
| n2d-s8 (Rome) | 8x AMD Rome | 2.25 | 173.12 | 1563.60 |
| c2-s8 | 8x Cascade Lake | 3.1 | 245.95* | 2328.60 |
| t2d-s8 (Milan) | 8x AMD Milan | 2.45 | 248.72* | 1889.16 |
*4GB/CPU
**shared/burstable CPU type
**shared/burstable CPU type
The Google Cloud Platform is the 3rd most popular cloud provider, matching most of Amazon Web Services with their own variants.
Like Amazon's EC2, Google's Compute Engine has a multitude of instance types to choose from, and in for an additional complexity, GCE can offer different generation of CPUs for the same instance type depending on the region you choose (at the same price). Fortunately, (apart from the e2 shared instances), you can select what generation CPU you want to spin up, so it does not have to be random - although you have to be careful as some regions may be limited in their options Note that you can't always be sure what to choose, especially for Intel CPUs, as, for example, the newer Ice Lake instances can have a lower clock speed than the previous gen Cascade Lake etc.
Like Amazon's EC2, Google's Compute Engine has a multitude of instance types to choose from, and in for an additional complexity, GCE can offer different generation of CPUs for the same instance type depending on the region you choose (at the same price). Fortunately, (apart from the e2 shared instances), you can select what generation CPU you want to spin up, so it does not have to be random - although you have to be careful as some regions may be limited in their options Note that you can't always be sure what to choose, especially for Intel CPUs, as, for example, the newer Ice Lake instances can have a lower clock speed than the previous gen Cascade Lake etc.
The e2-medium instance is different from all the others, as it is a shared CPU with full speed only for bursts, it will throttle down (to 50%/vCPU according to the docs) after the burst, which will last just 2 minutes at 100% on both vCPUs (proportionally longer if you burst at lower than 100%) - but there will be no more bursting until you drop your usage. For every second of idle then, you get 2 seconds of burst (to the max of 2 minutes).
You will notice that there are more variations per instance type benchmarked than other cloud providers (e.g. 4x, 8x versions). This is mainly because I did start the evaluation just for GCP, as it is our current provider and also because from the first benchmarks, it quickly became apparent that the EPYC Milan (AMD Zen 3 arch) instances could be quite impressive in most tasks, but something about Google's setup is holding them back:
Not all GCP AMD cores are created equal.
In essence, for every EPYC Milan instance it seems like you get 1 core that is slower than the others (so it would be 1 of 2 for the 2-core instance, 1 of 8 for the 8-core instance etc). It was 100% reproducible (and more obvious with specific benchmarks) and since the cores look identical as far as the OS is concerned, your tasks will be randomly split between the "fast" core and the "slower" core. This means that you are better off with 1x4vCPU instance instead of 2x2vCPU, as in the first case only 25% of your cores will be the slower type. With EPYC Rome it is even worse, as there is a chance the 2xvCPU instance can come with 2 slow cores! This was also reproducible and the instance marked n2d-s2 (R) B above is such an instance. I will go into more details about this behaviour at the last section of this post.
I should note also that GCP did some changes to AMD Milan instances between December when I started benchmarking and February. They now report 2.45GHz vs 2.25GHz previously (which is of course inconsequential), but also the peak performance is harder to achieve on n2d instances (c2d is mostly the same), especially on some regions, which tells me they are used more (or are more limited thermally).
I had finished a part of my testing when I noticed the newer "Tau" (t2d) instances with Milan were widely available. They seem to usually be slower than n2d for in single-threaded performance and are exhibiting the same strange issue with the "slow core", however their scalability is much better - seems like you are actually getting a CPU "core" instead of 'thread" for each vCPU. Unlike the n2d Milan, but like n2d Rome, I did manage to get a 2xvCPU instance of t2d which had both cores being "slow", so there's your caveat.
There are deep discounts for instances with 1-year and 3-year commitments, which can significantly lower your costs. Prices also vary per region, for the comparison the lowest prices (available in several US regions like Oregon, Iowa etc) were used.
- Amazon Elastic Comput Cloud (EC2)
| Instance Type / Model | vCPU (# threads) / CPU type | GHz | Price $/ Month | Reserved $/ 1 Year |
| t4g.medium** | 2x AWS Graviton2 | 2.5 | 26.53 | 172.00 |
| t3a.medium** | 2x AMD Naples | 2.2 | 29.45 | 193.00 |
| t3.medium** | 2x Cascade Lake | 2.5 | 32.37 | 213.00 |
| c6g.large | 2x AWS Graviton2 | 2.5 | 51.64* | 350.00 |
| c5a.large | 2x AMD Rome | 3.3 | 58.21* | 397.00 |
| c6i.large | 2x Ice Lake | 2.9 | 64.05* | 460.00 |
| m6a.large | 2x AMD Milan | 1.95 | 65.07* | 467.00 |
**burstable CPU type
Amazon Web Services is still the most popular cloud provider, with an extensive platform. Looking at their EC2 cloud computing platform specifically, what is interesting is that they have their own ARM offering called Graviton. Unfortunately, the latest Graviton3 was still in a closed beta when I was benchmarking, so I had to settle with the Graviton2. A bit disappointingly, while they have an AMD EPYC Milan offering in some regions, it is a lower clocked version than any other provider.
When assessing performance & value, we have to note how the low cost txx "burstable" instance types behave. Specifically, the .medium instances tested can operate at 20% of their full performance while collecting "CPU credits" at a rate of 24/hour and each credit is enough to allow 1vCPU to run at 100% for a minute (or 1vCPU to run at 50% for 2 minutes, or 2vCPU to run at 50% for a minute etc). Max credit allocation is 576, so theoretically if you are under the baseline for a 24h period, you reach those 576 which are enough to use 2xvCPU at 100% for 4.8 hours straight. Basically if you don't have a constant high CPU load, they might be a good solution.
When assessing performance & value, we have to note how the low cost txx "burstable" instance types behave. Specifically, the .medium instances tested can operate at 20% of their full performance while collecting "CPU credits" at a rate of 24/hour and each credit is enough to allow 1vCPU to run at 100% for a minute (or 1vCPU to run at 50% for 2 minutes, or 2vCPU to run at 50% for a minute etc). Max credit allocation is 576, so theoretically if you are under the baseline for a 24h period, you reach those 576 which are enough to use 2xvCPU at 100% for 4.8 hours straight. Basically if you don't have a constant high CPU load, they might be a good solution.
The EC2 prices can vary per region (lowest prices available in a several US regions are listed above), and there are also deep discounts if you reserve and prepay an instance.
- Digital Ocean
| Instance Type / Model | vCPU (# threads) / CPU type | GHz | Price $/ Month | Disk |
| Basic-2 Intel | 2x Intel | 2.3 | 20.00* | 80GB SSD |
| Basic-Prem-2 Intel | 2x Cascade Lake | 2.5 | 24.00* | 80GB NVMe |
| Basic-Prem-2 AMD | 2x AMD Rome | 2.0 | 24.00* | 80GB NVMe |
| Basic-Prem-4 AMD | 4x AMD Rome | 2.0 | 48.00* | 160GB NVMe |
| CPU-Opt-2 (Casc L) | 2x Cascade Lake | 2.7 | 40.00* | 25GB SSD |
| CPU-Opt-2 (Ice L) | 2x Ice Lake | 2.6 | 40.00* | 25GB SSD |
| CPU-Opt-2 (Skylake) | 2x Skylake | 2.7 | 40.00* | 25GB SSD |
| CPU-Opt-4 (Broadwell) | 4x Broadwell | 2.6 | 80.00* | 50GB SSD |
*2xvCPU instances include 4TB out traffic (5TB for 4xvCPU) - unlimited in.
Digital Ocean is most known for their cloud VMs called "droplets". Unlike GCP/AWS it has a very simple price structure: you are charged fixed hourly on-demand prices when you get either a Basic shared CPU type, or a dedicated CPU type, of which the CPU-Optimised is the one that has the 2GB/CPU ratio that I am benchmarking. There are no complicated calculations, all regions are priced the same and even traffic is included (a few TB out, unlimited in).
There is no throttling/burst etc on shared instances, your performance is just not guaranteed like on a dedicated CPU, as you are sharing CPU resources with other VMs. Recently, the Premium variety of Basic instances was added - the main difference is that you get faster NVMe SSDs and you can choose between AMD Rome or Intel Cascade Lake CPUs (compared to unspecified intel for the non-Premium instances). On the dedicated instances you can get anything from a Broadwell to an Ice Lake - you only find out once you launch the instance. I tried to benchmark all types.
I have been using Digital Ocean for a while now - I donate servers to the free weather forecast project 7Timer (for which I develop a free iOS client for amateur astronomers called Xasteria) - so it will be good to confirm my pick as a good value cloud provider (7Timer is running C, php and perl). In fact, if you sign up using my Digital Ocean affiliate link, apart from getting free credit to start with for yourself, if you later continue with paid services you will support the 7Timer project with some free credit.
- Linode
| Instance Type / Model | vCPU (# threads) / CPU type | GHz | Price $/ Month |
| Linode 4G (Skylake) | 2x Skylake | 2.4 | 20.00* |
| Linode 4G (Naples) | 2x AMD Naples | 2.2 | 20.00* |
| Linode 4G (Rome) | 2x AMD Rome | 2.9 | 20.00* |
| Dedicated 4G (N) | 2x AMD Naples | 2 | 30.00* |
| Dedicated 4G (R) | 2x AMD Rome | 2.9 | 30.00* |
| Dedicated 4G (R) | 4x AMD Rome | 2.3 | 60.00** |
*80GB SSD and 4TB out/ unlimited in traffic included.
*160GB SSD and 5TB out/ unlimited in traffic included.
*160GB SSD and 5TB out/ unlimited in traffic included.
Linode has been around for quite a long time, in fact they had already built a good reputation before Amazon Web Services was a thing I had used them for web & dev servers at the company I worked for previously (mostly to do with natural language things - perl-based), as Linode offered very easy setup / deployment / backup etc features along with low prices and a very simple price scheme.
Their main offerings are the Linode shared CPU servers, and the Dedicated CPU servers, with both types including large SSDs and network traffic, at a low on-demand pricing. There's no "reserved" discounts, but also no burst/limit even on the shared CPU servers, you are just affected by how busy the cluster you are on is at the time. Overall, it is quite similar to Digital Ocean, fixed prices over all regions, similar traffic included.
They were one of the first cloud providers to offer AMD EPYC servers, however the main issue is that when spinning up an instance, you can't know what you are going to get. It might be a first-gen AMD EPYC Naples (either 7501 or 7601 model), or a second-gen AMD EPYC Rome (7542 or 7642). The performance difference between the different generations of processors is vast and it is possible the users have picked up on it and have allocated most of the Rome instances - at least for US/CA regions I had to spin up dozens of VMs to be assigned a Rome-powered model, although it is (currently) relatively easy in Singapore or Mumbai regions. Although the 7542 vs 7642 models on paper have a large base clock-rate difference (2.3GHz vs 2.9GHz), their peak clock rate & performance can be similar (more of a difference between data-centers than between models). I only once managed to get a Rome instance in the Ontario, CA region, but it was the only case I ever had an AMD Rome instance break 1000 on single-thread Geekbench. I do sometimes get Intel Skylake instances on that region instead.
So, despite not having the latest AMD generation, Linode has quite fast AMD Rome instances, but allocating one of them might not be an easy thing at all, depending on the region.
- Microsoft Azure
| Instance Type / Model | vCPU (# threads) / CPU type | GHz | Price $/ Month | Reserved $/ 1 Year |
| B2s** | 2x Cascade Lake | 2.5 | 31.15 | 227.40 |
| D2as_v5 | 2x AMD Milan | 2.7 | 63.12* | 458.40 |
| D2s_v5 | 2x Ice Lake | 2.8 | 70.32* | 510.36 |
| D4as_v5 | 4x AMD Milan | 2.7 | 126.24* | 916.80 |
| D4s_v5 | 4x Ice Lake | 2.8 | 140.64* | 1020.72 |
*4GB RAM/CPU
Microsoft's Azure is by far the most popular cloud service provider in the Windows world, and also #2 overall. Although I had never used them myself previously, I was aware they do have good Linux support, so I though I would give them a try.
Their instance type and pricing scheme seems even more complicated than AWS/GCP, in fact their pricing calculator has a scary "instance" dropdown with 200 or so items! I guess part of the complication is that instance types have "versions" (v1, v2... v5...), which is not an entirely bad thing as they define a specific CPU type - although it is hard to find the equivalent types for all types (the documentation was missing some available types etc). There are also two general "VM versions" (V1 vs V2), with VM images compatible either with one or the other. In the end I benchmarked the latest generation of the basic Intel & AMD D types, as well as their B2s burstable type, which works almost exactly the same as the equivalent AWS types, where your 2xvCPU instances gain 24x1-minute full CPU credit per each hour in which you are under the specified utilization threshold.
- Alibaba Elastic Compute Service (ECS)
| Instance Type / Model | vCPU (# threads) / CPU type | GHz | Price $/ Month | Reserved $/ 1 Year |
| ecs.t6-c1m2.large* | 2x Cascade Lake | 2.5 | 35.28 | 288.35 |
| ecs.n4.large | 2x Skylake | 2.5 | 35.28 | 288.35 |
| ecs.c6.large | 2x Cascade Lake | 2.5 | 59.04 | 396.07 |
| ecs.hfc6.large | 2x Cascade Lake | 3.1 | 66.96 | 449.72 |
| ecs.c7a.large** | 2x AMD Milan | 2.55 | 59.16 | 414.08 |
| ecs.hfc7.large** | 2x Ice Lake | 3.3 | 83.95 | 573.91 |
**Singapore & China regions only
According to various sources, Alibaba Cloud is #4 in cloud providers by total market share, which was news to me, although I knew they were the most popular in China, so I thought I should give them a try.
According to various sources, Alibaba Cloud is #4 in cloud providers by total market share, which was news to me, although I knew they were the most popular in China, so I thought I should give them a try.
There's a wide range of cloud services, with their ECS modelled after Amazon's EC2, down to how burstable instances with credits work. Well almost, although theoretically the credit accrual/consumption of the t6 burstable instances is the same as on Amazon, one difference is that once you have about 5 credits left, the throttling starts slowly, so you approach 0 credits slowly (almost asymptotically), by using less credit the more you are throttled. There are reservation discounts and prices vary by region. Availability of instance types also varies by region - I could only get the latest Ice Lake and Milan instances in Singapore (or China if I could), while there is an Arm offering limited to China. I had signed up for an enterprise account under own sole-proprietorship (it seemed to offer a wider range of services), so I could not then complete the China region requirements which asked me to send my business registration number (don't have one, not an Inc.) and documents. However, the ARM solution is using the same cores (Ampere Altra) as Tencent, which I did get to try.
- Tencent Cloud Virtual Machine (CVM)
| Instance Type / Model | vCPU (# threads) / CPU type | GHz | Price $/ Month |
| S5.MEDIUM4 | 2x Cascade Lake | 2.5 | 43.80 |
| S6.MEDIUM4** | 2x Ice Lake | 2.7 | 51.10 |
| SA2.MEDIUM4 | 2x AMD Rome | 2.6 | 36.50 |
| SA3.MEDIUM8** | 2x AMD Milan | 2.55 | 43.80* |
| SA3.2XLARGE16** | 8x AMD Milan | 2.55 | 109.50 |
| SR1.MEDIUM4*** | 2x Ampere Altra | 2.8 | 29.20 |
| SR1.XLARGE16*** | 8x Ampere Altra | 2.8 | 124.10 |
All instances are with 50GB cache-enabled HD
*4GB/vCPU
**China regions only
*4GB/vCPU
**China regions only
***China/Guangzhou region only, CentOS/Ubunty only
Tencent Cloud is the second Cloud provider by market share in China (or 3rd, Huawei may be ahead depending on the source). Unfortunately, their most interesting VM types (latest generation Intel/AMD & even ARM) are only available in China regions. However, I did manage to try them out by uploading my driving license: it was rejected at first as "name does not match", but after opening a ticket with their support, I had an answer in less than half an hour and I figured out that they could not match different cases of latin letters, so I had to resubmit my name in FULL CAPS to then be accepted within a few minutes. Apart from ID verification, the Chinese region has really poor connectivity with the outside world, so it is only recommended for applications where you do not need connectivity to/from outside China. For example, the ~100MB geekbench download took about an hour, and some non-Chinese mirrors of files (CPAN etc) would stall at times. Prices depend on the region, with China regions being less expensive than US/EU, hence you can get the SA3 (Milan) in Beijing at the same price as the SA2 (Rome) in Frankfurt and the ARM-powered SR1 (Ampere Altra) in Guangzhou comes out at a very competitive price. There are no reserved instances yet, but I am reading that they are in beta.
- Mac Mini & Laptop (Mobile CPU) comparison
| Instance Type / Model | vCPU (# threads) / CPU type | GHz |
| M1 Mac Mini | 8x Apple M1 | 3.2 |
| MBP 2015 15" i7 | 4x Haswell* | 2.5 |
| Thinkpad X13 AMD | 6x AMD Renoir* | 2.1 |
| Thinkpad X395 | 4x AMD Picasso* | 2.1 |
In any case, to get an idea of the CPUs I have available for comparison, my Macbook Pro is quite old, with the mobile Haswell i7, which is the immediate predecessor of the Broadwell that is the oldest Intel that I saw on the cloud offerings. The X395 has a Zen+ Picasso, so architecturally it would be between Naples and Rome, while the X13 has a Zen 2 Renoir, which is the laptop equivalent of the Rome architecture. Lastly, the ac Mini has Apple's surprisingly fast ARM M1, and can only be compared I guess with the Amazon Graviton2 and Ampere Altra CPUs, although those came out a bit earlier, so I'd have loved to try the newer Graviton3.
For all providers I used the standard Debian 11 (Bullseye) image (with the exception of SR1 on Tencent, for which I used the CentOS 8.2 ARM image) and installed a few basics:
apt-get update apt install -y perl-modules-5.32 unzip wget build-essential cpanminus libxml-simple-perlI then installed and ran the following benchmarks:
- DKBench Perl Benchmark
wget https://github.com/dkechag/perl_benchmark/archive/refs/heads/master.zip unzip master.zip cd perl_benchmark-master ./setup.pl ./dkbench.pl
It will print results per benchmark, as well as a total for the suite. I ran the benchmark at least a dozen times per instance (and even more for GCP EPYC instances) and over different hours/days, and recorded the best & worst runs to have a range.
There is also a utility which runs the single-threaded prime benchmark of the suite in parallel queues. The prime benchmark is not as real world as others (I doubt you'd want to calculate primes in pure perl) but it is the most scalable, so I used it to calculate an upper limit of mutli-threaded scalability. Specifically, I ran the tool once without the thread parameter to get the performance per thread when all available threads are running in parallel, then once with -t 1 for a single threaded run. To install the required module and run multi & single threaded you would do:
cpanm MCE::Loop ./prime_threads.pl ./prime_threads.pl -t 1
So, if on a single thread you get a 2 second average run per benchmark iteration and on 4x threads you get a 3 second average run, it means you have (2/(3/4)) = 2.67x of the single-thread performance over those threads, or 2.67 "equivalent/adjusted" (i.e. full performance) threads, or 100*2.67/4 = 66.75% scalability.
This is the test that actually gave me information on why I was getting so much inconsistency from Google's AMD solutions, which I will elaborate on at the end of this post. I'll just say here that due to one of the cores on n2d, c2d, t2d instances being slower, I had to calculate an adjusted single thread run time from the time α on a regular (fast) core and time β on a slow core as n/((n-1)/α+1/β) for n cores.
You can get the results of the benchmark & prime threads in a spreadsheet here. The data is used for the charts, but it also includes breakdown of each benchmark in case you are interested in a specific benchmark's behaviour.
- Geekbench5
wget https://cdn.geekbench.com/Geekbench-5.4.4-Linux.tar.gz tar xvfz Geekbench-5.4.4-Linux.tar.gz Geekbench-5.4.4-Linux/geekbench5
For ARM systems I had to use https://cdn.geekbench.com/Geekbench-5.4.0-LinuxARMPreview.tar.gz instead.
Geekbench5 has a multi-core result that shows a bit lower scalability than the DKBench prime benchmark (which is why I chose the latter as my scalability test), but I will show the Geekbench5 scalability as well for reference. So if you have a 4xCPU system with a 1000 single-core score and a 2500 multi-core score, your scalability is: 100*(2500/4)/1000 = 62.5%.
- Perl 5.32.1 compilation (perlbrew)
\curl -L https://install.perlbrew.pl | bash source ~/perl5/perlbrew/etc/bashrc perlbrew download perl-5.32.1 time perlbrew install perl-5.32.1
Results
All results are charted with a color code to tell cloud providers apart, and the CPU type shown in a parenthesis after the instance name:
(I) = Intel Ice Lake/Cooper Lake
(C) = Intel Cascade Lake
(S) = Intel Skylake
(B) = Intel Broadwell
(M) = AMD Milan
(R) = AMD Rome
(N) = AMD Naples
(G) = Amazon Graviton2
(A) = Ampere Altra
= Unspecified Intel (Broadwell/Skylake)- Single-thread Perl performance
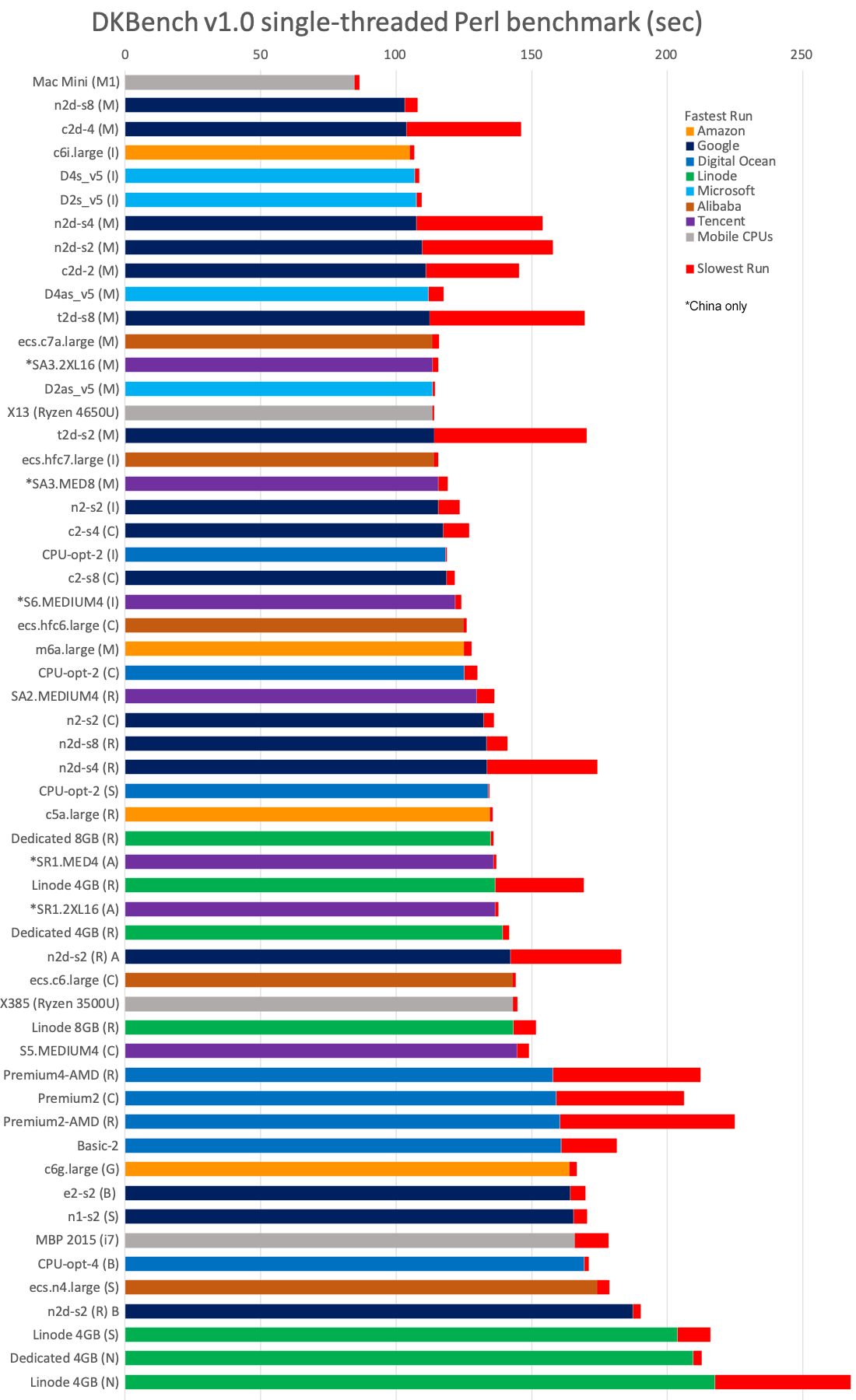
From the results graph it is interesting to see that no cloud instance can currently reach the single-core performance of Apple's M1 when it comes to running perl. But there is a lot o variation between the cloud instances themselves, with the slowest ones offering less than half the speed of the fastest. Of course when it comes to cloud, things that matter usually are scalability and cost, which we will look into in depth, but forgetting them for now, from this result we see that:
- You can get an idea of your expected performance from the CPU type. The fastest instances are running either Intel Ice Lake, or AMD Milan. Google's Milan instances would have a clear lead, but they sort of cripple them by having the 1 slow core issue (extra prominent on t2d), so Amazon's and Microsoft's Ice Lake instances have a bit better average performance, even though their maximum speed is lower. Cascade Lake and Rome instances are the second speed tier along with the Ampere Altra, although Google has the c2 being fast enough to catch up to some of the slower Ice Lake or Amazon's Milan. The third tier is Broadwell/Skylake, Amazon Graviton2 and behind them the AMD Naples.
- Some providers offer special, more expensive, "compute" instances that promise higher clock speed. That seems to work for Alibaba with their hfc instances and Digital Ocean's CPU-optimized, but for Google, c2d vs n2d, or n2 vs c2 have small differences (mainly limited to worst performance), even worse with t2d slower than n2d, and it is a bit similar story with Linode's shared CPU plain Linode often performing as well as the Dedicated instances. Lastly, Digital Ocean's Premium instances are often slower than their Basic, so only pay extra for the former if you need their faster NVMe storage.
- I've heard some bad things about Microsoft's Azure (possibly because I am in a more "Linux-oriented" environment), but I have to admit that they seem to be able to make good use of the hardware - their Ice Lakes are the fastest along with Amazon's, while their Milans are faster than Amazon's and without the weird issues Google exhibits.
I left the burstable instances separate, with the slowest vs fastest run replaced by the burst CPU run and the sustained (no burst) run:
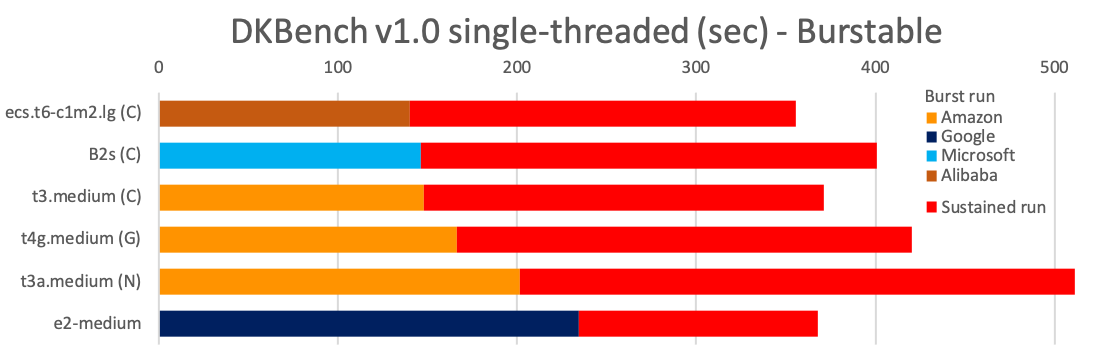
Google seems quite a bit slower maximum burst performance, and given the fact that its bursts only last 2 minutes, they are your worst pick if you want to rely on burst speed. The others have the same burst CPU credit scheme and more comparable performance, so we'll see how they compare later when we'll add cost to the equation.
Let's see how the VMs do when compiling perl next:
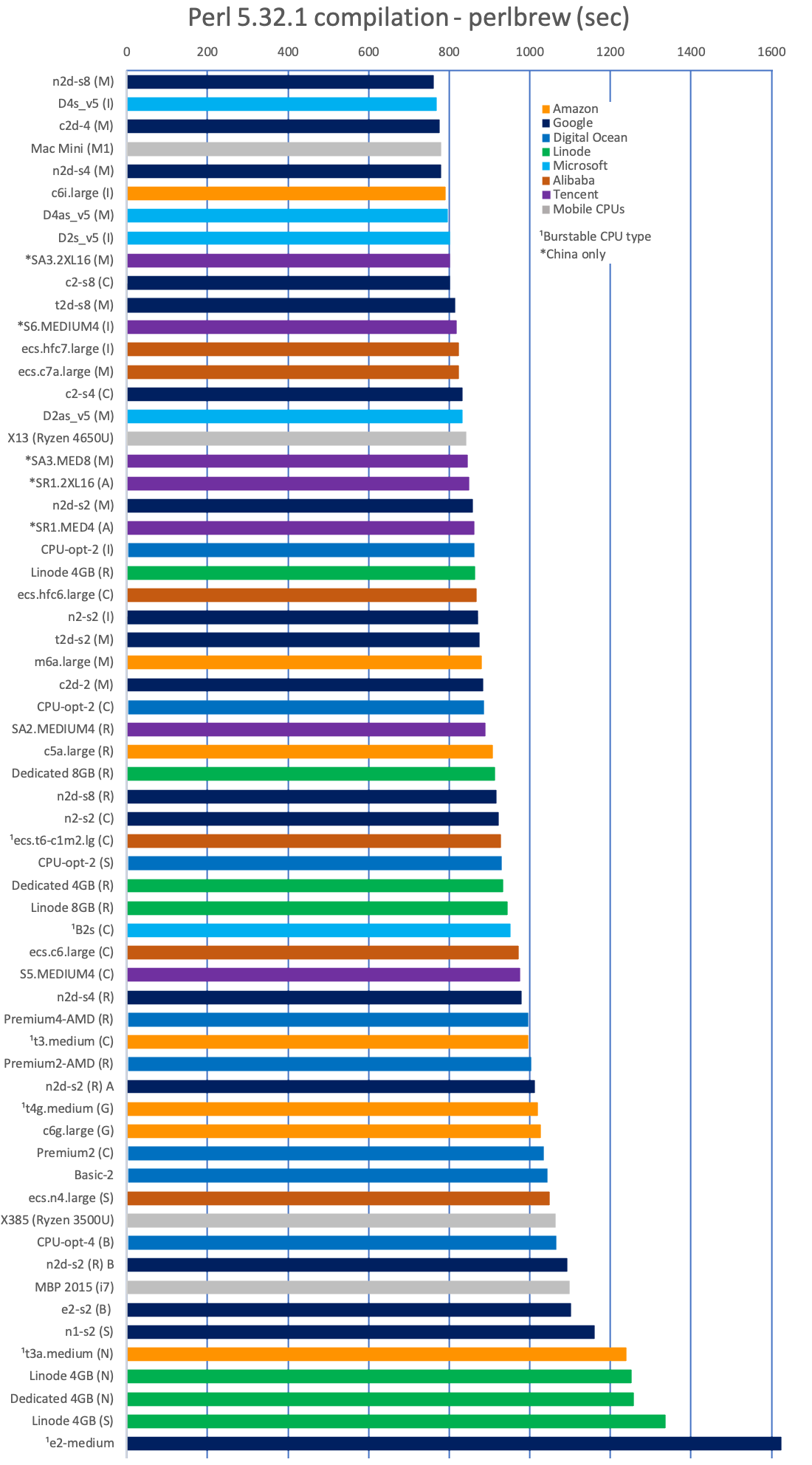 Not a drastically different story from the Perl benchmark - it seems that Google's Milan types would have dominated if they did not have the slow core issue, so Azure's Ice Lake instance catches up (and with both these being faster than the M1 now). Cascade Lake instances seem a bit all over the place here, while the Ampere Altra looks even better. All burstable CPU type instances have enough burst to finish the task (simulating the launch of a new instance, which grants 60 CPU credits), except Google's e2-medium, which is why it is by far the slowest.
Not a drastically different story from the Perl benchmark - it seems that Google's Milan types would have dominated if they did not have the slow core issue, so Azure's Ice Lake instance catches up (and with both these being faster than the M1 now). Cascade Lake instances seem a bit all over the place here, while the Ampere Altra looks even better. All burstable CPU type instances have enough burst to finish the task (simulating the launch of a new instance, which grants 60 CPU credits), except Google's e2-medium, which is why it is by far the slowest.- Single-thread Geekbench 5
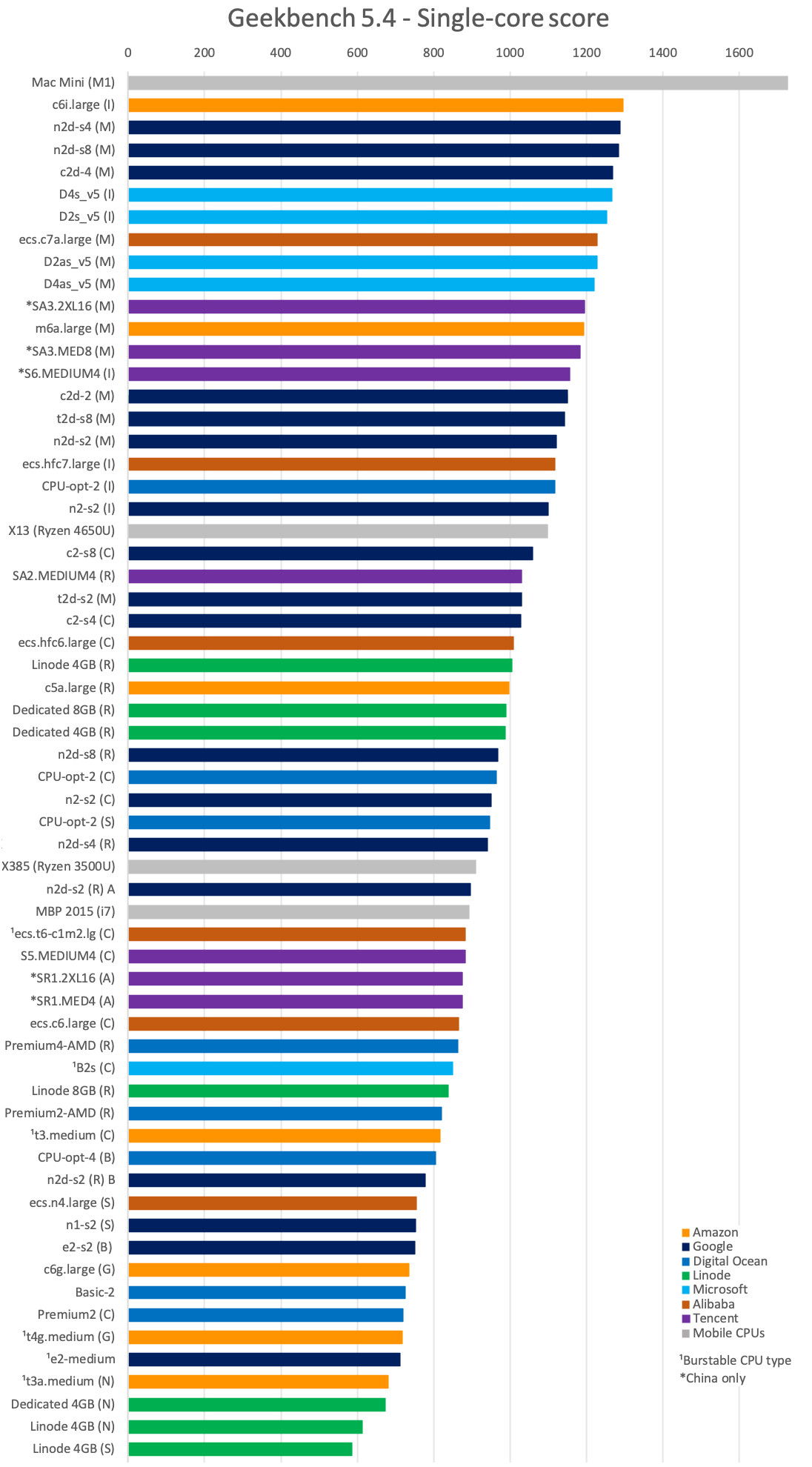
- Single-threaded Performance / Price (best value)
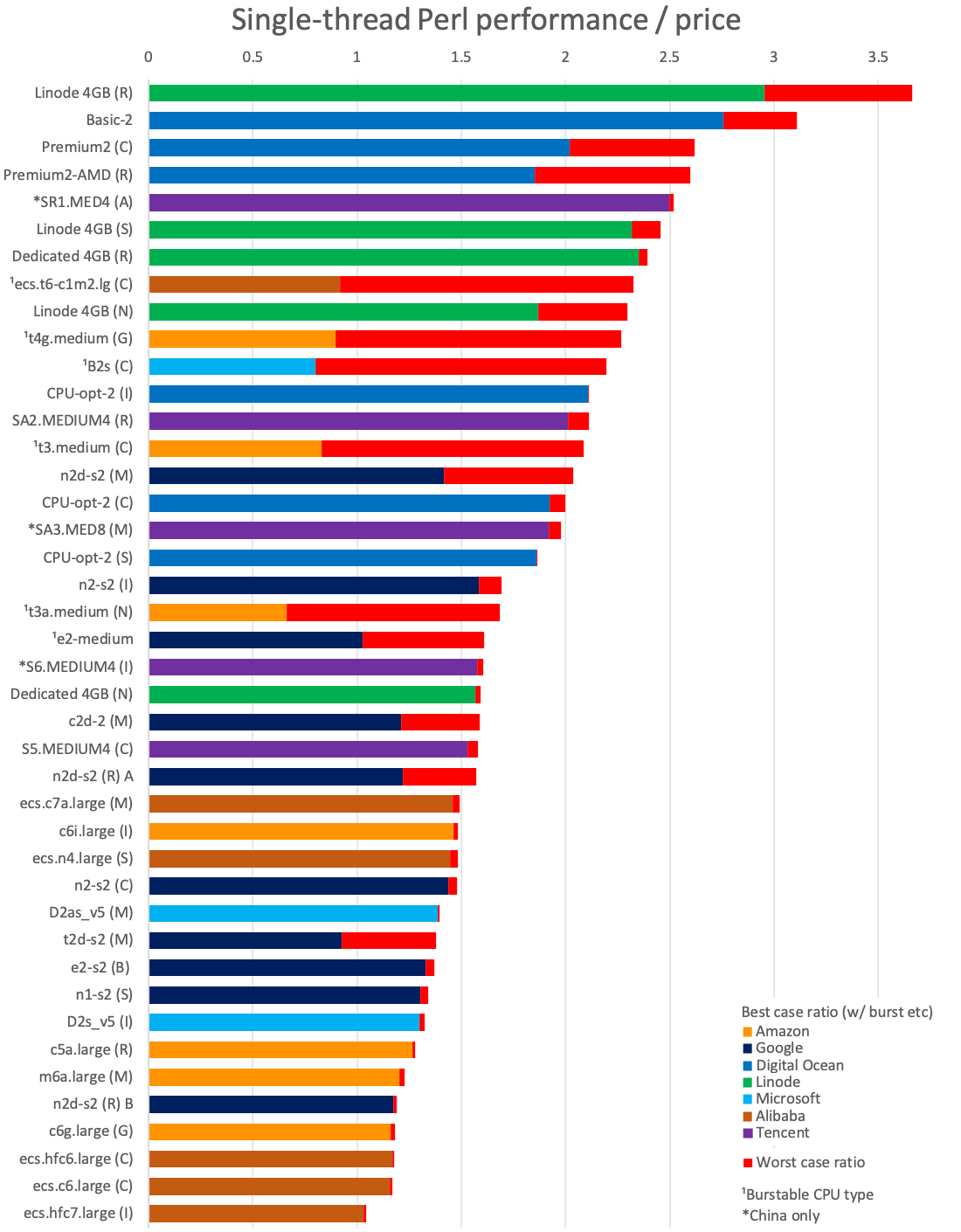
From the larger cloud providers, if you want non-burstable types, top value comes from Google's n2d and n2 instances, Amazon and Azure lag quite a bit behind, and Alibaba does quite poorly. The burstable types are pretty poor value if you need heavy processing tasks with constant full load, but Alibaba's t6, Amazon's t4g and Azure's B2s do provide the great value if you don't have such a need.
- Multi-threaded performance & CPU scalability
The answer is: it depends. From my tests, it seems that usually (or in all cases of instances advertised as "dedicated" vCPUs - except Google's t2d), if a CPU offers 2x threads per core (like most Intel and AMD CPUs), a vCPU is a thread, so a 2xvCPU VM will have one core with 2 threads (despite whatever you see in /proc/cpuinfo etc - that can report anything you want for a VM), which, as you probably know, means that if you are running two threads at the same time, each one will have significantly less performance than if it had the entire core for itself. When you buy a laptop/desktop CPU, the "core" count is usually advertised. E.g. the Ryzen 4650U is advertised as a "6 core" CPU, although it has 12 threads. If a cloud solution was built on it, it would most likely be sold as 12 "vCPUs". At least, if you buy a 4xvCPU solution, it will be like having 2 Cores, 4 threads, so you will get that 2x boost in performance over a 2xvCPU (I did verify that with a few 4x and 8x instances to be sure) - in essence think of a 2xvCPU unit as the "base" unit (which is actually how it works for most dedicated vCPU instance types).
Therefore, for the most common case where you are interested in running loads on all your CPUs, it is important to calculate the scalability. In the following chart, I used the prime benchmark and did the calculation as described in the Setup & Benchmarking section, which is like an "upper bound" or "optimistic" scalability, and included the Geekbench5 scalability as well for reference (it is not reliable for Google's AMD instances). A 100% scalability means that your 2vCPU solution can run 2 threads in parallel without losing any of the single-threaded performance on each thread:
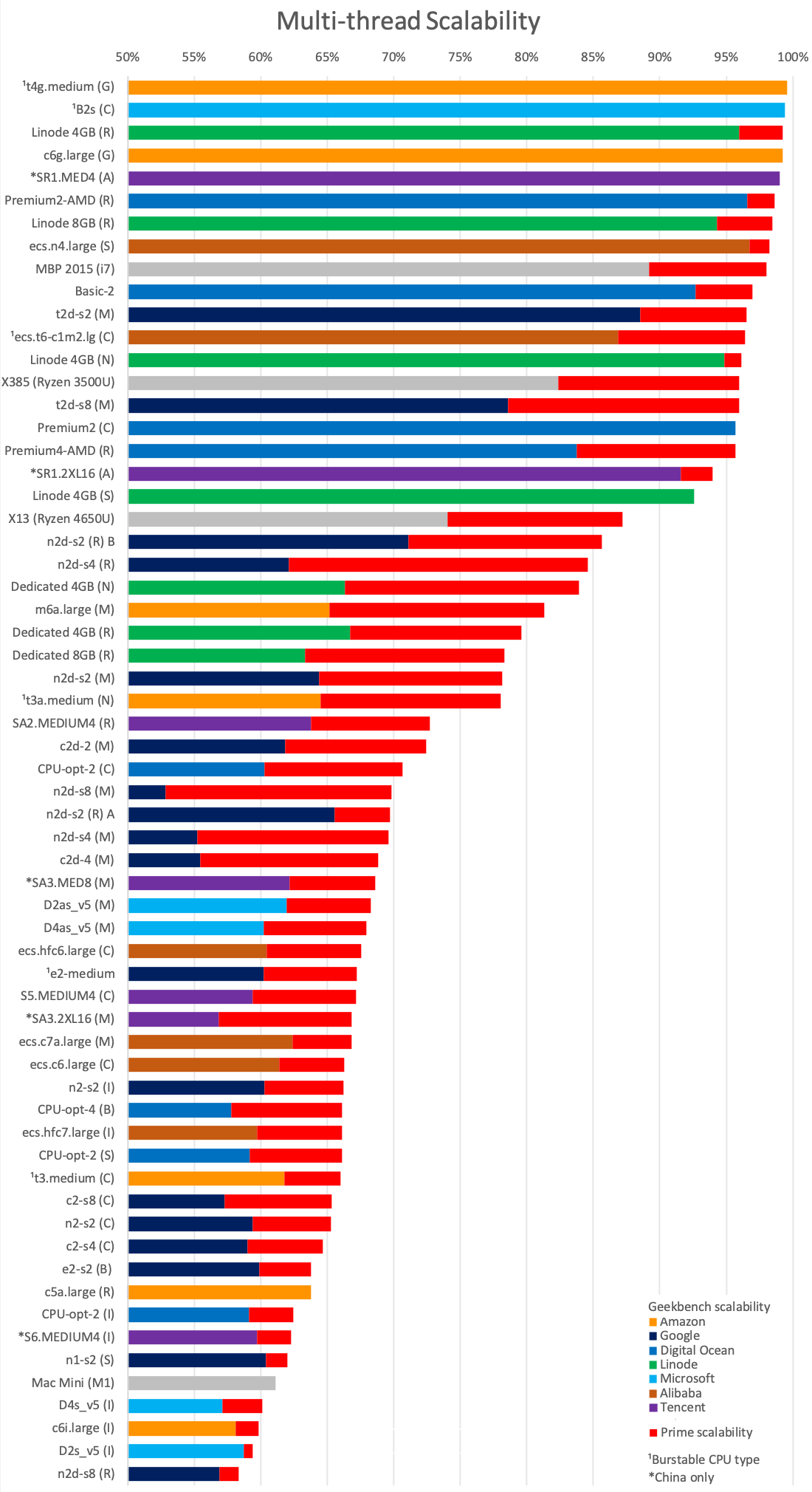
Another interesting fact is that we can see that Cascade Lake seems to scale better than Ice Lake, while AMD Milan does clearly better than either of them.
But how about if we apply scalability x #vCPUs to the performance/price ratios to get an idea of the possible maximum performance/price ratio for an optimistically scalable/parallel load? We can now include instances of > 2xvCPU:
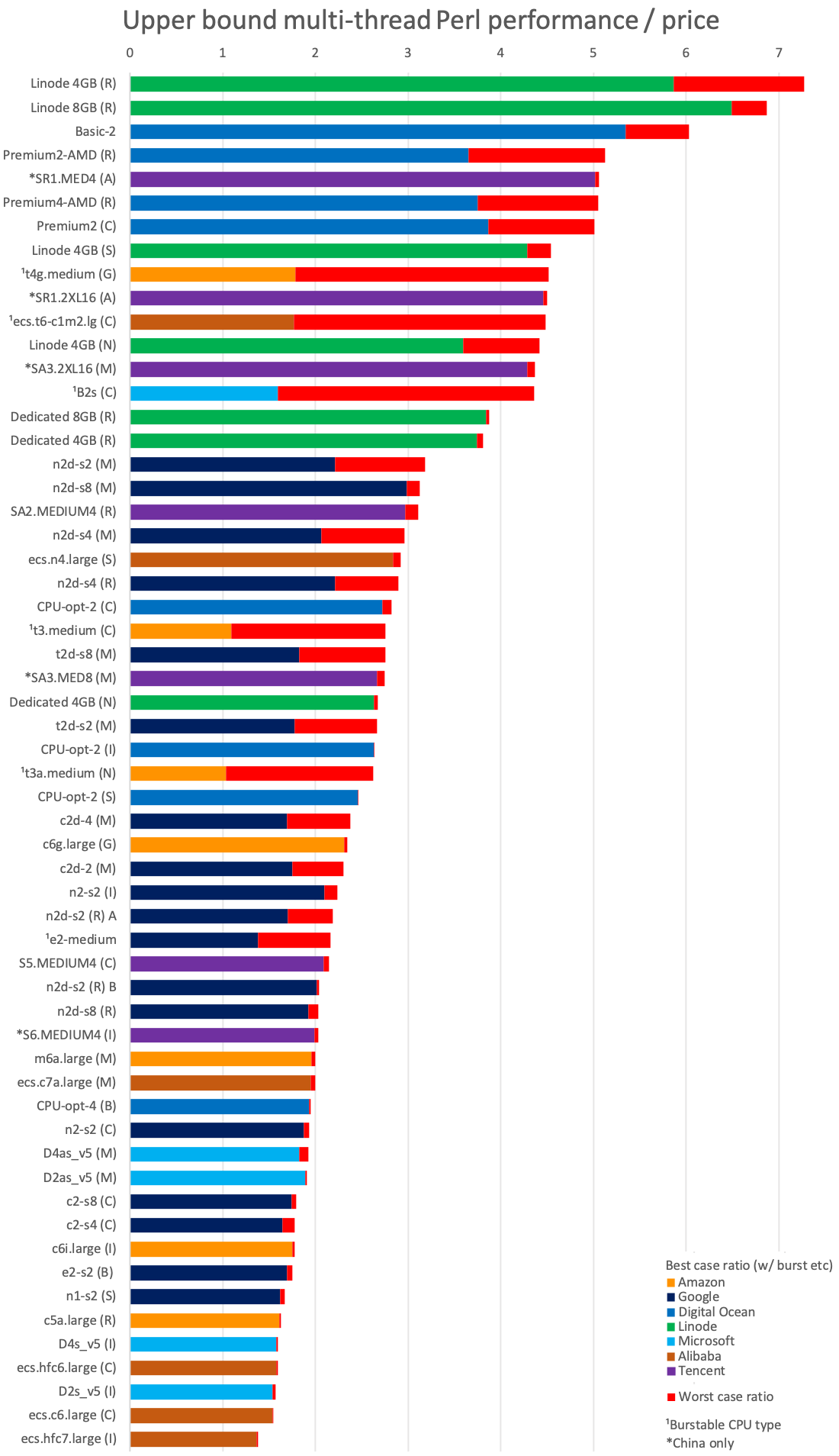
The inexpensive shared-CPU instances from Linode (EPYC Rome versions, which were very hard for me to actually get) and Digital Ocean again dominate. The Tencent solutions available only in China regions (powered by Altra and Milan) are very close, as are some burstable-instances, but only while at burst-speed, so not for sustained loads. From the top-3 providers, Google's n2d Milan types are the best value, quite further back you get Amazon's Graviton2. This makes me more curious about the newer Graviton3, if it's better than the Altra, maybe they have a winner, but they didn't even reply to my request to try it. As it is, Amazon, Microsoft and Alibaba offer the worst values for on-demand instances, with their Intel types being worse than their AMD types.
- Geekbench 5 Multi-core
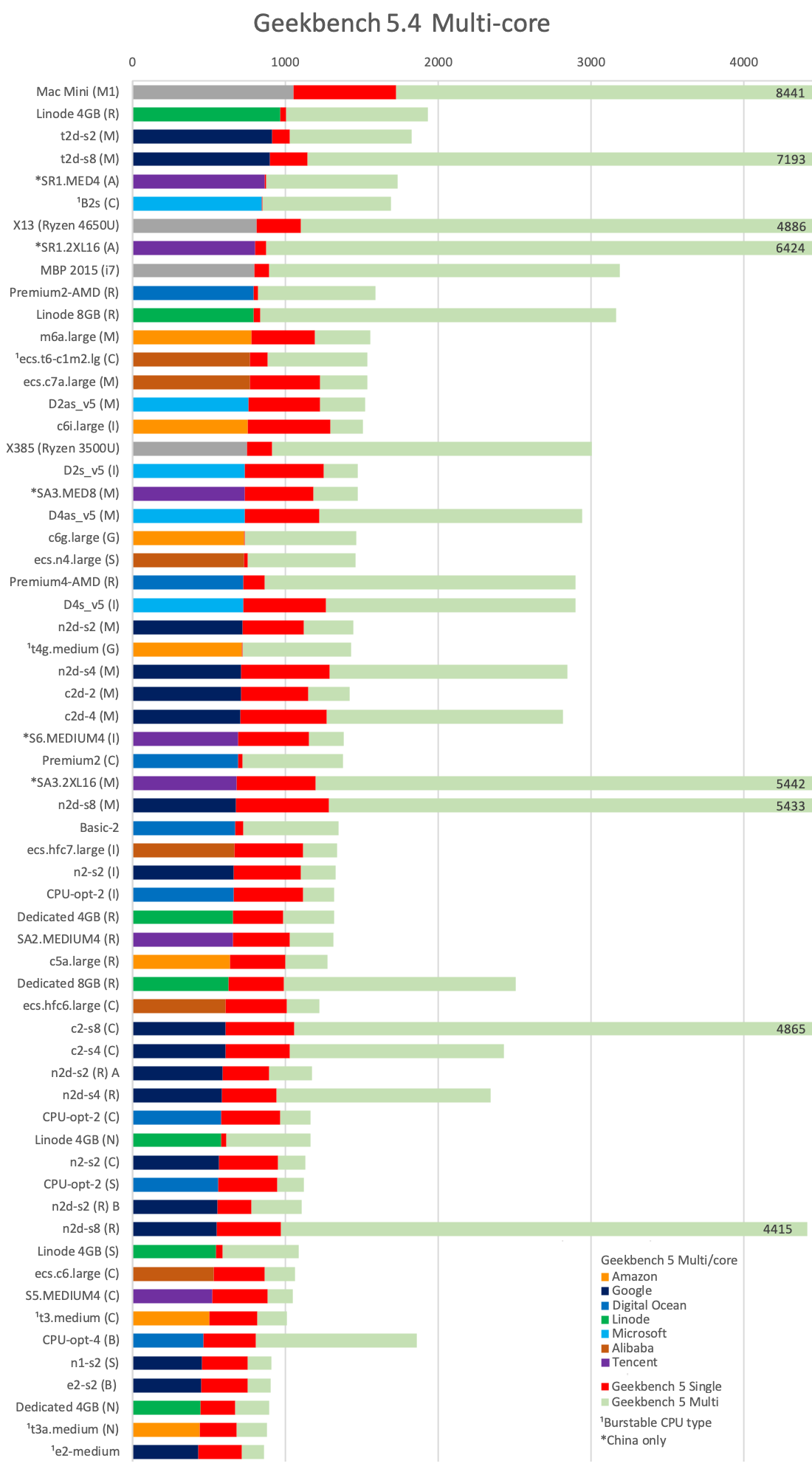
The single-core scores are in red for comparison - the more scalable a solution is, the less difference between the red single-core score and the adjusted multi-core per core score.
As we can see, after the M1 and Linode's shared CPU Rome instances, we have Google's Tau and Tencent's ARM-powered SR1.
Otherwise the general trend is that AMD is doing better than Intel across all providers, although Amazon's and Microsoft's Ice Lake types score well too.
If you are looking at burstable types, the Azure B2s is the clear lead with a great score while bursting.
I would be more interested in dividing the total Multi-core scores by the cost though. Let's see how many Multi-core points you can buy with 1 month-dollar for each solution:
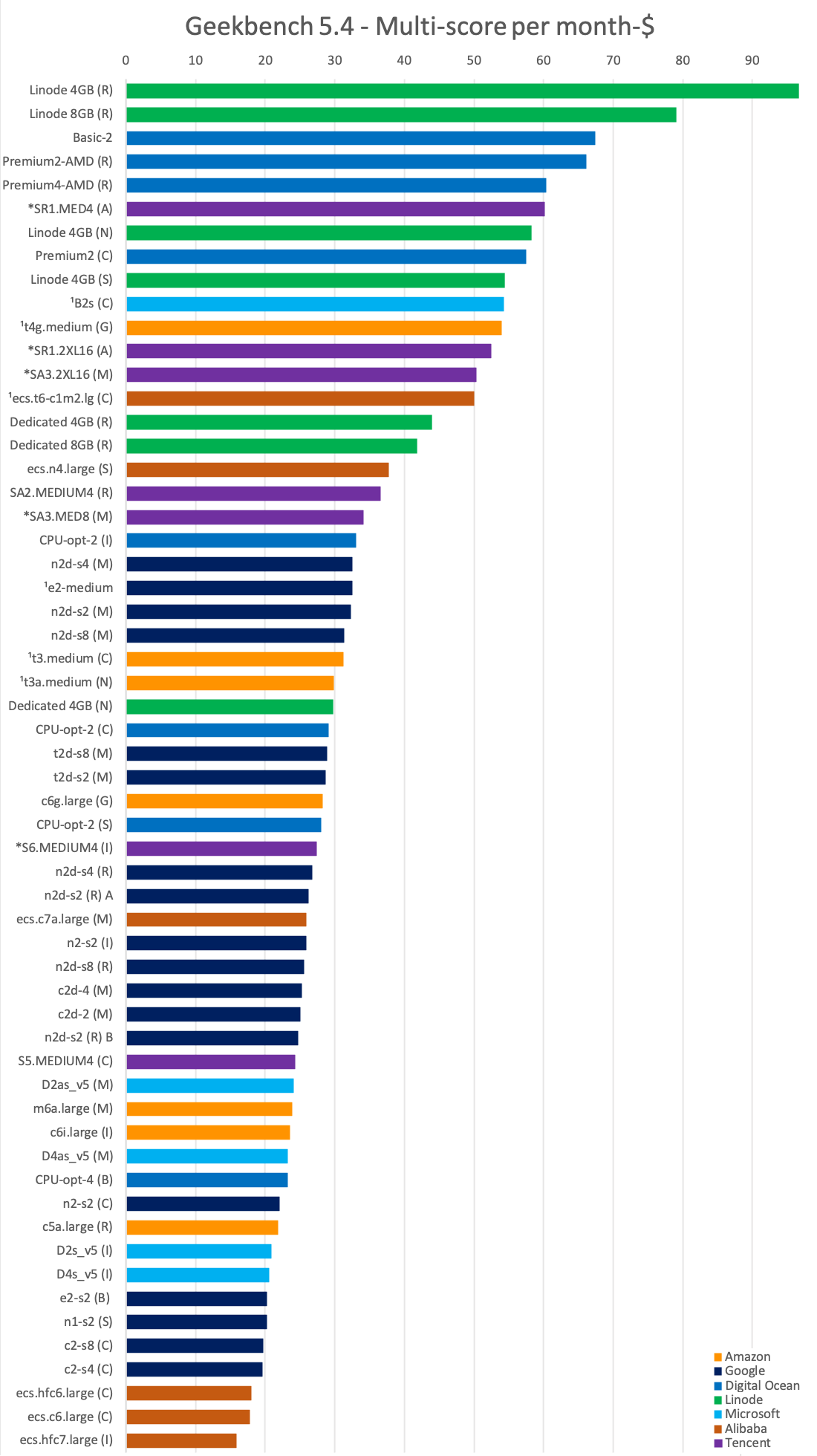
What's left to see is how the reserved discounts change the value landscape.
- Performance/Price including 1Y reserve discounts

The 1 year discounts do make some options of the "big 3" more appealing, but only their burstable instances can come on top of Linode and Digital Ocean, and those only for the duration of their burst, with Amazon's Graviton2-powered t4g he best among them. Otherwise, the only great value from the big providers is Google's n2d Milan. Alibaba's c7a which is following is only available in Singapore, which is not a huge issue like the China-only solutions, but again not for everyone. For Amazon you are looking at the c6i as your best option, while Microsoft is trailing in this comparison.
Moving on to the multi-thread chart:
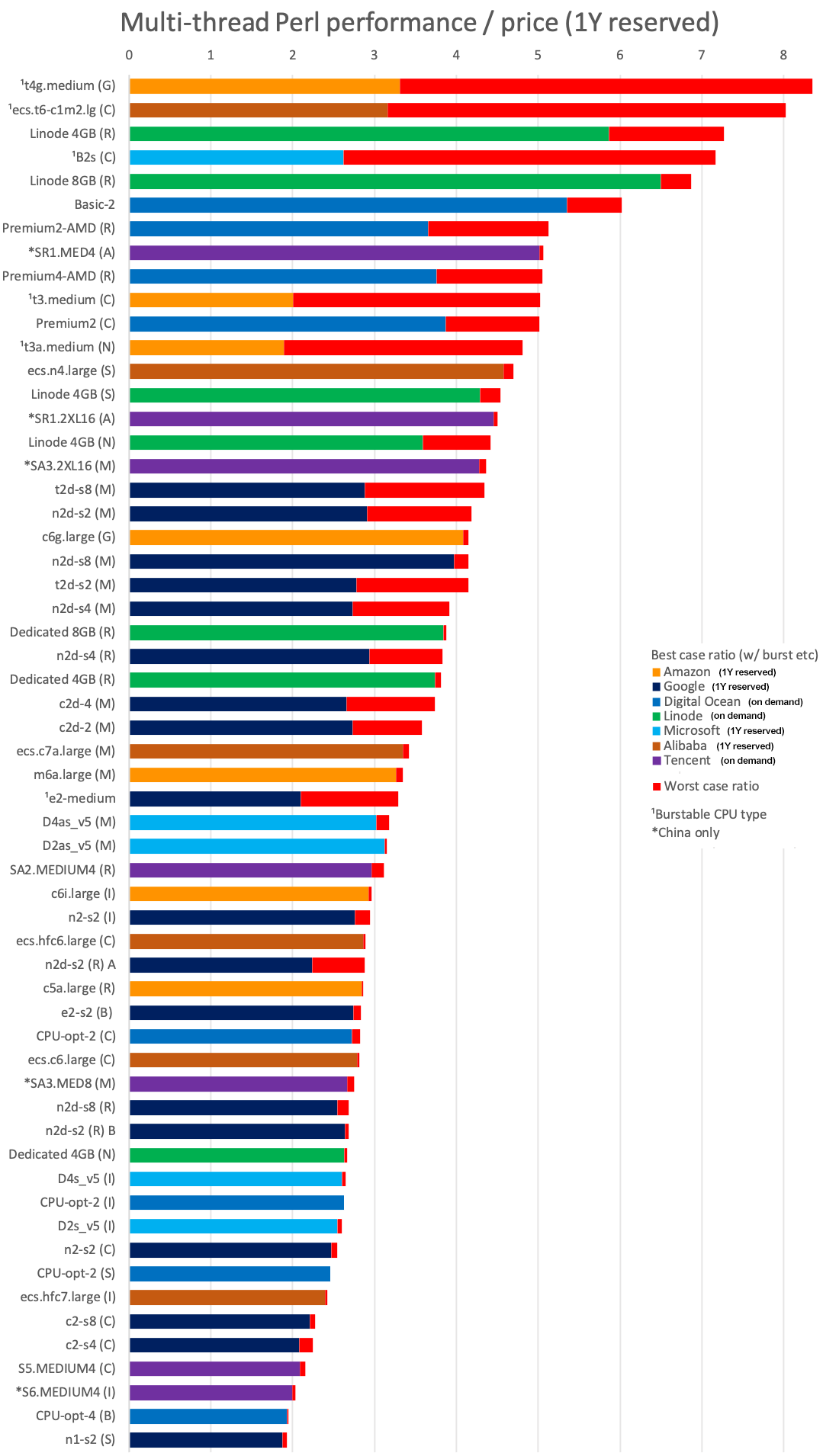
Not a vastly different picture. If you don't need sustained workloads, Amazon's t4g and Alibaba's t6 burstable types lead the value chart as long as you buy a 1 year reservation. Otherwise it's back to Linode's 4G Rome and Digital Ocean's Basic for best value if you need sustained processing power, and you can turn them off when you want to and save more, there's no reservation. Tencent's SR1 with the Altra is also high in the chart - I'd love to see that available in non-Chinese regions.
The best non-burstable values from the largest providers are Google's Milan n2d and t2d and Amazon's Graviton2 c6g. There is again an overall value advantage of AMD and ARM solutions over Intel.
Lastly, let's see the most Geekbench 5 points you can buy for $1/month:
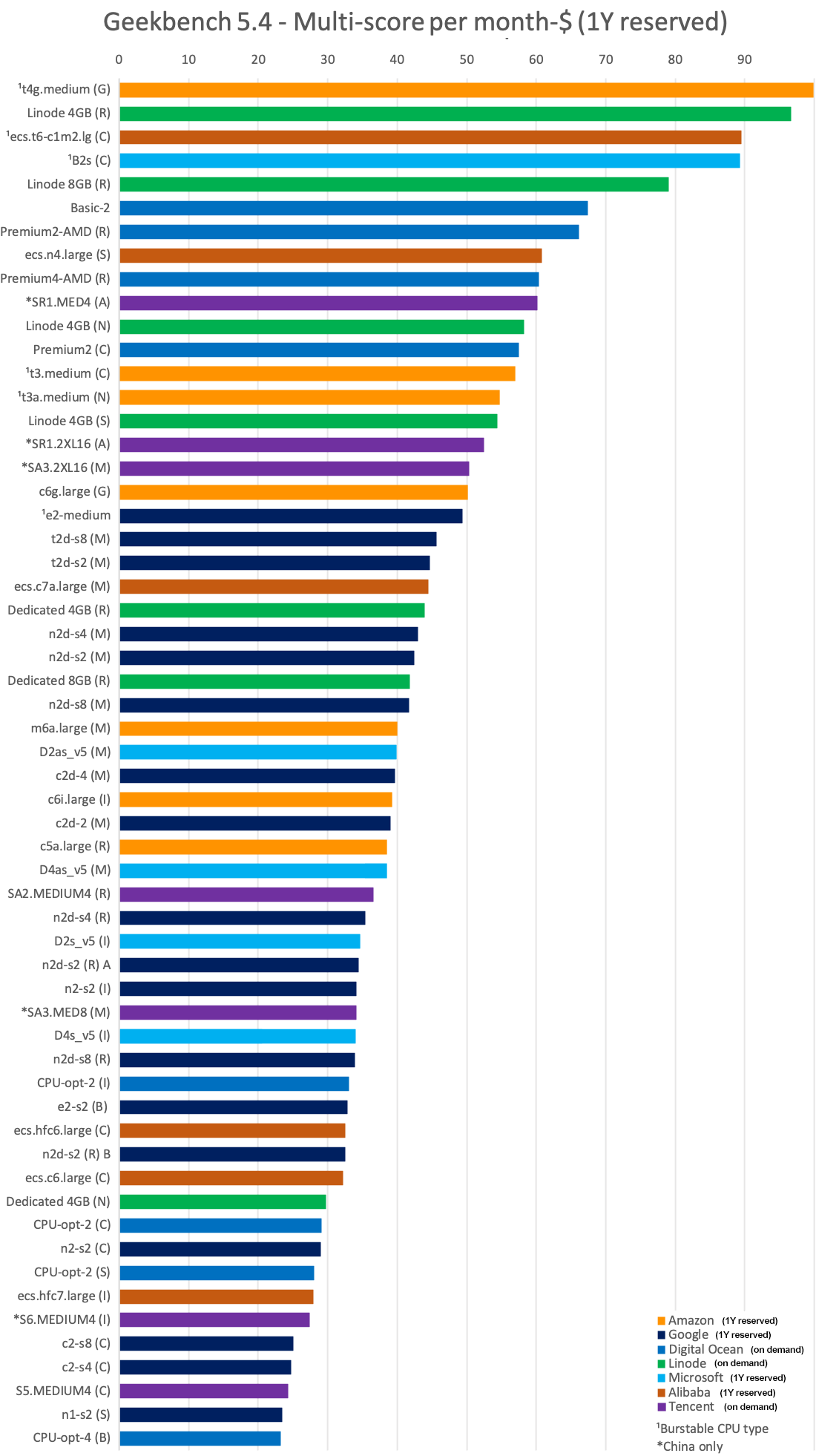
A few differences with the perl comparison worth noting: The Alibaba n4 powered by an old Skylake, with its 1Y discount is the closest to the usual Linode/Digital Ocean leaders. The Graviton2 (Amazon c6g) manages to just beat the Google Milan instances and for those it's the first time the t2d is ahead of the n2d. As a general observation, compared to the Perl benchmarks, Geekbench Multi-core seems to benefit even further the ARM and AMD types versus Intel.
- Real-world comparison examples
4xvCPU n1 vs n2 web servers (serving our perl application) behind a load balancer that is sending the requests depending on each server's load:
| Server | n1-s4 | n2-s4 | difference |
| k-Requests | 228.05 | 283.18 | 24.18% |
| Avg. Response | 54.95 | 51.04 | -7.13% |
The n2 serves 24% more requests, still at a 7% faster response time. The n2 is more expensive than the n1 though.
A similar experiment was done with the n2d Milan (on a different set of servers, so results are not directly comparable with the above):
| Server | n1-s4 | n2d-s4 | difference |
| k-Requests | 167.90 | 291.51 | 73.62% |
| Avg. Response | 127.58 | 119.18 | -6.58% |
The load balancer sent 74% more requests to the n2d server, and it still processed them almost 7% faster. And did so for the same price.
2xvCPU n1 vs n2d Milan Sphinx Search servers running in parallel under a load balancer:
The n2d Milan is a spectacular 3.9x faster in Sphinx Search queries compared to the similar-priced n1! This is the workload with the biggest difference between these two types that I have seen.
Conclusion
There are quite a few conclusions I can draw from my testing. They may not apply to everyone, and they are based on my own testing process, but I do provide all the data so it is as transparent as possible, an thus may help others. Here goes:
- If only want the best value for Linux VMs and don't care about any of the specific extra infrastructure of the big Cloud providers, there is no reason to go to them. Linode and Digital Ocean's lowest cost shared-CPU solutions are the best value by a good margin, for both single and multi-threaded tasks. Unlike the other providers both those two also include significant traffic in their price and large SSDs. Digital Ocean is a bit easier to work with, as you don't have to hope in your good luck of getting an EPYC Rome instance like you do on Linode (whose more commonly available Naples instances are much slower). I had surmised that was the case a couple of years ago when I was looking for a good provider get VMs to donate to the free 7Timer weather forecast project, and it seems not much has changed. In fact, if you do want to try out Digital Ocean, going through my affiliate link will both give you free credit and, should you decide to use the provider will give credits back to the project I support.
- The only case where Linode and Digital Ocean don't come out on top in value, is when you don't need sustained performance, so a burstable type will do and are willing to prepay 1 year of reserved usage. In this specific case, Amazon's t6g is your best bet, unless you prefer x86, in which case you are looking at the Azure B2s or Alibaba t6. In sustained performance, the burstable instances don't provide either good performance or good value.
- If you want the best performance you can buy, you are looking at Milan solutions from Google (n2d, c2d, t2d) or Microsoft (D*as_v5) - Amazon m6a is lagging a bit when single-threaded - and Ice Lake from Amazon (c6i) or Microsoft (D*s_v5). If you want the best performance that is also a good value, you are probably looking at the Google n2d Milan, despite Google sort of "crippling" one of their cores, so you would prefer themin 4+ vCPU configurations.
- ARM is making a decent showing, I wish the Altair Altra was available in non-Chinese regions so it is a choice. The Graviton2 is not as fast, but still a good choice for heavily parallel workloads if you are on AWS - so the Graviton3 could be very interesting.
I'll finish of with my impression/notes on each provider based on testing with them:
- Google Compute Engine: They seem to have the fastest AMD Milan cores, which are the easily the fastest overall cores across providers when they are not affected by the "slow core" bug. Even so, they are definitely your best choice among the "big 3", with the n2d probably making the most sense (the c2d is usually exactly as fast but more expensive, t2d is a bit slower except for heavily parallel tasks and even more expensive). n2ds also get deeper reserved discounts than most other types. Their e2-medium type is unique among burstable instances in that it could theoretically maintain burst speed 2/3rds of the time. However to do that you would need to specially construct a load with 1 minute of idle to recharge before a 2 minute burst. As no workload works like that in reality you can take less advantage of continuous burst than the solutions of other providers where you generate and keep CPU credits, so in my opinion it is the least useful.
- Amazon EC2: They started the "big" cloud trend, they still have the lead, so i guess they don't need to be the best value, so Google may be a bit better for the money for most things. That said, they do have the best value in burstable instances using their own Graviton2 CPU, and I am looking forward to their Graviton3.
- Digital Ocean: Some of the best all around value to be had with their shared-cpu solutions, you don't even need to go to the "Premium" if you don't care about the extra speed of the NVMe SSD. I've been using them, so I know I like their console, backup, monitoring, alerts etc.
- Linode: They were the first cloud provider I used. They were a great value 15 years ago, and they are a great value still. I do have an objection, while their older Naples instances are a decent value, they are at a whole different class of performance compared to their newer Rome instances, so the fact that they cost the same and you don't get to choose is frustrating. I am suspecting many users have realized this and tried to spawn multiple instances to keep the Rome ones, as right now it is very unlikely to get a Rome to spin up in the US or EU regions. I love the simple pricing structure, but if they separated Rome at, say, a 20% price increase, they would still be value leaders and have a product that makes more sense. Like Digital Ocean, their Dedicated types don't offer a performance increase that is in proportion to their price, so are less interesting - but they do guarantee they maintain their performance at all times.
- Microsoft Azure: From a simple VM perspective, the Azure cloud seems to work very well. Decent management console, the VMs themselves perform very well, they are just not among the cheapest usually.
- Alibaba ECS: Overall Alibaba seems to offer the lowest value (except perhaps their burstable type), and I have to say their interface is the clunkiest too. They are popular in China and their more interesting AMD and ARM types are only available there, but I didn't manage to try them.
- Tencent CVM: It felt overall smoother than Alibaba, and I did manage to try their China region options, which are again the most interesting, especially the Altair Altra SR1. They have promised to offer reserved discounts soon, which should make them even more competitive, but they really have to get their best types outside China to make a difference for western customers.
GCP Addendum: The "slow" AMD EPYC core problem
As I already made clear, there's something funky going on with GCP's AMD instances. For every Milan or Rome instance (I tried 2x to 8xvCPUs), 1 of the vCPUs (or sometimes 2 for 2xvCPU n2d Rome and t2d) seems to be slow. It depends on the workload, but slow means about 20% for Geekbench, over 30% for DKBench, with some individual benchmarks more affected (over 50% for DKBench's prime, over 65% for Geekbench's AES-XTS!).
Running ./prime_threads.pl on such a 4xvCPU you get something like:
root@dkbench-nd2-4> ./prime_threads.pl -i 20
Perl version v5.32.1
Finding primes to 10000000 on 4 threads, 20 iterations:
2: 1.840
1: 1.840
4: 1.896
3: 3.165
5: 1.783
6: 1.784
7: 1.833
9: 1.789
10: 1.788
11: 1.850
8: 3.136
12: 1.798
13: 1.797
14: 1.831
16: 1.786
17: 1.786
18: 1.849
15: 3.042
20: 1.356
19: 1.522
Min: 1.356 Max: 3.165 5%: 1.522 95%: 3.136 Avg: 1.974 STD: 0.494root@dkbench-nd2-4> taskset 1 ./prime_threads.pl -t 1 -i 1
Perl version v5.32.1
Finding primes to 10000000 on 1 threads, 1 iterations:
1: 1.279
Min: 1.279 Max: 1.279 5%: 1.279 95%: 1.279 Avg: 1.279 STD: 0.000
root@dkbench-nd2-4> taskset 2 ./prime_threads.pl -t 1 -i 1
Perl version v5.32.1
Finding primes to 10000000 on 1 threads, 1 iterations:
1: 2.616
Min: 2.616 Max: 2.616 5%: 2.616 95%: 2.616 Avg: 2.616 STD: 0.000
root@dkbench-nd2-4> taskset 4 ./prime_threads.pl -t 1 -i 1
Perl version v5.32.1
Finding primes to 10000000 on 1 threads, 1 iterations:
1: 1.261
Min: 1.261 Max: 1.261 5%: 1.261 95%: 1.261 Avg: 1.261 STD: 0.000
root@dkbench-nd2-4> taskset 8 ./prime_threads.pl -t 1 -i 1
Perl version v5.32.1
Finding primes to 10000000 on 1 threads, 1 iterations:
1: 1.265
Min: 1.265 Max: 1.265 5%: 1.265 95%: 1.265 Avg: 1.265 STD: 0.000| Type | n2d-s2 (M) | n2d-s2 (R) A | c2d-2 (M) | t2d-s2 (M) |
| Geekbench5 fast CPU | 1251 | 970 | 1266 | 1150 |
| Geekbench5 slow CPU | 979 | 788 | 986 | 893 |
| DKBench fast CPU | 105.9 | 137.76 | 104.14 | 113.55 |
| DKBench slow CPU | 158.93 | 188.53 | 157.67 | 173.9 |
| perlbrew fast CPU | 828.5 | 930.6 | 793.8 | 856.3 |
| perlbrew slow CPU | 981.8 | 1100.5 | 950.5 | 1047.5 |
Essentially, Google's Milan cores are scoring in the 1200s or at least the 1100s on Geekbench, except 1 (or 2) of them per instance, which turn into 900s CPUs or worse - which is a previous-gen Rome class result. These instances with a sort of "crippled" core are still the best value for Google's cloud, but you have to be careful so that you don't get a t2d-s2 where both CPUs are "slow" (same can happen with Rome n2d, but I assume you will always opt for the Milan for the same price).
It is interesting actually to see how a t2d with 1 compromised CPU compares to a t2d with both CPUs compromised compare on Geekbench 5. Some benchmarks, like the AES-XTS and SQLite show vast differences (over 200% faster for the "healthy" core), while others seem unaffected.
I tried the LMbench microbenchmarks to see if there was any difference in the memory latency timings, in case the slow core doesn't get access to all the caches etc, but all the LMbench memory, latency, etc benchmarks gave similar results for fast vs slow cores, apart from libc bcopy and memory bzero bandwidth, which reported over twice the bandwidth for the non-affected CPU for the first 512b - 1k, with the slow CPU slowly catching up after the 4k mark:
fast vCPU slow vCPU libc bcopy unaligned 0.000512 74850.98 0.000512 39376.69 0.001024 102429.05 0.001024 56302.91 0.002048 104352.51 0.002048 74090.38 0.004096 108161.33 0.004096 90174.68 0.008192 97034.51 0.008192 85216.90 0.016384 99009.57 0.016384 93743.92 0.032768 54218.61 0.032768 52910.72 0.065536 53300.89 0.065536 49660.89 0.131072 50072.18 0.131072 51533.84 libc bcopy aligned 0.000512 82067.77 0.000512 38346.13 0.001024 103010.95 0.001024 55810.31 0.002048 104568.18 0.002048 72664.92 0.004096 105635.03 0.004096 85124.44 0.008192 91593.23 0.008192 85398.67 0.016384 93007.97 0.016384 91137.35 0.032768 51232.94 0.032768 49939.64 0.065536 49703.80 0.065536 49675.92 0.131072 49760.35 0.131072 49396.37 Memory bzero bandwidth 0.000512 83182.36 0.000512 43423.32 0.001024 95353.76 0.001024 61157.60 0.002048 103437.22 0.002048 76770.77 0.004096 70911.40 0.004096 61986.23 0.008192 84881.63 0.008192 77339.78 0.016384 95343.37 0.016384 87949.77 0.032768 97565.34 0.032768 91436.64 0.065536 93136.11 0.065536 89826.23 0.131072 95790.48 0.131072 90689.07I do not know what this actually means though, or how could it could be happening. Is it some sort of bug in Google's hypervisor? Why can't I find any discussion about it when googling it, surely such an easily reproducible performance issue should have been noticed by others, and at least by google engineers?
I did verify it is not anything special about the Debian Bullseye image I was using - I could reproduce on CentOS, Buster, latest Ubuntu as well, can't think of anything else to try.
Update - Google response:
Google's official response to my ticket:
I believe the behaviour that has been captured here is the underlying Compute Engine resource that Google Cloud uses within its hypervisor to run essential networking and management tasks. As a result of this component, CPU may not be able to reach 100% on all cores. Smaller instances may see this more so due to the relative size of the component to the size of the machine.
The overall stance of this symptom at this time is that this is part of the infrastructure and working as intended. You're welcome to choose other CPU architecture types, or use use a larger machine type; either of these should make up for the overhead which is taken up by the hypervisor resource. I've still forwarded your findings, reproduction steps and comments to the Compute Engine team for their record.
I get it that the hypervisor needs to allocate some resources for networking etc, but it does not start to explain why it is only AMD EPYC instances that exhibit it this way, why it randomly affects 1 or 2 specific vCPUs and more crucially, why it is specifically detrimental to small data writes (at 1/3rd the bandwidth). So, I continue to suspect a hypervisor bug, I mean, it possibly has to do with how it handles some tasks while virtualizing the cpus, but it should not behave this way.
Update 2:
The issue was addressed almost a year later - by November 2022, n2d and t2d instances had all cores at full performance (c2d still had issues though).
 Computer scientist, physicist, amateur astronomer.
Computer scientist, physicist, amateur astronomer.
Thanks! I'll be poring over this for days.
First, thank you for your opinions and analyses.
I think maybe DigitalOcean and Linode disable the HIT on the shared nodes because of concern about Spectre, they are all Intel cpus.
As it takes price in consideration, it would be nice to see benchmark of OVH public cloud servers (not to be confused with VPS offers, they have some simple VPS similar to DreamHost, but they also have the public-cloud based on openstack, the backend for their K8S offer).
Vultr also has some good price/performance, but recently UpCloud with their AMD instances are beating then. Each month I read the post on the Josh blog, comparing different providers with some benchs, it's worth a look
https://joshtronic.com/2022/04/03/vps-showdown-digitalocean-lightsail-linode-upcloud-vultr/
For me, Vultr has a special place on my heart, because it now has a good offer for Sao Paulo compared to AWS/Google, that was the only reliable option I had here.
I'm currently using OVH VPS for archived projects, Linode 4GB for new projects, Vultr on Sao Paulo in projects that latency matter, DigitalOcean for k8s projects (they had it before Linode/Vultr)
Thanks for the comment. The reason I included just Linode and Digital Ocean from the "smaller" providers, is because they have good reputation (Linode's been around for almost 20 years now) and I personally have good experience with them. I have heard several horror stories about Vultr (downtime etc), so I've never felt like giving them a go. I should probably have included OVH though, maybe I'll do a second part. Don't know much about UpCloud.