My Perl Conference in Amsterdam Takeaway
Inspired by domm, I'm posting my takeaway of the Perl Conference in Amsterdam (which I wanted to present in-house anyway):
- First up, I was heavily impressed by the hospitality and friendliness of the organizers! They really created an environment to feel welcome - I'm sure, the great coffee and good sandwiches played an important role.
- The organizers did a really good job in figuring out the schedule, allowing for up to four different talks in parallel, to always have talks relevant for me, while converging everyone in the main hall for must-see talks.
- Damian Conway is working to get the Perl 6 class syntax to Perl 5 with Dios. For the syntax, he has to expand the Perl 5 parser, which can be done since 5.12/5.14 using C code, or by using Lukas Mai's Keyword::Simple using Perl code. The challenge is that either technique requires that you process the following Perl source code by yourself, and do the rewriting that you want to achieve. Parsing could be passed to the existing PPI module, which creates a syntax tree for you - and is therefore slow. To make it run fast, Damian created Keyword::Declare, which uses his new module PPR containing a single regexp grammar that can successfully parse any Perl source code! You have to see this 1600+ line beauty for yourself.
- For such a regexp beast to be debugged without going bananas, you'll need Regexp::Debugger
- Acme::LooksOfDisapproval finally allows me to express my feelings towards some of our codebase
- if you ever need to build an OAuth2 server, Lee Johnson's Net::OAuth2::AuthorizationServer is the way to go
- last time I checked, I didn't find any JSON Web Token implementations - by now, there are a few, including Crypt::JWT and domm's plack middleware Plack::Middleware::Auth::JWT
- Leon Timmermans is working on a successor of Module::Build and Module::Build::Tiny: Dist::Build, not yet available on CPAN.
- If you "just" want to compile Perl and install it into a non-standard location, use Perl::Build
- if you use DBI, the module DBIx::LogAny will help you produce proper logs of your database activities
- Larry Wall reminded us that it doesn't matter how long something took to complete, once it's done - think of the Tolkien books. And, that he was the only one who wasn't supposed to burn out during the 15+ years of Perl 6 development.
- domm reminded me that I don't know any of the modern SQL like Common Table Expressions and Window Functions.
- Bart Wiegmans showed how mere mortals can improve the Perl 6 JIT compiler
- there are alternatives to cpanm, including cpm that installs in parallel
- mst wrote opan as a way to have a "small" CPAN mirror with private distributions (a.k.a. darkpan)
- metacpan now allows you to grep through all of CPAN with grepcpan
- I haven't come across OpenAPI specifications so far, so thanks to Lee Johnson for pointing me at APIs.guru
- Paul Evans showed his impressive work on the async and await keywords, implemented in Future::AsyncAwait, to finally make code using Futures neat. Cant' wait till this gets out of alpha...
- Damian impressed us by doing quantum mathematics using Perl 6
- Steven Little works on Moxie, a successor of his Moose object system, but this time suitable for inclusion in the Perl 5 core. Where Moose creates data structures for all the meta things it does, Moxie tries to achieve the same things with minimal startup and memory overhead, by introspecting what is already there. Looks very promising to me! I like the fact that constructors are now strict by default, and that appending a question mark to the name makes them optional - however I think it would be great to be able to specify the rw/ro attribute within the has statement.
- For programs that grew out of shell scripts, IPC::Run3::Shell will make them feel more shell-script-like again
- Flávio Glock made our heads explode when presenting his work on Perlito. He is able to compile Perl 5 and Perl 6 code to other languages, including Perl 6, Perl 5, Javascript and Java. It can even translate itself, so you can have a stand-alone Perl interpreter in a browser. Wow!
- Sawyer presented the new features of Perl 5.26. Most important for me are stable lexical subroutines and indented here-docs. In addition to 5.24's stabilization of postfix dereferencing, it's time to upgrade at $work!
- For database update handling, use domm's DBIx::SchemaChecksum or sqitch
- Ovid reminded us that unittest code is real code, and needs to be cared for properly. Thus, use his Test::Class::Moose (we already do in many projects). He also showed his addon Test::Class::Moose::History to track test history over time, which hasn't made it to CPAN yet.
- Finally, I'm satisfied with how my Adding Structured Data to Log::Any talk worked out - it actually seemed to make sense to some people. I even noticed a few pictures of my slides being taken - I wasn't expecting that... Now I'm impatiently waiting for the video to be uploaded to Youtube - thanks Sawyer for doing this enormous chore. After my talk, I was pointed to fluentd and graylog, which I'll have to look into now.
Thanks a lot for organizing the conference, Amsterdam.pm and AmsterdamX.pm, I'm looking forward to seeing you all in Glasgow.
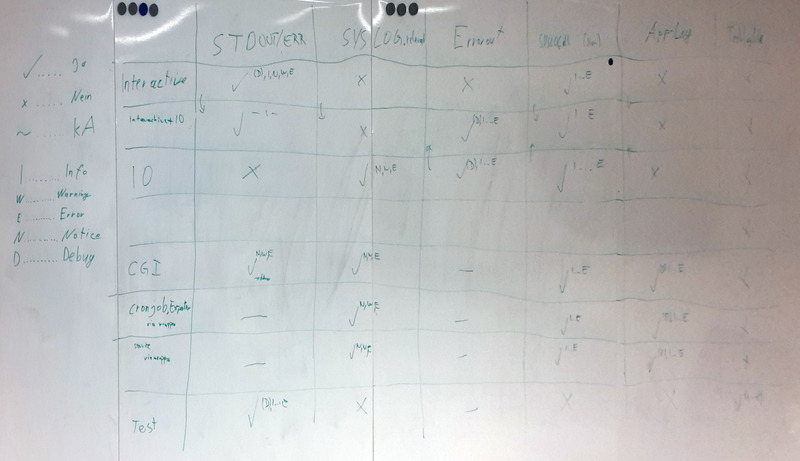 - in order to find out where we expected our log output to end up in. Sounds stupid, but when you start to discuss that topic, the complexity unfolds in front of your weary eyes.
- in order to find out where we expected our log output to end up in. Sounds stupid, but when you start to discuss that topic, the complexity unfolds in front of your weary eyes. Perl developer based in Vienna, Austria.
Perl developer based in Vienna, Austria.