Our Adventures in Logging
NB: I've written a follow-up post
Before we start: this is my first post at blogs.perl.org. Awesome that you're reading it despite me being a noob! :)
Three years ago, I started to change the way I think about logging in applications. Before that, to me it was just printing lines into text files, in order to later read and grep my way through them.
Then, a friend pointed me to ElasticSearch and Kibana, with its infinite ways to search through, and visualize, large amounts of textual data. Due to the nature of my $work, I was well aware of the benefits of a full text search database, however, it soon became clear that text alone was only part of the deal. The real fun in ElasticSearch begins when you add structured data into it, allowing filtering, grouping, and get all businessy with pie charts and world maps and whatnot. This would be where you'd start to gain knowledge that wouldn't be available anywhere in text-based logfiles.
At around the same time was the Austrian Perl Workshop in Salzburg, where Tim Bunce held a great talk called "Application Logging in the 21st Century". Watch it now, I'll wait! It's worth your time...
Besides being really inspiring, he showed that I had all the components in place I would need to perform intelligent, context-aware logging. We had an ElasticSearch installation, Kibana running, and our applications produced tons of logfiles, so there was a real itch to scratch. We should be able to feel improvements in no time.
Then hit reality. We would have to rewrite 200.000 lines of application code to produce structured output, which would take our four-person-team a bazillion years to complete. Besides, how is that code supposed to look like, what mechanism should it use? Most code just called print wherever the programmer saw fit. Obviously a long way to go...
Pushed by the same friend again, we started to use Log::Any for a greenfield project, and after a few rounds of getting it wrong, it started to feel like the right thing to do: Just using $log->error, $log->warn and friends in our module code, and not caring about where the application wants the output to go to. So just let the application configure the Log::Any::Adapters.
Oh, did I mention that our system was split in over 500 applications? We started configuring the Log::Any::Adapter in situ, but soon realized that getting this consistently the way we wanted it to be was an impossible feat. And what's even worse, when you change a module to use $log->error, but it is used by some application that didn't set up the Log::Any stack (yet), the less-than-awesome default logger "null" will happily swallow all your error messages, never to be seen again.
So we got back to the drawing board, literally
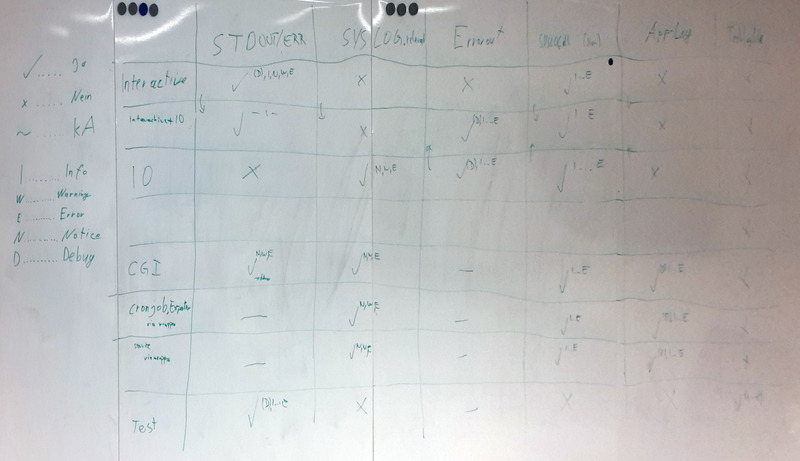 - in order to find out where we expected our log output to end up in. Sounds stupid, but when you start to discuss that topic, the complexity unfolds in front of your weary eyes.
- in order to find out where we expected our log output to end up in. Sounds stupid, but when you start to discuss that topic, the complexity unfolds in front of your weary eyes.
Once this was cleared, one of our colleagues implemented a module that would, upon import, sense the context the program was executed in (e.g. interactively, as a daemon, as a CGI, as a cronjob, as a unittest, you name it), and configure the Log::Any stack accordingly, as specified on the whiteboard. This was a tremendous step ahead, now the application just needed to add a single line, and logging would happen exactly the way we wanted it to be. Mission accomplished.
Still, no structured data to be seen anywhere, still just plain old stupid lines of text. The Logstashy way would probably be to write parsers in Ruby to extract the structured data out of our logged text. However, that feels really wrong to me - writing parsers for unstructured plain text. This might be feasible for well-known log formats like Apache's access logs, but not for whatever comes out of our 200.000 lines of legacy application code happily printing into whatever log file happens to be around.
Instead, what we really want to do is specify additional context data in the spot where we perform the logging, and have the Log::Any adapters figure out what to do with it. So instead of:
$log->errorf('Failed to find element %s in file %s', $elem, $file);
I'd prefer to write:
$log->error('Failed to find XML element', {element => $elem, file => $file, pid => $$, program => basename($0), weather => 'shiny'});
It hold the same information, but now has structured data which can directly be inserted into ElasticSearch, giving you the shiniest histogram ever drawn of the top missing XML elements per zodiac. Since we were already using our own implementation of a Log::Any::Adapter, it shouldn't be difficult to get this to work, right? Wrong, because before your adapter even sees a log line, Log::Any::Proxy goes ahead and flattens all your arguments into a single string.
In our desperation, we created a local fork of Log::Any::Proxy that refrains from doing so - but now we're doomed to always use our Proxy and our adapter, so this is not an agreeable situation.
Last week, the same friend again showed us a small Go program he'd developed for us. I was taken away by the Go way of logging structured data (actually, the Logrus way) - if you don't know it, take a look at Logrus' withFields. Now this is even ways cooler than what I dreamed up. Now with that I would be able to say:
use Log::Any '$log';
$log->context->{pid} = $$;
sub init {
$log->context->{weather} = 'shiny';
}
sub parse_xml {
my ($fn) = @_;
local $log->context->{file} = $fn;
...
$log->error('Failed to find XML element', {element => $elem});
...
Is it possible that this idea didn't yet come to anyone in the Perl community? Of course not, as I found out upon researching: Log4Perl has something it calls Mapped Diagnostic Context - so no reason the be green-eyed towards Go.
However, I failed to find this in the Log::Any world. Am I missing something? If not, then it's time to write the first Log::Any Enhancement Proposals this small world has ever seen:
LAEP 1: Pass hashref as last argument of log functions on to supporting adapters
Extend Log::Any::Proxy to know whether his adapter is aware of hashrefs. If it isn't, then continue to work as today. If it is, pass the last argument, if it is a hashref, on to the adapter, so it can process it as it pleases.
Adapters would need to register their ability with the Log::Any stack - I'm sure we'll find a pretty way to do so.
LAEP 2: Expose an API to Log::Any for modules to add (localized) context data
Add an API to Log::Any that exposes a way to add, modify and remove context data. Make sure you can add in a localized way, so that you don't have to remove manually at the end of a block. For every call to a log function, add all the context data to the log line. If the adapter in use is hashref-aware, merge the context and the log line's hashref before passing it to the adapter. If the adapter is not hashref-aware, treat the context like it were specified in the log line, i.e., Data::Dumper its key-value-pairs onto the end of the log line.
LAEP 3: Change the default Adapter from Null to Stderr
I don't know what the original intention was in choosing this default, but it really bit our ass several times since we started to use Log::Any. Once you have a large enough codebase with many entry points (i.e., applications) sharing the same modules, starting to use Log::Any in any of your modules before all your applications have started to setup a Log::Any stack is the only way to assure that you don't start missing log output. If I would have known this beforehand, this would have been a no-go for Log::Any. To me, logging to Stderr would be the POLA thing to do, unless configured to do otherwise.
So long, thanks for staying with me for this long post. I hope I was able to get my point across - now I'm really curious on what you think regarding these three proposals. Please go ahead and use the comments section. If the general feeling toward this is positive, and if the Log::Any folks are in favor, I might even try to come up with a pull request for the ideas... Future me... Enjoy your weekend.
 Perl developer based in Vienna, Austria.
Perl developer based in Vienna, Austria.
Are you going to propose these on the Github project? There are already some enhancement proposals on the Github issues list.
For example, your second proposal is https://github.com/preaction/Log-Any/issues/46. Your first proposal is also covered by https://github.com/preaction/Log-Any/issues/46, but Adapters would be required to handle it themselves (which involves a bit of work in each Adapter).
Your third proposal is a non-starter: Log::Any has always claimed to be low-impact so that logging can be added to CPAN modules without disrupting the code using them. You must opt-in to logging. But, see also xdg's response: http://www.dagolden.com/index.php/2692/response-to-our-adventures-in-logging/
I also use Log4perl quite a bit, and wish that something like Nested Diagnostic Contexts and Mapped Diagnostic Contexts were available to Log::Any (more likely a combination of the two), but I've had trouble finding a correct way to do that while maintaining maximum compatibility across all the adapters along with a sane fallback.
FYI, xdg has posted a response here: http://www.dagolden.com/index.php/2692/response-to-our-adventures-in-logging/ (He can't use the comments here.)
And a personal note: Logging to STDERR by default would be extremely astonishing to me. It is bad enough that people do this accidentally, and make it impossible to usefully tease apart when capturing program output what indicates error and what is just processing noise. Making it a default would make it a certainty that non-error output appears on STDERR in even more software.
Please use STDOUT for logging by default.