Its just a extend even more post-ette day here in the Moose Pen
Well going to start on another test case today this time '30_where_basic.t'. Now I do not have to test some of the more basic 'where' conditions as I have already proved that they work from all the other tests cases that use them so what I am going to start out with today is a function as part of a condtion;
In my previous monthly report for May 2018, I mentioned that it was the best month ever since I started contributing. So the obvious comparison, did I do any better this month?
In short, it was not as good as it was last month. However, under the given circumstances, it was satisfactory. You might ask how do I rate my own performance. Some of the criteria are as below:
Pull Request
Git Commits
Pull Request Challenge
Perl Blog
PerlWeekly Newsletter
Adopt CPAN Module
Lets do the comparison.
Pull Request
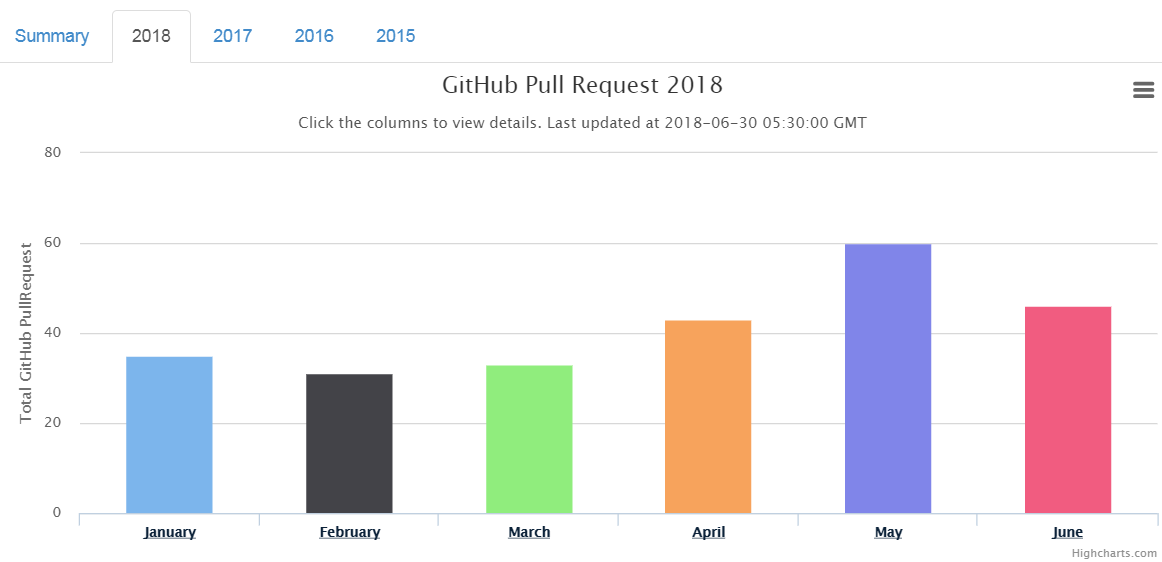
Last month, June 2018, I submitted 46 PR as compared to 60 PR in the month of May 2018.
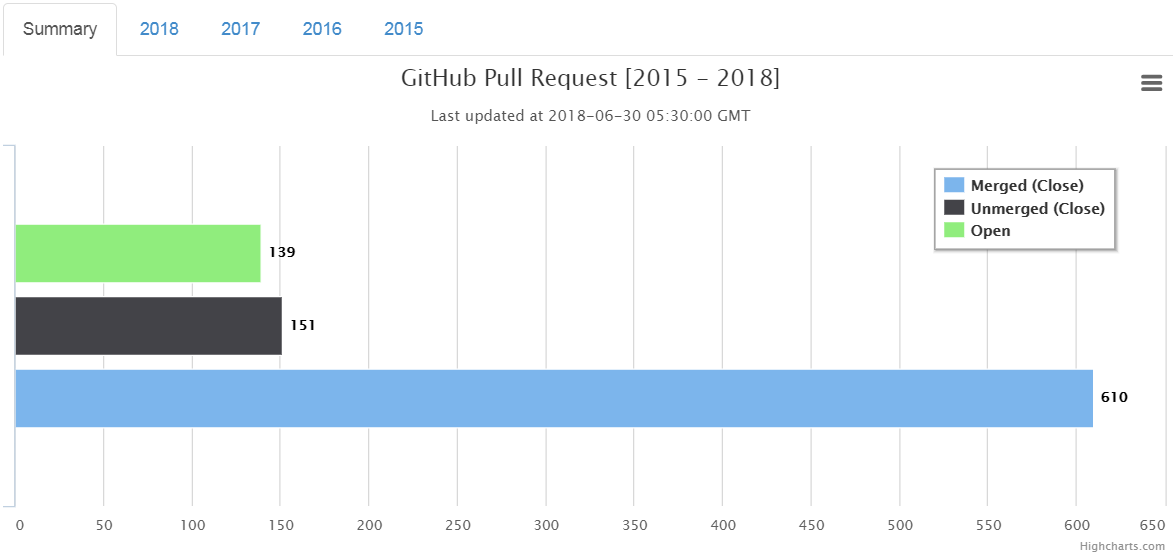
Overall so far, I have submitted 900 PR. The target is to reach the milestone of 1000 PR before the next London Perl Workshop in Nov 2018 looks promising with current speed.
Git Commits
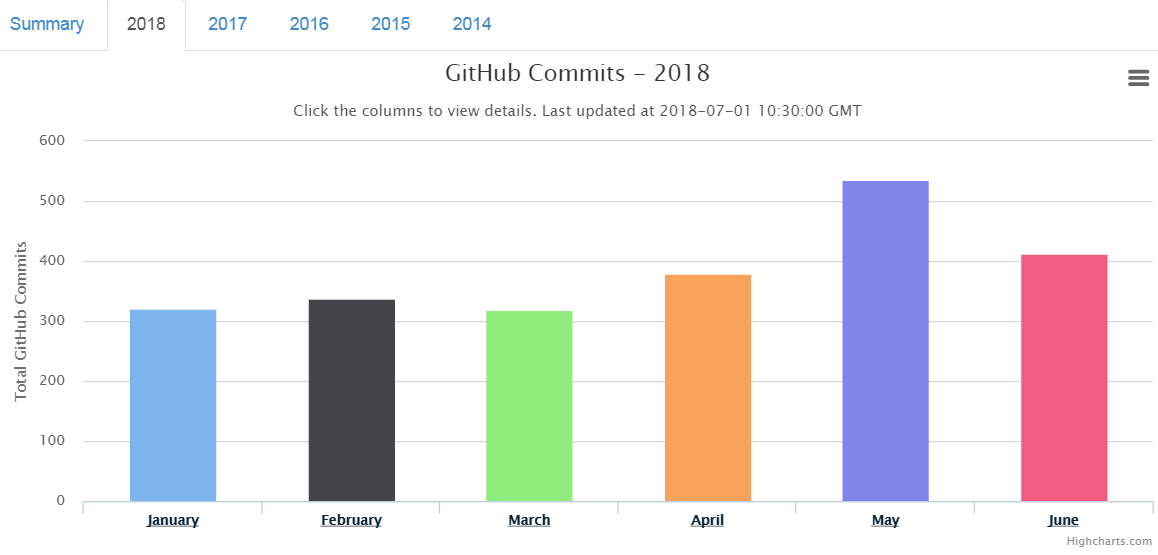
Last month, June 2018, there were 412 commits as compared to 536 commits in the month of May 2018.
Recently GraalVM 1.0 been released which can run Ruby, JavaScript and other dynamic and static languages on top at super fast speeds.
I have decided to see how Perl 6 will run on top of it.
If successful that should allow us to run Perl 6 hopefully very fast and use Java, Ruby and JavaScript libraries without paying a interoperability price.
Truffle which is what we are using is a language implementation frameworks that creates an efficient JIT from a (sufficiently annotated) AST interpreter written in Java.
Why stop a habit and as usual ona Saturday I am goting to to a quick post on the current state of the test suite for Database::Accessor and Briver::DBI.
After missing a year last year, I came back to attend YAPC this year. (Yes, yes: “The Perl Conference,” now. But it’ll probably always be “YAPC” to me.) And I actually spoke again (second time), this time on dates and my Date::Easy module. If you missed it and are interested in watching it, the video is up.
This year was in Salt Lake City again, and, while I normally don’t like repeating cities (mainly because I like visiting new places instead), I do have to say the Little America Hotel is every bit the excellent venue that I remembered. Plus it’s just barely close enough to where I live that I can drive there and take the whole family, and do a sort of “conferenscation.” Which is what we did.
A group of Perl companies are sponsoring the COED:ETHICS conference, a one-day conference on ethics for developers and technologists, which is in London on July 13th.
For the past decade or more, perldoc.perl.org has been a useful and convenient resource for viewing perl documentation online. However, it has suffered from lack of maintenance and mounting unfixed issues over the past few years. Being familiar with the excellent Mojolicious documentation site and how it also can display core perldocs, I reasoned that such features would be simple to provide in this modern framework. And so, what would become perldoc.pl (thanks to a domain acquired by pink_mist) was born.
Today I am just going to carry on with a few 'xt' tests in my '25_exe_array.t' test case. Now I started out wanting to do an update with the execute array so I came up with this test;
$da->reset_conditions();
my $update_people = $people->update_people_data();
my $updated_people = $people->updated_people_data();
ok($da->update($dbh,$update_people),"Update Four New Users ");
ok($da->result()->effected == 4,"Four row effected");
Fortunately before I ran this I realized that the above is not going to do what I expect it to do. I think it will just update all the rows in the db four times each wilt an sql like this;
Many people moved from GitHub to GitLab after annoucing that microsoft bought GitHub. So did I.
After some initial problems with the settling in, it works quite well.
GitLab and the integrated CI is very useful to automatically upload your projects to CPAN if all tests are positive.
The steps are quite simple:
1.) Start with some project on gitlab. It doesn’t matter which one.
2.) On gitlab you can configure the some ci settings in your project
"A lot has been written about parsing left recursion. Unfortunately, much of it simply adds to the mystery. In this post, I hope to frame the subject clearly and briefly."
How can we use long lists of symbols from an imported package and still keep the code readable?
I usually prefer use statements of the form:
use My::Module qw(symbol1 symbol2 symbol3);
Except for specially understood modules, like Moose and Test::More, I don't like to just import everything. Rather I like to explicitly call out only the specific symbols I need.
But what if you need to:
use My::Module qw(
symbol1 symbol2 symbol3 symbol4 symbol5 etc and so many symbols
that it takes up several lines all the time in every package
that uses it
);
Back into extended test mode here in the Moose-Pen;
Time to get back to some more practical tests as I have been side tracked by a few API issues. Just to re-cap the practical tests are found in the 'xt' dir and I am using them to test Driver::DBI against a real DB. So far this practical testing has sniffed out a whole lot of bugs and I am hoping to sniff out a few more.
Today I am am going to play with the DBIs 'execute array' this should be totally transparent to the end user all I need to do is pass an 'Array-ref' into my $da as the container and DBI::Driver should do the rest.
With upcoming version 0.2.0 swat removes usage of prove as internal test runner. There are some -minor- breaking changes due to this. For those who uses swat I would recommend to read GH pages docs and in case you'll need help with migration of your project to the latest swat version don't hesitate to contact me.
If I were to pick the most ubiquitous construct in the Perl 6 programming
language, it'd most definitely be the colonpair. Hash constructors,
named arguments and parameters, adverbs, and regex modifiers—all involve the
colonpair. It's not surprising that with such breadth there would be many
shortcuts when it comes to constructing colonpairs.
Today, we'll learn about all of those! Doing so will have us looking at the simplest as well as some of the more advanced language constructs, so if
parts of this article make you scratch your head, don't worry—you don't
have to learn all of it at once!
PART I: Creation
Colonwhaaaa?
The colonpair gets its name from (usually) being a Pair object constructor
and (usually) having a colon in it. Here are some examples of colonpairs:
It has been a long running battle between myself,m the API and the the 'Link' objects. A number of posts over the past few weeks have been dealing with how to handle the 'view' for the various elements on link.
Today I started down the path of enforcing the API rule that all 'elements' in a link must have a view. So given this link;
Being lazy, I thought to myself, "when using the web interface, why should I need to add my country to the query?". So, using CGI::Lingua which is already available via the VWF system used to build the site, you longer need to do that. From the US, try this:
The bonus deliverable "Perl 6 Numerics" Language documentation page was
merged to master. It describes all of the available Perl 6 numerics, their
interactions, suitability, and hierarchy.
The newest post on the "Ocean of Awareness" blog is
"Marpa and procedural parsing"
: Marpa's procedural parsing is more flexible and more powerful than recursive descent's.