AWS Lambdas & Perl Teaser
Just pushed version 0.0.1 of a framework for creating Perl Lambdas. Sort of a POC and WIP...comments welcome.
https://github.com/rlauer6/perl-Amazon-Lambda-Runtime
Just pushed version 0.0.1 of a framework for creating Perl Lambdas. Sort of a POC and WIP...comments welcome.
https://github.com/rlauer6/perl-Amazon-Lambda-Runtime
We are chuffed to announce The Swiss Perl Workshop 2019. This year the workshop will return to Olten, the venue that hosted the workshop in both 2014 and 2015. The workshop will be held in English, although of course other languages are welcome.
We are yet to decide on a date and have three options:
We have decided to take the Swiss approach and ask the people. So if you plan to attend this year's Swiss Perl Workshop please let us know which date you would prefer using either this link or the embedded poll below. The survey will remain open until the end of February.
Please spread the word, register, submit talks, and come enjoy a perl workshop in the cosy Flörli Olten.
We are looking for more sponsors. Interested? Please check the sponsoring page.
In this fourth article we will now use SSH connection and SSH public keys to give access and also limit access to our repositories.
http://www.koivunalho.org/blogs/exercises-in-integration-and-delivery/private-repository-part-4.html

My start of the year 2019 wasn't very good. I welcome the new year with Flu, suffered till nearly the end of the month. One thing I missed last month was "Pull Request Challenge". No more email from Neil Bowers with random distribution for the month. Thanks to "Pull Request Club", I was still able to contribute.
Let's take a quick look through.
65 Pull Requests submitted in the month of January.

1518 Pull Request altogether.
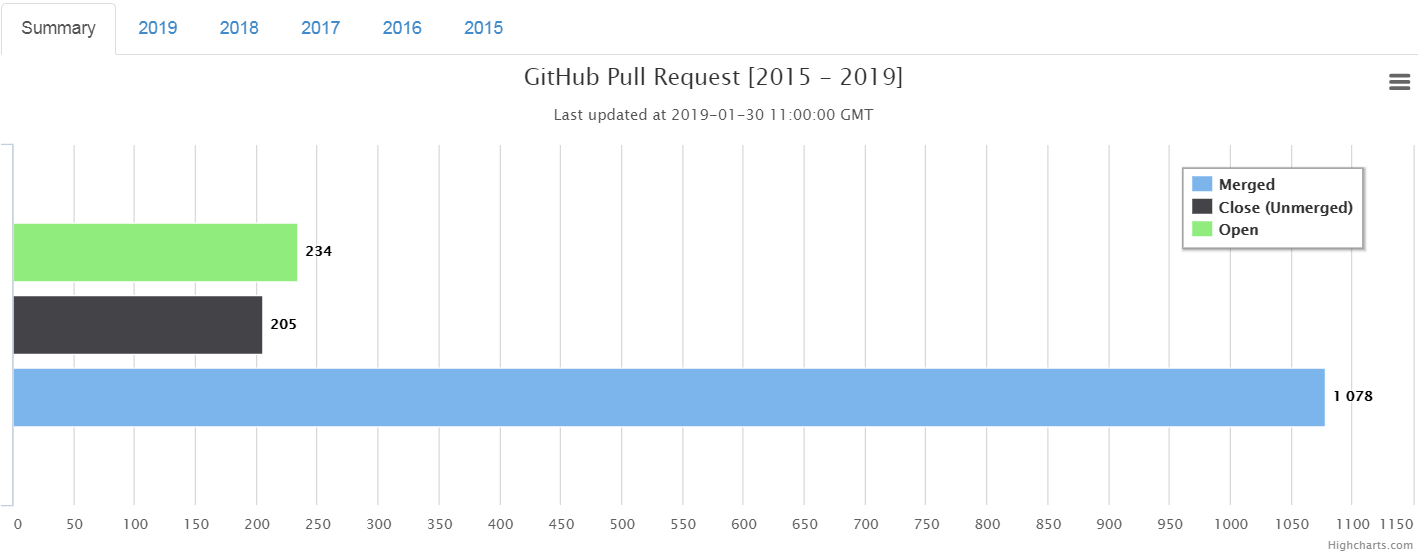
491 commits recorded in the month of January.
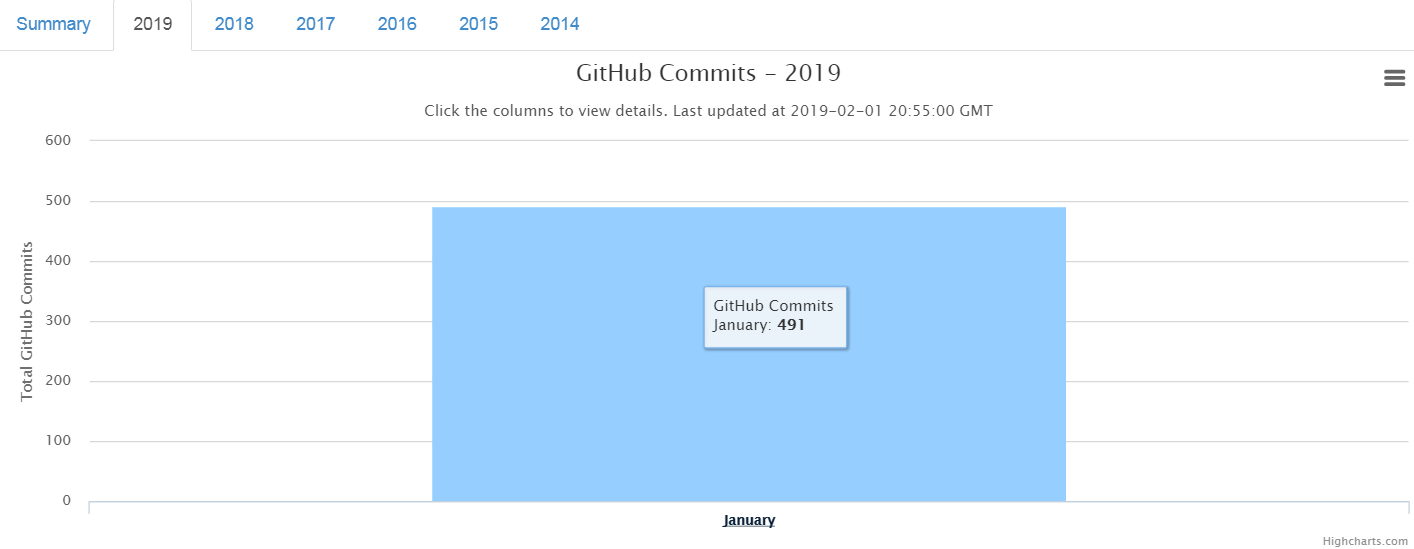
Overall 491 commits recorded so far in the year 2019.
Last month, I received OPAR and I submitted 1 Pull Request. It has already been accepted and merged by the author Renee Baecker.
Last month, I blogged about the following topics.
Last month, I prepared 2 editions of The PerlWeekly newsletter i.e. Issue 390 and Issue 392.
None.
This is a public service announcement.
By now, everyone has heard that HTTP/3 is coming. Based on Google's QUIC protocol that began as an experiment circa 2012, IETF QUIC and HTTP/3 are likely to become standards this year.
My employer, LiteSpeed Technologies, has been actively participating in the standardization process. We have also open-sourced several of our C libraries, QUIC Client and QPACK among them.
It would be cool if Perl were one of the first to get its own HTTP/3 or QPACK library. This is a call for a volunteer -- someone who is looking for a new project that is sure to get a lot of mileage. I would be glad to help augment our libraries to facilitate this process.
- Dmitri.
I'm not positive about this, but I'm not sure that things are behaving as I would expect. What would you expect the following lines to output?
perl -E 'say "x"; say -"x"; say -"-x"; say -"+x";'
For me, lines 1 and 2 make sense. Lines 3 and 4 are different than I would expect, but I'm not sure that they are really wrong. Does somebody want to explain what is really happening, and why it is that way?
Type::Tiny is probably best known as a way of having Moose-like type constraints in Moo, but it can be used for so much more. This is the seventh in a series of posts showing other things you can use Type::Tiny for. This article along with the earlier ones in the series can be found on my blog and in the Cool Uses for Perl section of PerlMonks.
For small projects, the type constraints in Types::Standard and other CPAN type libraries are probably enough to satisfy your needs. You can do things like:
use Types::Common::Numeric qw(PositiveInt); has user_id => ( is => 'ro', isa => PositiveInt, );
I gave a talk this month to Chicago Perl Mongers about the Mojolicious web framework, the Yancy CMS, the PODViewer plugin, and the Mojolicious export command. The talk introduces a simple Mojolicious::Lite application, and adding Yancy to edit the website's content inside the app. Then I explain how to make layout templates, and how to export a dynamic website as static HTML files.
This talk comes from my series of blog posts for the 2018 Mojolicious Advent Calendar: A Website For Yancy, A View To A POD, and You Only Export Twice.
Recently I feel bless is good parts of Perl language strongly.
TL;DR: Drop my .perldb file in your home directory for a much nicer debugger experience.
The kindest thing I can say about the built-in Perl debugger is that it doesn't drink even though it's old enough to. Using it is painful but there are many things you can do to make it nicer. Heck, I even had syntax highlighting working once.
One of my major pet peeves with the debugger has been how it dumps variable data. Have you ever used it and typed "x $dbic_object" or "r" to return from a method and gotten hundreds of lines of near useless output spewing across the screen? To make matters worse, it takes a long time to dump all of that, making the slow debugger even slower than normal. It's very frustrating. Here's how to fix it.
When running the debugger, Perl loads a script named perl5db.pl and internally, when it needs to dump some variables to the terminal, it runs some code which looks like this (edited for clarity):
Type::Tiny is probably best known as a way of having Moose-like type constraints in Moo, but it can be used for so much more. This is the sixth in a series of posts showing other things you can use Type::Tiny for. This article along with the earlier ones in the series can be found on my blog and in the Cool Uses for Perl section of PerlMonks.
While Types::Standard provides all the type constraints Moose users will be familiar with (and a few more) there are other type libraries you can use instead of or as well as Types::Standard.
At re:Invent 2018 AWS announced custom Lambda runtimes. This makes it possible to create Perl based Lambdas. Although theoretically it was possible to create a Perl Lambda prior to this announcement by invoking a shell from Python for example, the new custom runtimes make it possible to use almost any language to create Lambdas.
I've been developing a Perl based custom runtime framework so that creating a Perl Lambda is pretty much as simple as:
Hi!
For those whom it may concerns Sparrow announces move to Perl6. I've have started the reddit thread to explain what and why.
Thank you
Alexey
Exciting news!
Team RPerl will be in Brussels, Belgium two weeks from now for FOSDEM 2019, the largest open source computer conference in Europe (and possibly the world). We will be present the whole weekend, helping out at the Perl booth and promoting the RPerl compiler.
Also, RPerl founder Will Braswell is scheduled as one of the main track FOSDEM speakers, on Sunday February 3rd at 2pm. His topic will be Perl 11, a philosophy that promotes Perl projects aiming to re-unify Perl 5 and Perl 6. RPerl is one such project, and there are several others as well.
You can already read more about Perl 11 in Will's interview for FOSDEM:
https://fosdem.org/2019/interviews/william-braswell/
We are looking forward to be there, meeting new people, and seeing familiar faces again!

David Farrell's Perl.com article Validating
untrusted input: numbers got me thinking, specifically about
the role of \d in sanitizing input. I am not going to talk
here about looks_like_number(), because the referenced
article covers it.
The thing is, on any Perl recent enough to be Unicode-aware,
\d matches digits, whether or not they are
ASCII. This may be a problem if you are sanitizing data for numeric
conversion, because typically conversion routines expect ASCII
digits. There seem to me to be at least two ways to deal with this:
restrict your regexp patterns to ASCII, or have the conversion routine
deal with the full range of unicode digits.
If you truly want ASCII digits for your system, there are a number of ways to restrict a regular expression pattern to ASCII.
By this I simply mean explicitly validating anything that matched
\d by also matching it against [:ascii:] in a second regular expression.
[0-9] instead of \dWhat is the status of a replacement for this blogging platform? I imagine the community as a whole is reluctant to blog in a central place because of the difficulty just logging in to this particular site.
Is there an alternative site where Perl bloggers post?
Grammars combined with actions allows to parse strings and produce something from it. It's not far fetched to say that any compressed data follow a structure that is likely 'parsed' by the corresponding decompression algorithm.
So why not using Perl 6 grammar for this kind of work? Especially a compression I am familiar with.
Nintendo used the same base compression format for their SNES games with some variant depending on the game. It's pretty straight forward and it's easy on the ~2Mhz of the SNES CPU.
It goes like that:
The last event of 2018 for Team RPerl was the Austin.pm Christmas Party. Our beloved President (AKA "Prez"), Will the Chill, gathered all of us for pizza and Perl projects.
Throughout the evening, we discussed the possibilities for us to develop the use of Perl, promote Perl jobs and Perl projects in the Austin area.
Our main ideas include:
- Hosting Hackathons for Perl projects
- Inviting a guest speaker once a year
- Teaching free Perl classes
Among our members present that evening was Jim Choate, one of the three original Austin.pm founders, along with some of the younger generation of Perl enthusiasts. The party was about the past and future of Austin Perl Mongers, in every way.
And it wouldn't be a Christmas party without a few presents, Perl presents of course! (Thanks to Wendy & Liz for furnishing some of the Perl gifts at past YAPC/TPC conferences.)

Currently I'm working to getting rakudo.js to pass (our choosen subset of tests) in Chrome rather then on node.js.
For that I'm using the karma test runner (which should also allow testing all the other browsers easily).
The way the process works is that the Perl 6 test files get compiled to JavaScript and bundled by the parcel with everything they needs to run. The bundling includes the setting, runtime and even the whole Rakudo compiler (tests use EVAL a lot).
As as side node it turns out that for debugging purposes node bundled-everything.js emulates running in the browser very closely.
http://www.koivunalho.org/blogs/exercises-in-integration-and-delivery/private-repository-part-3.html
blogs.perl.org is a common blogging platform for the Perl community. Written in Perl with a graphic design donated by Six Apart, Ltd.