Last Thursday, 28th February 2019, London Perl Mongers group organised first Tech Meet of the year 2019. Thanks to Zoopla for giving us space to hold the meet. Also for Pizzas and drinks.
In the past, I never made any effort to attend the Tech Meet. On 9th November 2017, I attended my first Tech Meet. It was to meet and greet Neil Bowers as the invitation had his name as one of the speakers. I blogged about it. Ever since, I haven't missed a single Tech Meet. It is so fun and entertaining.
This time also it was such a great event with mix of regular and new speakers. I got to meet LPW team after such a long time. Two members were still missing. Rick and Lee. Luckily, Julien and Katherine made it. Julien even gave a short talk that he is planning to give in the next German Perl Workshop as well but in German.
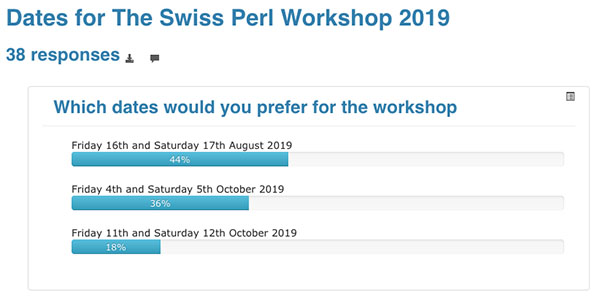
The dates for this year's Swiss Perl Workshop are now confirmed after our poll to ask interested attendees on their preferred choice:
Although the date is close to The Perl Conference in Riga, just one week later in fact, this infers some advantages: we hope to appeal to overseas visitors who are attending TPC, including potential speakers, the dates in October turned out to clash with Swiss personal and school holidays, and we will be able to use the excellent kitchen team for snacks and lunches as we did in 2015 :)
The workshop will be free to attend once again, so please, register, think about submitting a talk, and perhaps even sponsor the workshop.
A great thanks go to our sponsors, who have already committed to the event:
libusb is a highly portable library providing generic access to USB devices. USB::LibUSB was newly written in 2017 to provide Perl bindings to the libusb-1.0 API. It replaces the deprecated module Device::USB, which targeted the older and incompatible libusb-0.1 API.
This release of USB::LibUSB fixes a bug in the config descriptor data structure. Before the fix, only the first interface of a given configuration was represented. Now, the "interface" element of the config descriptor hash holds an array of interfaces, each of which consists of an array of alternate settings. Typically each interface has only one alternate setting:
my $config = $dev->get_active_config_descriptor();
my @interfaces = @{$config->{interface}};
# Get first alternate setting of first interface
my $first_interface = $interfaces[0]->[0];
Many thanks to Mike Ferrara who spotted the issue when porting code from Device::USB to USB::LibUSB.
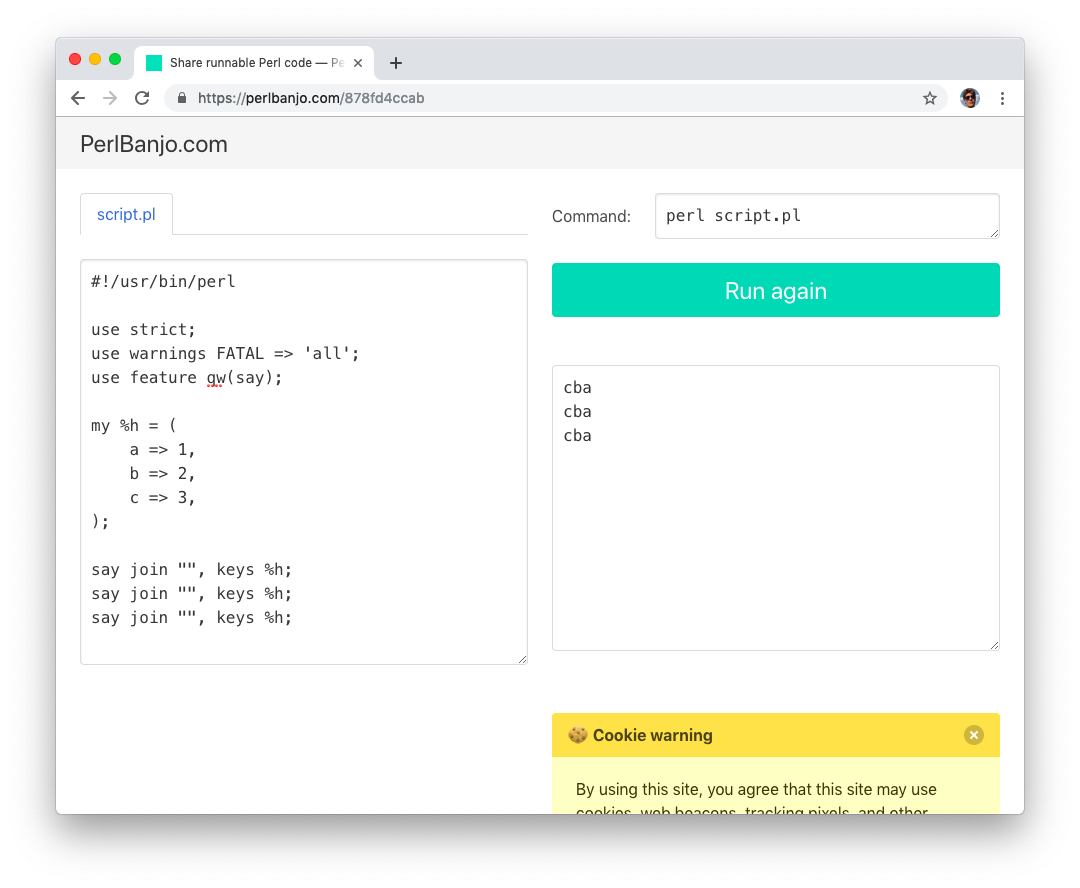
But I always missed a simple tool to share Perl code. Yes there is https://gist.github.com/ and a lot of other pastebin sites, but they just share the code without the ability to run it.
In browser you can run Perl code at http://perltuts.com, but there is no way to save your work and to share it with others. There is a tool that you can use to run & share Perl code https://ideone.com/, but it is complicated and you can't use perl one-liners in it.
Accessible rooms have been popular this year at our venue hotel. Unfortunately, sometimes people will book an accessible room when they don't actually need one. We want to make sure that those who truly need accessible rooms have the chance to book them. #TPCiP has held two more accessible rooms back just for this reason. If you need extra accommodation and haven't reserved your room yet, email admin@perlconference.us so we can help ensure you get an accessible room at the conference rate!
Ever since I received "Think Perl 6" book as a gift by Neil Bowers at the London Perl Workshop 2017, I have been planning to start learning Perl6 without any luck. I can think of many reasons why. One of the reasons was my confusion where to start. First I thought, I will start from the basics but then I easily get distracted if I don't have a target. Then I realised why not pick one of my Perl5 distributions and convert it into Perl6. That sounded great idea.
I tweeted about my intention and asked for help. Immediately two people kindly came forward, Scimon Proctor and JJ Merelo. With their guidance and support, I decided to create a basic Calculator distribution. Once I got the approval of the two mentors, I started preparing the ground.
As previously announced, Team RPerl was in Brussels for FOSDEM, one of the (if not the) world's largest open source computer conferences. RPerl creator Will 'the Chill' Braswell was one of the two Perl programmers invited as a main track speaker, along with Andrew Shitov, whose talk was about Perl 6 as a tool for language compilers.
It was my first FOSDEM, and the event was quite spectacular. It takes place at the Université Libre de Bruxelles, and is spread over several buildings full of stands, conference rooms, and dev rooms, all packed. At the Perl booth, Wendy and Liz were busy all weekend, promoting Perl as always. When I say booth, that includes the table covered in Perl books & stickers & other collectibles, plus the "Perl bookshelves" pop-ups, plus a huge Perl 6 banner, plus a giant stuffed camel... The latter of which is now in the pictures and selfies of many FOSDEM attendees.
That's right, there is one week left on our poll to choose the dates for this year's Swiss Perl Workshop. If you're a regular to the workshop, or you are thinking about attending for the first time, then make your choice known. See our previous post for the details.
A great thanks go to our sponsors, who have already commited to the event:
Taking clue from Gabor Szabo, the Chief Editor of PerlWeekly newsletter, when he tweeted last week and asked his followers what they would like to read in the next edition of PerlWeekly newsletter.
I would like to introduce "Perl Weekly Challenge" where anyone can put forward the challenge for others. It can be Perl5 or Perl6. We, developers, come across many challenges on a daily basis at work. Why not throw the same challenge and see how others would approach the challenge. Or if you have found the solution, share that as well by writing a very small blog either on blogs.perl.org or perl.com. I am sure the Chief Editor, David Farrel, would not mind to have it.
If you find writing blog is a challenge in itself then I can help you with it. Just send me the plain text and I will try to get it published on blogs.perl.org.
Ran into some issues gettng HTTPS to work with LWP in a Lambda. I blog about it here..
Amazon's assertion regarding the AMI that comprises the runtime for Lambdas is suspicious. If you launch the AMI they indicate is representative of the Lambda runtime environment you'll find that it contains openssl 1.0.2. But, actually inspecting a running Lambda environment reveals it is running version 1.0.1.
The dive into Perl Lambdas continues...mostly successful, but there are rough edges that even other languages also run into when vendoring libraries.
As part of my Perl/Lambda adventure, I wrote a make-a-perl script that provisioned an EC2 to compile a version of perl. I suspect everyone has their favorite way to compile a perl binary (either for free or not) but here's yet another way to leverage the many tools that AWS has to offer. TIMTOWTDI of course!
My blog entry of a couple weeks ago,
Untrusted Numeric Input,
dealt mainly with the problem of ensuring that supposedly-numeric input
actually consisted only of ASCII digits. One of the ways to do this was
to use the bracketed character class [0-9] instead of
\d. This was documented as being portable as of Perl 5.21.5,
and I made the statement that "I believe this behavior goes back further
..." This was clearly just hopeful hand-waving, and not very
helpful.
This blog post documents my efforts to try to quantify the
versions of Perl under which [0-9] is portable. For those
disinclined to read further, my conclusion is that [A-Z],
[a-z], [0-9], and their sub-ranges are
portable among character sets as far back as Perl 5.8.0.
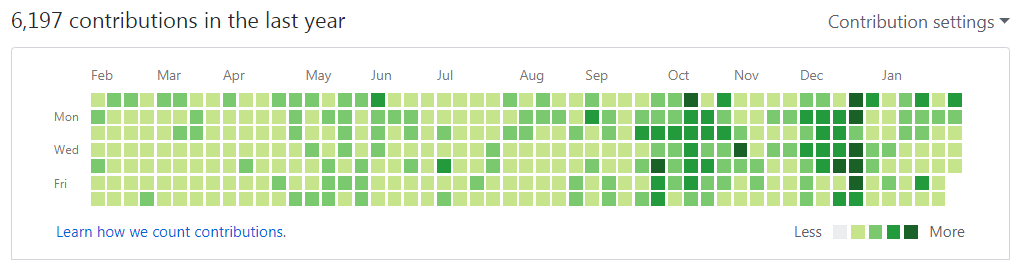
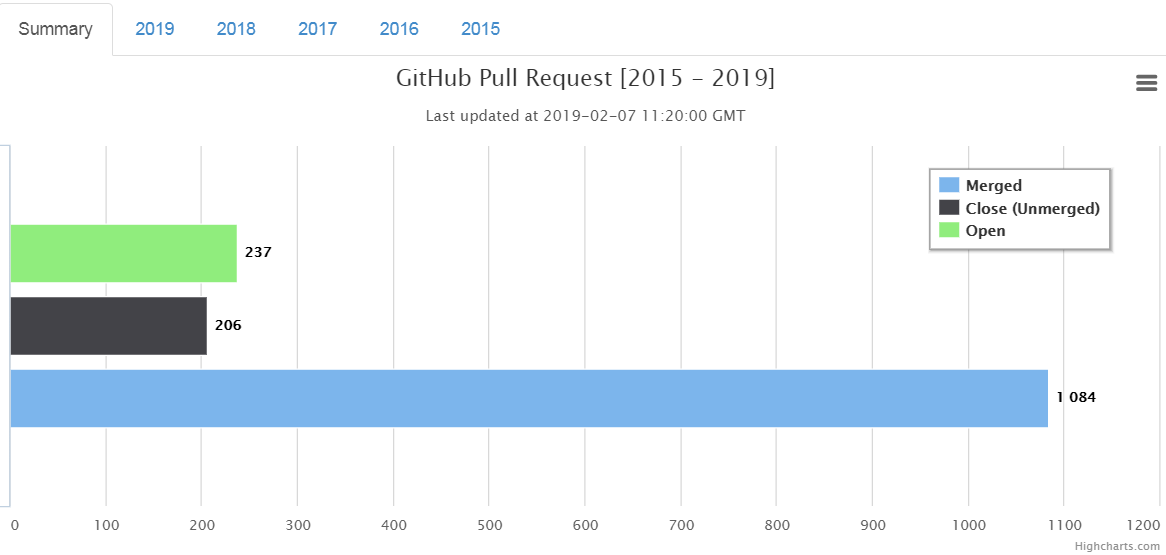
Ever since, I submitted the 1500th Pull Request at the end of last year, I have been thinking of doing some kind of data analysis. I love playing with data as it can tell you something interesting every time you poke. I had so many questions in my head with regard to my PR journey e.g. How many authors I have contacted so far? How many distributions on GitHub I have submitted PR against? etc.
Luckily, I have been collecting data about every PR (nearly) that I have submitted so far with details like author, distribution name and pull request id. I have used that in the graph that I have on my personal website.