An interesting memory hog
So last day I with a colleague got to trace an interesting memory leak ( which was rather a memory waste than a leak ). It was using tens of gigabytes of RAM, whereas I wouldn't expect it to use more than 3-4GB.
Call it a witchcraft if you like, but we identified line to blame within first minutes we started looking at the problem. Unfortunately, we were not able to convince each other that it is the issue and as the problem was only visible in a long running soak test we were not able to justify running it.
Perl's garbage collection works by reference counting and only frees circular references at exit. As we were dealing with a long running daemon - we started by trying to locate circular references. Inspecting code gave nothing away. So we decided to utilise wonderful Paul Evans' Devel::MAT module. Unfortunately we were not able to locate any circular references.
Finally we decided to look at how Perl sees our code by utilising B::Deparse & opcodes via B::Concise. Somewhere deep in ourselves we started doubting perhaps it is some Coro magic, however, as you will see later - completely unnecessarily. It was not Coro and frankly Coro has lots of potential and I believe it should be in Perl's core to assure its future ( though I know Marc Lehmann is of different opinion ).
Back to the story. By the end of the day we found nothing, we tried out nothing. I hinted to try commenting the line we identified within the very first couple minutes we started looking at the problem, which we did and left soak test running over night. In the morning, to much of our surprise, we found it was no longer wasting memory. For interested souls, it was line similar to following: logdebug( 'Returned ' . join(", ", map { "$" } @list ));
( yes ironically it was unnecessary call as log_debug() does nothing in normal mode we were running ). Nonetheless, consider following dummy cut-down script:
#!/usr/bin/perl
use 5.14.0;
use warnings;
use Data::Dumper;
use Devel::MAT::Dumper;
sub log_it
{
my ($line) = @_;
return length $line;
}
sub do_thing
{
my ($n) = @_;
my @list = ("x") x $n;
# large memory waste:
my $logline = "Returned " . join(",", map { "$_/" } @list);
my $length = log_it($logline);
return $length;
}
my @results = map { my $ln = $_ * 10000; do_thing($ln); } (1..10);
say Dumper @results;
Devel::MAT::Dumper::dump("/tmp/map-leaker.pmat");
which shows a memory hog in following Devel::MAT interactive explorer ( sorted by size ):
$ pmat-explore-gtk /tmp/map-leaker.pmat
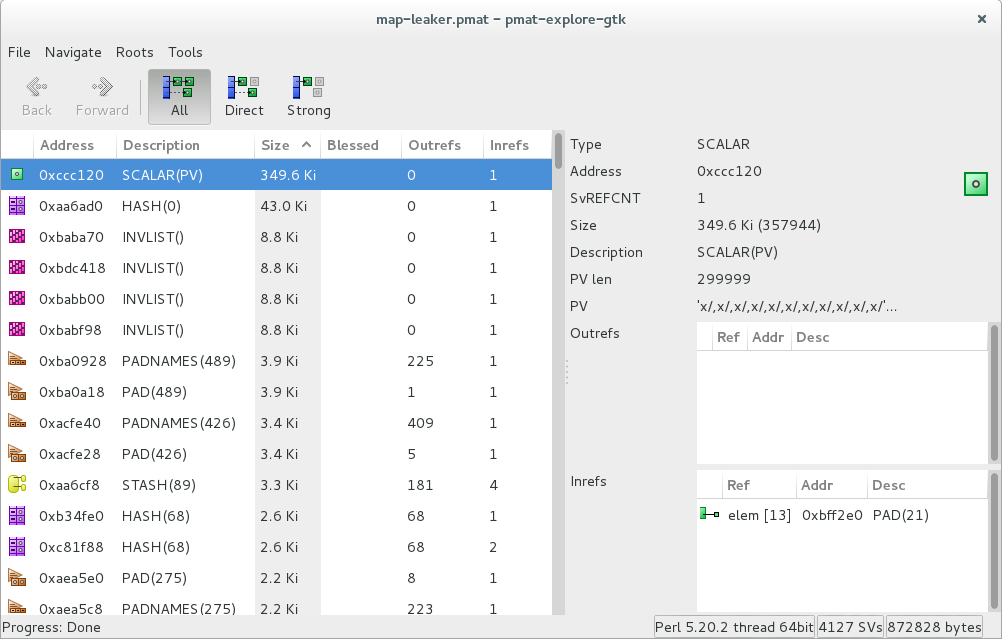
Interestingly following does not end up wasting memory:
#!/usr/bin/perl
use 5.14.0;
use warnings;
use Data::Dumper;
use Devel::MAT::Dumper;
sub log_it
{
my ($line) = @_;
return length $line;
}
sub do_thing
{
my ($n) = @_;
my @list = ("x") x $n;
# small:
my $logline = join(",", map { "$_/" } @list);
my $length = log_it("Returned " . $logline);
# large:
#my $logline = "Returned " . join(",", map { "$_/" } @list);
#my $length = log_it($logline);
return $length;
}
my @results = map { my $ln = $_ * 10000; do_thing($ln); } (1..10);
say Dumper @results;
Devel::MAT::Dumper::dump("/tmp/map-leaker.pmat");
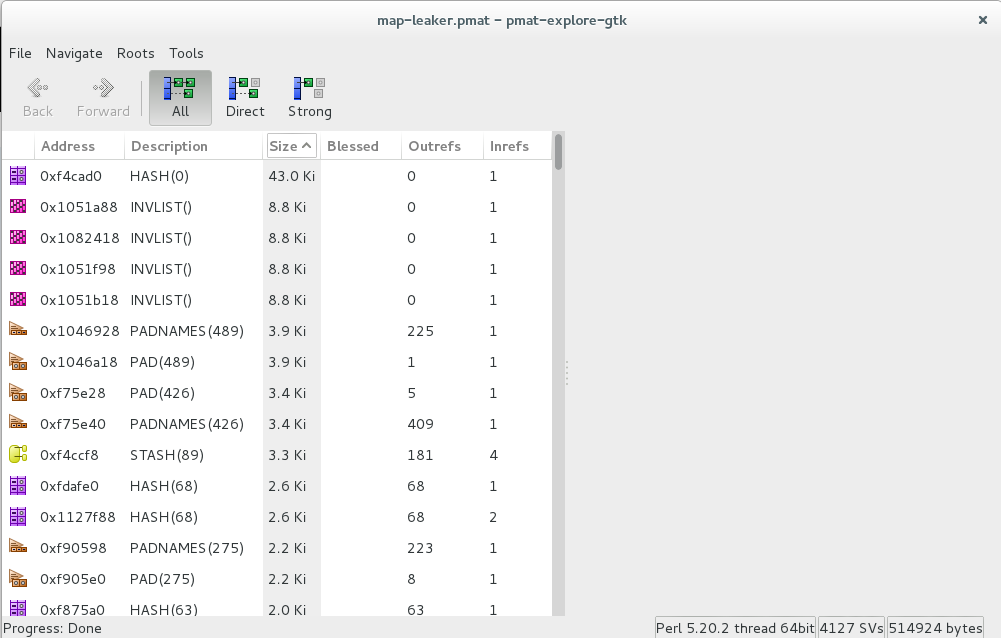
nor does following:
# also small:
my $logline = "Returned " . (my $temp = join(",", map { "$_/" } @list));
my $length = log_it($logline);
As one might expect, Coro does the right thing by copying padlists around, hence increases the memory waste - roughly - by number of active coroutines. Consider following example:
#!/usr/bin/perl
use 5.14.0;
use warnings;
use Coro;
use EV;
use Coro::AnyEvent;
use Data::Dumper;
use Devel::MAT::Dumper;
sub log_it
{
my ($line) = @_;
cede;
return length $line;
}
sub do_thing
{
my ($n) = @_;
my @list = ("x") x $n;
# small:
#my $logline = join(",", map { "$_/" } @list);
#my $length = log_it("Returned " . $logline);
# also small:
#my $logline = "Returned " . (my $temp = join(",", map { "$_/" } @list));
#my $length = log_it($logline);
# large:
my $logline = "Returned " . join(",", map { "$_/" } @list);
my $length = log_it($logline);
return $length;
}
# Either construction shows the problem, but the coro one leaks 10 instances.
my @coros = map { my $ln = $_ * 10000; async { do_thing($ln); }; } (1..10);
my @results = map { $_->join(); } @coros;
# my @results = map { my $ln = $_ * 10000; do_thing($ln); } (1..10);
say Dumper @results;
# Demonstrate that there's one leak per active coro, not one per coro that
# ever existed. So there will still be 10 leaked even though we do another
# 10 iterations here.
my @morecoros = map { my $ln = $_ * 10000; async { do_thing($ln); }; } (11..20);
my @moreresults = map { $_->join(); } @morecoros;
say Dumper @moreresults;
Devel::MAT::Dumper::dump("/tmp/map-leaker.pmat");
and following outcome:
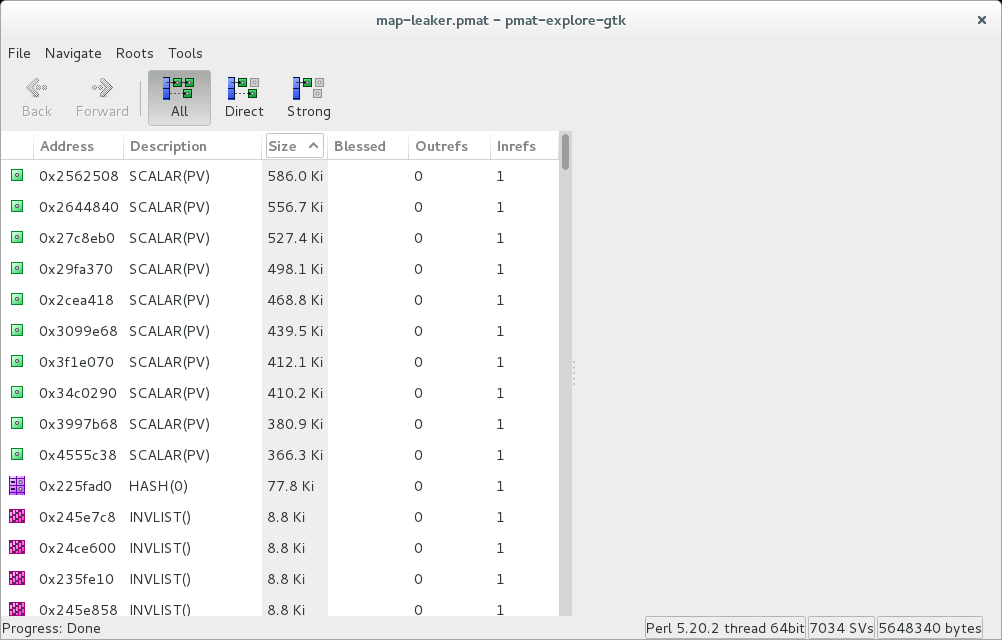
It's midnight here and I feel rather tired ( as you might tell by how quickly I glossed over last part ), so I will finish it here.
 I am proud Perl developer since 2014.
twitter: https://twitter.com/vytasdauksa
I am proud Perl developer since 2014.
twitter: https://twitter.com/vytasdauksa