For the second year, I have had the great privilege of attending the Perl Toolchain Summit (PTS, formerly called the QA Hackathon QAH).
This year it was held in Lyon, France, and three cheers for the organizers; it was an amazing event!
Last year I unexpectedly became involved in the Meta::CPAN project, even to the point of hosting the first (annual?) Meta::Hack a few months ago.
This year, I continued to work with them, however, the need was greater in the CPAN Testers realm and so there I went.
MetaCPAN is the community developed and maintained website and api for finding and learning about Perl modules.
This year, we dedicated a long weekend to improving it and oh what a weekend it was!
In a future post I will recount the details of my delightful experience at the 2016 Perl QA Hackathon (N.B. now published here).
Since this is my first post since that time I do want to tip my hat to the great sponsors of the event and to my own employer ServerCentral without whom I would not have been able to attend.
I will thank them in more detail in that post.
Before I get to that however, I want to post a reflection on one discussion that is and has been weighing on my mind since then.
That topic is the upcoming release of Test2, which I consider to be a very important step forward for Perl’s testing architecture.
I have found myself in a bit of a CPAN exuberance these last few months.
While I have released several new modules, I haven’t found time to announce them individually.
Here then is a joint announcement of what I’ve been doing on CPAN lately.
While I know many of you have CPAN Day projects, some of you might still be searching. There is a very well known benchmark from TechEmpower which compares web frameworks. It gets plenty of press and generates much interest. Unfortunately, the Perl results look like this:
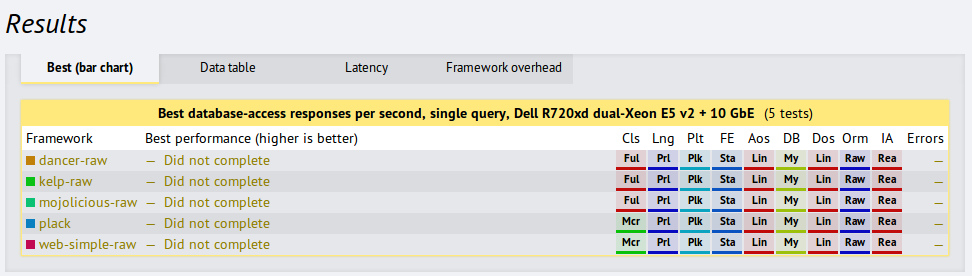
We all know the reputation that Perl has to the outside world, and sadly these results would tend to reinforce it. The person or persons who added these apps seems to have long since forgotten about them. At least the Mojolicious app was a port of one of the others and did not exemplify either the style or power of the framework. The others likely share those traits.
But all is not lost! TechEmpower has recently made it much easier to contribute, and I have fixed the deployment and toolchain problems. I have also updated the Mojolicious app. Would you like to improve the submission of your favorite framework or add your own? Read on!
I have just ranted about removing old bad code from the Perl core. Let me lighten the mood by talking about some good, new code.
I have loved Moose for some time now, but like others, I disliked how heavy it was. Then Moo came along and it was great … until I found myself not availing myself of the type system, because it was harder to get to than in Moose. I was skipping validation more and more.
A recent project came up and I really wanted to do it right, so I tried Toby Inkster’s new Type::Tiny and may I say, “hat’s off to you sir!” The combination of Moo and Type::Tiny brings that Moosey feeling back, while still being light and responsive and even fat-pack-able! Great work to all involved in both projects!
People may have noticed my absence from the Perl world lately. I have been writing my Ph.D. thesis (179 pages on Ultrafast Electron Microscopy with my Physics::UEMColumn Perl module featured) and defense.
Ack is a tool for searching code and text. It works much like the unix tool grep, although it is imbued with the power of Perl. To mark the release of Ack 2.0 though I wanted to mention a few one-liners that made my life easier in this stressful time.
My thesis is written in many LaTeX files and one can probably imagine that searching those files was needed regularly. The biggest is for finding non-ascii characters. As I add content from old publications or external programs, lots of non-ascii characters can often come along for the ride. LaTeX is a very old program, well pre-dating unicode, and it has a very different way of adding special characters with its own markup. In fact parts of the compiling toolchain croak with unicode characters. So I found myself using
ack '[^[:ascii:]]'
regularly. Also I had to keep a list of all the abbreviations that I had used in the paper, but of course you forget if you have them all. I used this little bash-ack conglomeration to find all sequences of two or more upper-case characters, which is how I write my abbreviations,
ack -ho '\p{Upper}{2,}' | sort | uniq
I’m sure I used many other little ackings here and there, but these were the two I could remember off-hand. Thanks to Andy and everyone who has contributed to ack!
Now go use it to make your life easier!
Visit the new site: beyondgrep.com
I have mentioned before how much I like CPANtesters! Here is another story.
Yesterday I got an email from them listing a number of failures from Galileo, my CMS. I had recently pushed some bugfix releases, but it had some new, and as yet unused code and tests for that code in it. The tests passed on all my Linux systems, so I wasn’t worried about the release. Yet the failures came in. Some on Linux, some on other platforms, but not all the tests were failures and I couldn’t figure out a pattern. CPANtesters put me on to a problem but for this I needed faster results.
I had heard about Travis-CI, a free continuous integration platform based around GitHub. I set up travis testing for Galileo and sure enough it failed there. Though it was frustrating I now had failing tests that I could run at will! After much trial and error, I found that I had an undeclared dependency, but due to the way I was testing, it was throwing a seemingly unrelated error. My problem was that all my systems have the module installed and so I didn’t get the failure on my box, its a common module File::Next (used by Ack) and so many of the CPANtesters had it as well.
CPANtesters alerted me to the problem and Travis-CI let me continuously test on fresh platforms (5.10/12/14/16) until I found the problem. I love open source.
I have released Galileo 0.026 which fixes the problem. There are exciting additions to Galileo in the works, slowed only by my upcoming Ph.D. defense (which obviously takes much of my time). I hope that by this summer Galileo will have several of the most requested features you have told me that you would like.
Happy Perl-ing and remember to thank those projects and developers who make your lives easier, both in person and in public. Thanks guys!
On February 28th I will be presenting an “Introduction to Mojolicious” to the Chicago.pm meeting. If you are in the area I hope you will stop by; it won’t just be an introduction despite the name. If you are interested, here is the Meetup link.
I haven’t decided, but I might try to “self-host” the talk, writing it as a Mojolcious app! To do that I had to resurrect one of my earliest CPAN releases Mojolicious::Plugin::PPI. This module does just what the name should imply, providing syntax highlighting via PPI and PPI::HTML in a handy Mojolicious plugin.
Whether or not I decide to use this for my talk, it still is handy to have around. Here is a cute example, a simple “quine” which you can run:
#!/usr/bin/env perl
use Mojolicious::Lite;
plugin 'PPI' => { toggle_button => 1 };
get '/' => sub {
my $self = shift;
$self->stash( file => __FILE__ );
$self->render('quine');
};
app->start;
__DATA__
@@ quine.html.ep
% title 'A Mojolicious "Quine"';
<!DOCTYPE html>
<html>
<head>
<title><%= title %></title>
%= javascript 'ppi.js'
%= stylesheet 'ppi.css'
</head>
<body>
<h2><%= title %></h2>
%= ppi $file
</body>
</html>
A quine is a program that prints its source code as its output. In truth, this “quine” is really a cheater, a true quine doesn’t read itself. Still, the above example renders the source code nicely highlighted by PPI (and with some added goodies like toggleable line numbers).
Just for fun, some other Perl (cheater) quines are:
@ARGV = $0; print for <>
and
seek DATA,0,0; print for <DATA>
__DATA__
But those outputs aren’t syntax highlighted. For a real one see the comments.
The great detective was staring at the door, as he had done for the past two weeks. He needed a case to occupy that mind. Thankfully today the door opened and Holmes had a case.
A man stepped in and introduced himself as Mr. Mokko.
“Watson, here is a man having troubles with Perl.”
“Holmes, how can you know that?”
“We can tell from the lines on his face, the stiff wrists and the pads of his fingers that he a much maligned sysadmin; from the Hawaiian shirt and the hat that he’s into the Perl scene. The scowl and the fact that he’s here on our doorstep tells me that he’s having troubles.”
Holmes looked back to the man and said, “Come now, you must tell me the tale.”
 As I delve into the deeper Perl magic I like to share what I can.
As I delve into the deeper Perl magic I like to share what I can.