SparrowHub Plugins Request
A quick search at github on something like Perl/Bash scripts gives me a lot of results.
As developers we more think about modules and libraries when talk about software reuse. But in our day-to-day life scripts still take a vital part. Scripts like little, but useful commands to get our job done. This is why people from many programming languages/environments tend to create a places for such a tools called repositories, so other could easily find, install and run scripts or utilities. To list a few:
Well. A SparrowHub is a attempt to make a such effort in Perl communities to create a repository of useful automation scripts. Sparrow is Perl friendly in many ways:
- it is written on Perl
- it gets installed as CPAN module
- it respects carton/cpanfile dependency management for your scripts
- it supports Config::General format for script configuration ( among JSON, YAML and command line parameters )
Well let me now turn to the essential point of my post.
I know there are a plenty of cool software written by Perl community we know as CPAN, and many, many Perl modules get shipped with some useful scripts, even more some module's are only public interface - some command line scripts. So why not to upload such a script into a repository so other could use it? I know not all the cases are good fit, but let me outline some criteria if your script could be a good candidate to be uploaded as sparrow plugin:
you have some command line tools based on existed Perl/CPAN/Bash scripts and want to share it somehow with others or even keep it for yourself so to repeat script installation / execution process in the same way every time you setup a new server.
script takes a lot of input parameters or parameters with the structure is hard to be expressed in command line manner ( Hashes, Lists, Groups, so on ).
you need to add some middle-ware steps to your script logic , but don't want to add this into scripts source code.
you need to build a more complex tool based on your low level script/utility.
script possibly gets run often and / or on multiple servers.
script requires some extra checks so one could run it safely.
script is a generic tool acting differently depending on input parameters.
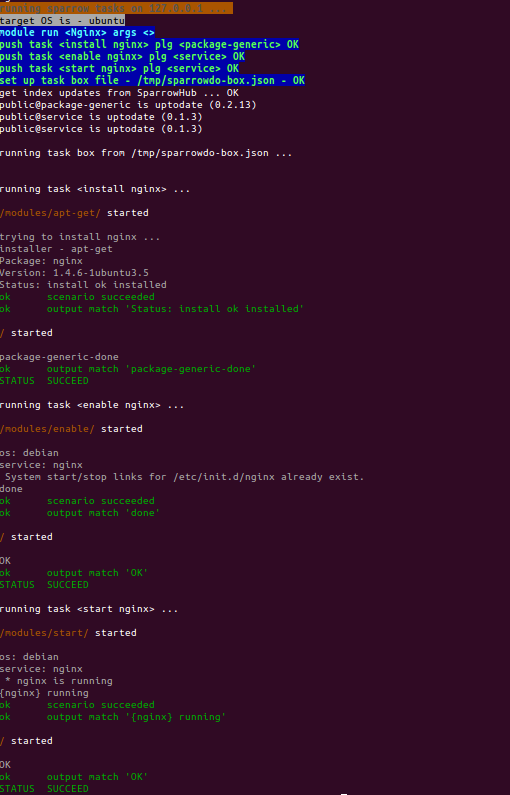
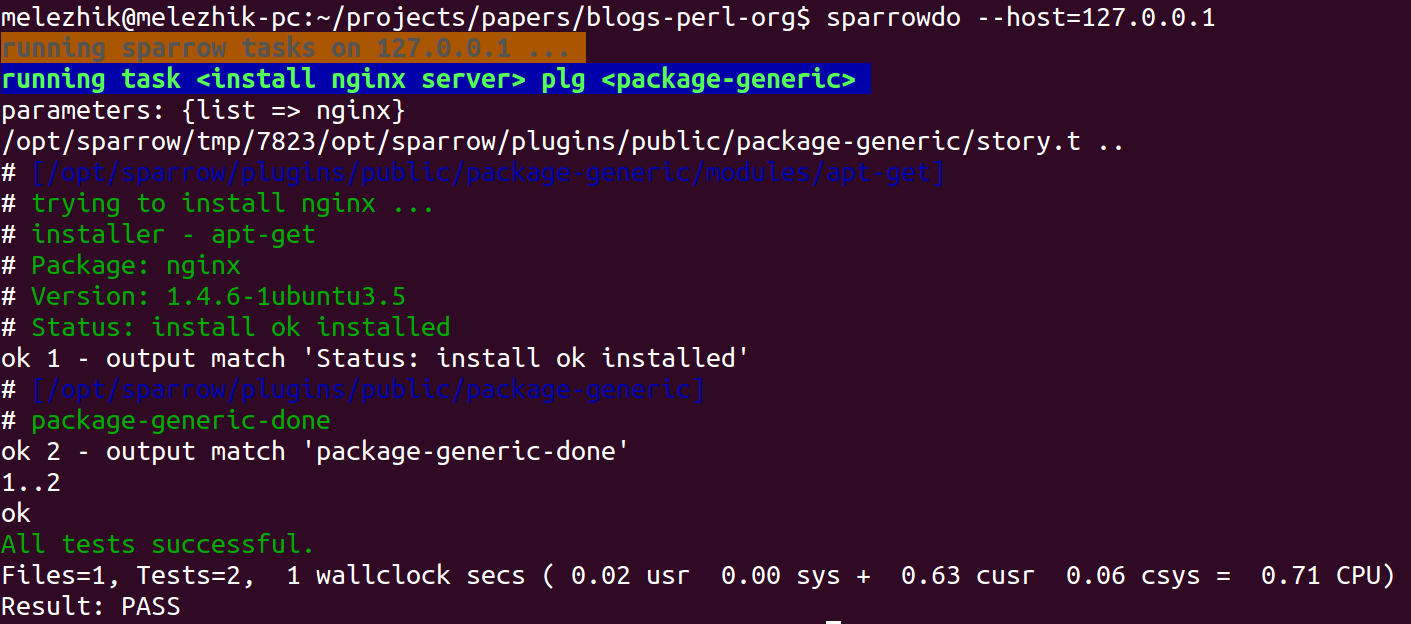
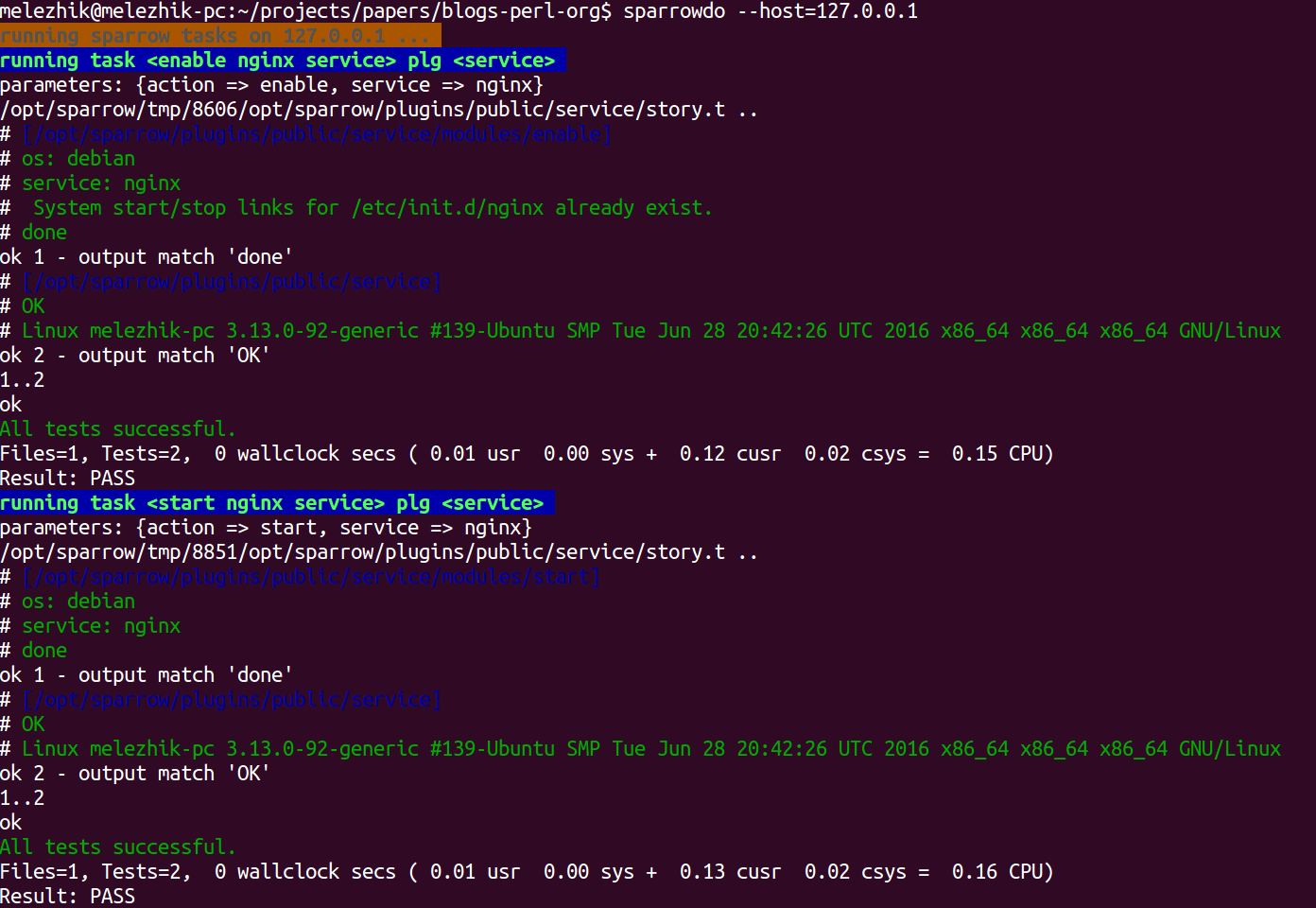
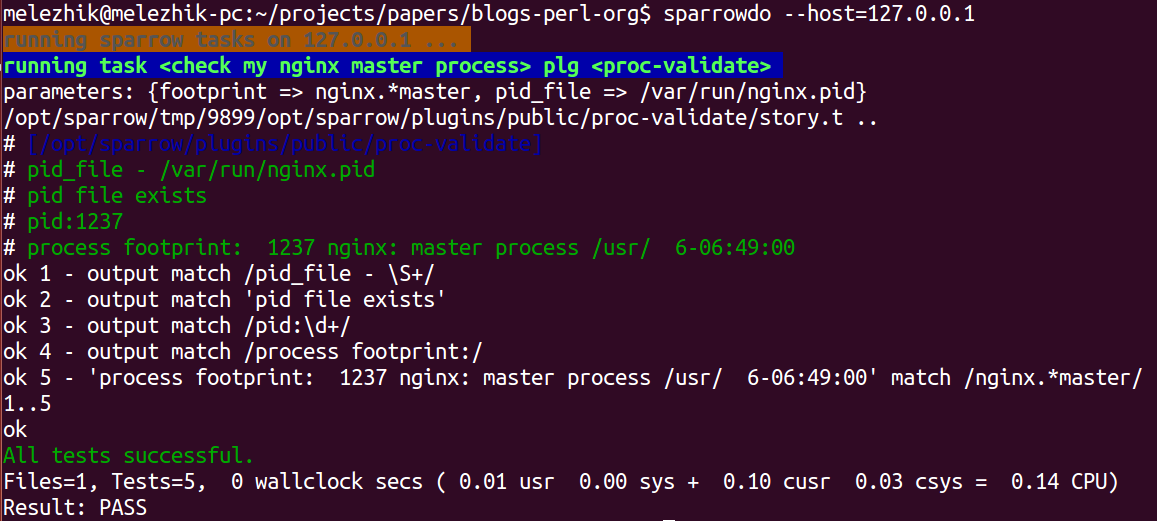
So if this sounds like about your scripts, you may start playing with SparrowHub. After all it's just distribution platform, having minimal impact at your script code:
- You write/already have a script ( plus some dependencies software like CPAN module )
- You upload script / or script based tool to SparrowHub as sparrow plugin
- Others may find, install and run your script ( via SparrowHub ).
If this sounds interesting there are simple `how to contribute' steps:
- Get registered at SparrowHub
- Convert your script into sparrow plugin
- Upload new sparrow plugin
In case you still have a questions or need help on converting your scripts into sparrow plugin, please:
- Post an issue at sparrow/issues
- Or ask your question at SparrowHub Google Group
Finally, if you feel like you have no time to dive into new things and study docs, but you are still interested in the subject, just let me know ( creating an issue at sparrow/github ) about script you wish add sparrowhub to and I will try to do it soon.
Regards.
Alexey Melezhik
 Dev & Devops
---
Then I beheld all the work of God, that a man cannot find out the work that is done under the sun: because though a man labour to seek it out, yet he shall not find it; yea further; though a wise man think to know it, yet shall he not be able to find it.
(Ecclesiastes 8:17)
Dev & Devops
---
Then I beheld all the work of God, that a man cannot find out the work that is done under the sun: because though a man labour to seek it out, yet he shall not find it; yea further; though a wise man think to know it, yet shall he not be able to find it.
(Ecclesiastes 8:17)