Well scooping about looking at way to refactor some of my AD&D 'Creator' class code I stumbled on a nice little feature of Moose.
Though not really standing out in the Moose documentation and not really hidden either is the fact that all of the declarative keywords are really just function calls.
So you might recall that I had this in my 'Creator' Class
Perl will be big at Fosdem in Brussels with a big booth on both days of Fosdem and a devroom on the first day, Saturday 1 February. At the booth you will find a lot of interesting stuff, like the largest library of Perl-books in the world, the big stuffed toy camel, Tuits, buttons, books, brochures and whatnot.
The schedule is filled with great speakers and nice presentations. This year, the devroom and the booth will be in the same building (building K).
We will have beer on Friday at Delirium, go to a nice restaurant on both Saturday and Sunday, and we will be in the presence of 5,000 to 7,000 open source enthusiasts. This is going to be a wonderful event.
Read all about it, and much more:
http://wendyga.wordpress.com/2014/01/26/fosdem-perl-devroom-schedule-1feb2014-and-booth-12feb2014/
Hope to see you in Brussels, Belgium!
Perl was known for its unmatched text processing but I couldn't quite catch it till I had used it for my personal project. I am still using only baby Perl that I am learning from 'Learning Perl' . I want to make an android app with content from wikitionary to create a database of words, parts of speech and meaning as three fields database with each word as a table. I downloaded the Wikitionary dump which is a Tab Separated Values file.
I have said it in many other posts over the years perl just never ceases to surprise me.
Well I was down and dirty with some code today doing an ongoing migration from Informix to Prostgres of a very very large perl code-base.
Needless to say one of the most important tools in this migration is the good old 'inline if' or ' ternary if' or just plain old '? :'
The code base has a largely hash based so it is a simple matter to find the offending lines of Informix SQL and using the '? :' to add in the Postgres SQL. Of course only part of the client base is migrating so it is mandated that both DB must work with the same code hence the need for all the inline ifs.
In niederrhein.pm we're trying to increase our talks to share the experience of advanced Perl users (developers, however :P).
I agreed on a talk (more a small tutorial) which should show how to Moo a real world application (read: not perfect, quirks, quick-shots - daily business). I decided to do it using my tool I develop to create math exercises for my children - it's a simple tool without to much tricks.
For anyone who wants to join modern Perl-OO - try work through the slides and create some exercises.
I posted this yesterday on my personal site and realised it might just act as a reasonable "getting started" type article for SDL with Perl. Further articles in the series probably won't have this level of detail, so I'll keep them on my own site. Anyway, on with the show.
So I decided to play around with Perl's SDL bindings.
A game appears to be happening, so let's play around with this dev log idea too,
documenting the process and pitfalls of making some stuff move around on screen.
It turns out you don't need to know a whole lot to make this happen, in the
simplest cases at least. Let's see what we have so far:
OK, so we're not going to set the world alight just yet. Anyway, we have a guy
and some bullets. We are missing enemies, scoring, action, pew pew noises and
any incentive to play. These come later, I hope.
We regret to announce that blogs.perl.org was recently the subject of a data
breach.
An attacker gained access to the database that runs the site, and was able
to take a copy of all users’ hashed passwords. We’ve therefore cleared all
users’ passwords as a precaution.
If you have an account on the site, you should have received an email
telling you how to reset your password.
If you haven’t received it soon, please let us know.
Even though the passwords were stored in a hashed form, rather than as
plaintext, the blogging software we use (Movable Type) uses a relatively
weak hashing algorithm, so the attacker may be able to determine your old
password.
It is therefore very important that, if you used the same password on any
system other than blogs.perl.org, you change the password you use there,
too.
We apologise sincerely for the inconvenience this has caused our users, and
for failing to live up to the trust that the Perl community has placed in
us.
I have looked high and low for help on getting started on a blog here at blogs.perl.org, specifically with regard to typical templates and including syntax highlighting to put code in my articles, but I can't find anything.
I fear it may end up being something as simple as, "Did you click 'Help' over there?" But, I will post this and take a chance on looking silly.
I've written about this before, but now I want to show some slides from my new testing class because I think it's easier to show test suite organization rather than describe it.
Years ago I wrote HTML::TokeParser::Simple, an OO interface to HTML::TokeParser. The latter is a great module, but you are typically working with a bunch of array references like this:
That can be confusing and you often have to write code that is hard to immediately understand. For example, here's the code to strip all comments from an HTML document:
I always surprises me how much one can get out out of the perl community without asking. Something like 3 years ago I had my first git-hub account not really for myself but for a 'job' interview that required it.
Long story short, in the interview they said they couldn't find my twitter feed and I hadn't friend-ed them on facebook yet. I said tweets are for budgies and I don't have a facebook account and have never even been to that site in my life (and still have never been there). The interview went down hill from there, especially as I said why would I wast my valuable time on such fluff. Anyway at least I got a gitgub account out of the process.
What I have found nice about github is people like to make it better and so I think today I will do my first clean up of my very few repos.
Seem there are a few things I have to clean up but never bothered to till today.
This the the third part in an on-going series about using Mojolicious to write non-blockging applications (with an eye towards the web, obviously).
In part 1 I demonstrated the how it can improve the number of requests/clients served when the application uses high-latency backends (in that case a database).
In part 2 I showed how each request can be sped up when that request needs multiple resources from a high-latency service (e.g. external web services).
In each, I showed a blocking example, then a non-blocking example.
I then gave the usual warning that you had to use a Mojolicious server for the nonblocking version.
While its true that you need a Mojolicious server to get the benefits of the nonblocking architecture, in this post I will show how with a little care in construction, you can build your application so that it will run correctly on any supported server and the nonblocking benefits will be evident where possible.
This is part 7 of an ongoing series where I explore my relationship with Perl. You may wish to begin at the beginning.
This week we meander around the topic of education hoping to come to a point about Perl.
So far we’ve learned that I’m an English major, that Perl has a lot of linguistics baked into it, and that (at least in my opinion) creativity is good for programmers. What does all that mean? Well, for me, one of the things it means is that I lack some of the computer science background of my peers. I never had to take a class in compiler design, for instance.1 In fact, there’s a lot of stuff that CS majors had to learn that I never did. Oh, sure—I picked some of it up along the way. But it’s still true that when I read certain very technical programming blogs (like Jeffrey Kegler’s excellent articles on Marpa), I have to skim over a bunch of parts. But I also have an analogy I’m fond of breaking out:
You don’t have to understand how the internal combustion engine works in order to drive a car.
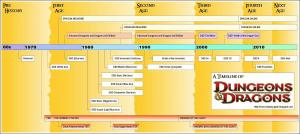
Well with my last post I managed to get a little closer to my original goal of selecting a 'Character Class' after I have selected a 'Race' as the image below explains
I sometimes have a Hobbit (well Halfling in A D&D) of doing that.
Well in this post I centralized all of the 'Race' rules under one namespace and so I though I might as well do that for 'Character Class' rules as well.
So for each of my 'Character Classes' I could just add a new role like this
Note that it's crappy, poorly documented, and does what I need it to do. I've also cleaned it up slightly to remove some older cruft. It's only there because others have asked for it and for many people, it won't be all that useful.
During this seventh edition, as usual, the participants will be giving their time, knowledge and experience to the Perl community for four days, hacking and arguing about QA (quality assurance) and CPAN toolchain. In return for their time and valued experience, we want to make this event as cheap as possible for them to attend, by covering their travel, accommodation and food to the best of our abilities.