A goal that set my juices to flow is to make Perl a first class GUI language. Like back in the days even hardcore Java people took TCL to whip up a small graphical frontend app. This should now be done in Perl, because Perl can be simple but powerful when you need it. It just lacks some nice sugar to get a Gui fast. And GCL is my attempt to achieve that.
In an effort to follow JT's advice about writing something new every day, I've queued up some articles over on my blog. Most of them will be about Perl programming, but also some UAV and Arduino stuff.
The first one today is about File::ShareDir, which I think is an underappreciated module that solves a problem we'll all probably hit sooner or later.
Last week I completed a two-part training at work on perl's internals,
led by Yves Orton and Steffen Mueller. We covered some of data structures used by the interpreter,
as well as some of the optimizations it uses and the consequences of how those optimizations are
implemented. Someone on Twitter asked me if there were any slides
available, and unfortunately, the talk was conducted in a very ad-hoc fashion (which actually probably contributed to
its success, as the audience was able to propose new areas to cover). However,
I did end up taking some notes, so I'm going to summarize those here along with what I
remember. A lot was covered in the two sessions, so in the interest of actually getting
this information out (I tend not to publish things that I can't write in one sitting),
as well as keeping your attention, I'll be publishing them in a series of posts.
I recently took a vacation with my family and actually didn't spend any time working on p5-mop-redux (or any code for that matter) which was actually kind of nice (odd but nice). But thankfully Jesse Luehrs, my co-conspirator on the previous p5-mop attempt, found himself with some free time and so was hacking away. He ported one of his newest modules, Reply (which is a really nice REPL for Perl, you should try it) and noticed that the startup time was pretty slow (something important for a REPL). Of course this is to be expected in a prototype, but still, Jesse went and added this simple method cache which resulted in an almost 3x speedup for startup time.
Jesse also added two new class traits both of which are important for enabling users to subclass MOP based classes using non-MOP based classes.
With great interest I read When "unsafety" is a Good Thing and brood over Gabor's comment regarding "inconvenience vs. danger".
In my job, I have done a fair amount of coding these days. Mostly smaller tasks, you know, the sort of problem you just not so easily solve with Excel. I did some gardening, so to speak..
The code now takes the output of Marpa processing your grammar (still available via the raw_tree() method), and post-processes it to provide just the user's grammar. That is, it is shorn of all the Marpa-specific details.
The main purpose of cooked_tree() is as input into MarpaX::Grammar::GraphViz2 V 1.00, which converts your SLIF-DSL (a type of BNF) into a visual representation.
During this, I found a bug in GraphViz2, so it's now at V 2.20.
Lastly, the demo page for MarpaX::Grammar::GraphViz2 is here.
It's written in Perl for POSIX systems (there are reports of successful use under Linux, BSD, MacOSX, Solaris).
It does have extensive testsuite, minimum dependencies, "full" unicode support (well, of course it's not full. there is probably no single application with full support),
multithreading implemented using fork(). HTTP(S) using LWP::UserAgent with workarounds for existing issues. Total SLOC is over 20k, more than 1000 commits.
Mojolicious’s 4.0 release came with lots of shiny features but it also came with a lot of housecleaning. One of the old things swept away was the memorize helper, which would cache a part of a template and prevent its repeated evaluation. Do you miss it, as some users undoubtedly do, or else does this helper sound useful to you? Then read on, because its back and better than ever!
I have a quick sanity check I'd like to throw out there.
I've been working all week on Alien::TinyCC, and I made some great progress. My initial distribution wasn't properly checking that the build steps completed successfully, so I wasn't getting any useful information back from the smoke testers. Once I fixed that, I started to get some useful feedback. Mostly.
Disclaimer: the docs things starts at paragraph 3.
Within 2 Weeks I was in Kiev and St. Augustin, giving 6 instances of 3 talks. My minireport on Kiev got published (in German) but there is a lot more to say of course. In Kiev Wendy talked me into the frogcon (the frog is the official logo because if you add an H ...) thing. And it was the best Perl booth/dev room we had ever there and i had a nice kinda YAPC after party, which sparked some thought what could be improved for the Perl world.
The other day I wanted to send a patch to WWW::Mechanize and it turns out it is now hosted within a Github organization called libwww-perl.
Then I read a comment by Ether, about the Perl-Toolchain-Gang, another Github organization with several members that maintain a bunch of modules.
The perl6 organization on Github includes many Perl 6 related projects.
Then there is the perlorg organization that holds the source code of the Perl.org, CPAN.org and PM.org.
I am really glad to see such cooperation is on the rise among Perl developers. This might also lead to more people contributing to these modules.
Maybe other CPAN developers would also want to move their projects under such umbrellas. Are there other such "github organizations" for Perl projects?
Some months ago, I read an article by someone who teaches Perl to Java programmers. In it, the author wonders a bit about some of Perl’s features which seem counterintuitive to those coming from a Java background. As you might expect, one of those features is its typing. He says:
For example: stern, protective type safety is not only missing from Perl but actually not even considered particularly desirable. Perl is relaxed. The reaction from students is, naturally: “Isn’t this a huge obstacle to getting anything done?” Obviously the answer is “No”, but even after all the Perl I’ve written I sometimes wonder why not. Is it really just the fact that it takes less time to type method signatures and variable declarations?
At the time I read this, I thought to myself, “Hey, I know the answer to that!” But I just jotted it down as a potential blog topic and let it percolate for a bit. Many folks reading this will also know the answer, but it’s an interesting topic, and I’m sure someone will get something out of it.
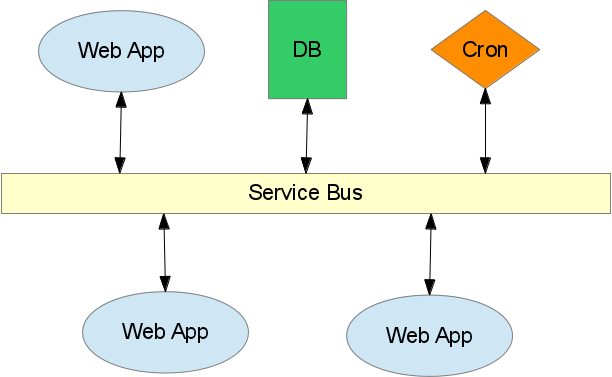
In the following I describe how to build (from scratch) a simple Catalyst
application that acts as a service bus for a collection of other Catalyst
applications.
Here I'm using the term service bus to describe an application that provides
web services to other applications (rather than, say, a JavaScript enabled web
browser). This service bus acts as a central hub, taking requests form
applications for tasks that sit outside their scope and either executing those
tasks or passing them on to other applications.
The following assumes you have a working Catalyst development environment (see
www.catalystframework.org for instructions).
A Service Application
Our service bus will communicate with the other applications using simple HTTP
requests and will pass data using JSON strings. Let's start by using the
Catalyst helper script to make a Service application:
I released GitPrep 1.2. You can install portable GitHub system into Unix / Linux easily. It is second major release.
Because you can install GitPrep into your own server, you can create users and repositories without limit. You can use GitPrep freely because GitPrep is free software. You can also install GitPrep into shared rental server.
- Added import_rep script to import repositories. If you have many repositories, you can move these easily.
- Add blame page. you can know who change source code.
- Add the feature to import branch from other user.
Repositories Importing script is good feature because moving repositories become easy.
I recently updated File::Temp and wanted to standardize how we were creating temp files. Most places were using File::Temp already. I ran across one file where we using IO::File and returning both a file handle and the filename. I changed it to simply return a File::Temp object.
I rolled the change out to a test system and noticed a problem... All of our generated files were empty! I traced the problem down to using the File::Temp object with File::Copy's copy subroutine. I suspect it's the tied file handle bug biting us but the fix was quite simple.
Perl6 is at a turning point. Now running on 2 virtual machines (Parrot and JVM), with 2 more coming available in the next months (Javascript and MoarVM), with abstract concurrency on the JVM now and full Perl 5 interop at the horizon in MoarVM.
To make it easier for past, current and future Perl 6 contributors, we have asked Jonathan Worthington to give an intensive 2-day workshop taking a deep dive into many areas of the Rakudo and NQP internals. This is your chance to get up-to-date with Perl 6, specifically with Rakudo and NQP.
The workshop will mostly be focusing on the backend-agnostic parts but with coverage of the JVM and future MoarVM backends too. While the overall focus will be on getting to know the Rakudo and NQP internals, we'll also build the odd small language and object system along the way to get a better handle on the primitives.
It will be held in Frankfurt am Main, Germany, on 14/15 September 2013
I am Yuki Kimoto, Japanese Perl programmer. I create tutorial site in Japanese and English. I create Perl module and upload it to CPAN. I create Web application in Github.
Just as blog posts including images also documentation that includes images (even screenshots) is more plesant for the eye than just plain text. On both search.cpan.org, and Meta CPAN one can have images linked from the POD.
It would be awesome if more modules had a few images or screenshots included
and you can gain fame via the relevant Questhub Stencil.