As an update and continuation of my last post: lot has happened. This is also a kind of Grant report since the Perl 6 Tablets are rolling again and I plan to cash in the first half of the TPF grant around YAPC in Riga but definitively before Frankfurt (german perl workshop).
You may ask what took so long or why I believe to be now much faster. I just see how much I was able to do in last months. There was the perl tutorial which was very successful in his first part, but 7 or 8 other will follow. You can watch them growing or participate in our wiki.
Yesterday I had a lot of work to push my code to dotcloud, using the new client, 0.4.1. This mainly because the structure of DotCloud services changed.
These are some pointers to help if you get into the same problems:
Now the dotclout push command doesn't copy your code to a specific service. It is copied to all services, even for mysql servers. Also, the copy is not performed directly to the server. First, it is done to an intermediate upload server, and then sent to all your service servers.
Back in May there was some discussion on the CPAN Testers Discussion list regarding the statistics available on the CPAN Testers Statistics website. As I was already in the process of cleaning up several pages, some of the ideas looked worthy of including in the next release. Two have made it, and are now available for those interested in the reporting statistics.
MetaCPAN went live with the switch over to Catalyst (previously we hadn't been using a framework at all) this morning.
The main aim was to make it easier for people to contribute and also to extend.
An unintended consequence was a significant increase in speed. We've not delved into the details - but the lesson learned is that using something as established and polished as Catalyst really makes a big difference compared to putting something together from scratch.
We've also added an experimental 'Sign In' button - have a play! You can use either Twitter, Facebook, GitHub or PAUSE to log in. Once you have authenticated against PAUSE, you will be able to edit your author's profile page via the front-end.
Sherm Pendley passed away this last weekend. He was a regular on usenet
and also the author of CamelBones, a Perl/Objective-C bridge. I got to
know him well over the several months as I placed him at his current
job. He was very well respected and liked at that company and all his
colleagues and I are all very shocked and saddened at this news. I
haven't heard an official cause of death but he was ill last week and
something must have gotten very bad. He will be missed.
Let this blog post be also an invitation to my talk that I'll have on this years YAPC::EU::2011 in Riga and a reason "Why?" there will be more questions then answers.
There is one question that keeps me busy for quite some months now already and that is: What if the knowledge and wisdom is not in answers, but in questions?
As it kept me busy for just too long and as I'm a full-time Perl programmer, I've decided to write a code to help me answer "Why?".
Sherm Pendley passed away on Saturday, July 9th. He was best known in the Perl community as the primary author and maintainer of CamelBones, an Objective-C/Perl bridge for use in Cocoa development. He was known among his friends and loved ones for his wit, humor, and intelligence. Sherm once wrote: "Simply put, my overall goal is to leave the world a better place than I found it."
I'm grateful to have found such a wonderful language to help me do almost any job at work better, and for keeping me entertained long into the night away from the office. I look forward to another 10 years. Thanks Perl!
Ran into an issue today and wanted to share in case anybody else hits the problem.
Using the good-old cpan client I found myself unable to install a module.
It took me a while to track down the problem...
I had CPAN::SQLite installed and that appears to have a bug
(which I filed as RT 69415):
If a greater version of a dist is removed from the CPAN,
CPAN::SQLite will fail to reindex the "current" (lesser) version,
which means the cpan client will spiral into a 404 loop and give up.
So if you try to install a module and cpan spews 404 errors for a different version than you're expecting, open up ~/.cpan/cpandb.sql with sqlite3 and delete that record with something like:
Ricardo wants to fix smart matching, which is horribly broken and always has been, although we're just starting to realize how bad it really is. He reduces the table to just a few operations:
$a $b Meaning
======= ======= ======================
Any undef ! defined $a
Any ~~-overloaded invokes the ~~ overload on the object, $a as arg
Any Regexp, qr-OL $a =~ $b
Any CodeRef $b->($a)
Any Any fatal
Module::Metadata::CoreList compares module pre-req version #s in your Build.PL or Makefile.PL with the versions of those modules in Module::CoreList, for a given version of Perl.
This can help you specify the minimum version # for the pre-req.
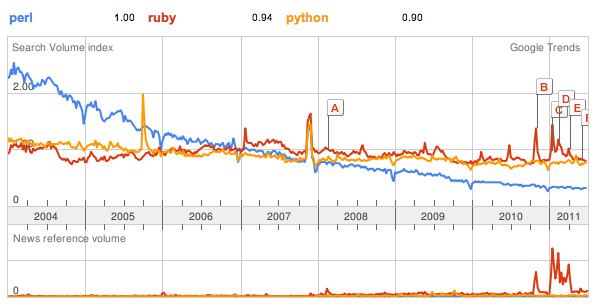
It used to be that my preference for Perl was considered niche; now it seems to be considered outdated. Google trends shows how Perl has declined over the past 7 or so years:
My previous post about a weird do-block bug I stumbled upon has been fixed as of 7c2d9d0,
the day after I posted. I don't know if anybody saw this post or if it was a coincidence, but thanks!
iCPAN hit the app store about a year ago. I didn't really expect there would be a lot of downloads, but the reality is that there was far more interest than I had expected, which is good. After the original app was released, I was able to release a couple of subsequent versions with updated Pod, but it soon became clear that some problems were not being solved.
The first issue was that it was taking a very long time to put a build together, because I had to parse all of minicpan with each run. The second issue was that my coverage was too low, around 60,000 docs. A lot of docs were being missed and there were a lot of edge cases to work out.
About a month or two months ago I started writing together with Smash, a book on CPAN modules and frameworks. The final name and table of contents is not yet fully defined, but some chapters are already popping out.
I put up a simple page where the draft documents will appear. I know the URL sucks, but I might fix it soon. At the moment I made one chapter available.
The final document will be made available in electronic format freely to the community (without that DRAFT watermark, that is there just so you know this wasn't yet revised). Also, a printed version will be available, probably in lulu, but not yet totally defined.
The book is being written in PseudoPod, and it available on GitHub. Refer to the book page for details.
I am happy with comments, corrections and grammar fixes. We know our English sucks. Just try to be positive, or we might end up quitting from this job :)
As a PAUSE admin, I ran into a new problem today. The URI::Dispatch module did not index because it has no package statements and has no provides in META.yml.
This leads me to a couple of questions, for which I invite you to answer:
Just how hard should the PAUSE indexer work to discover namespaces when you work hard to hide them? Remember, at the moment it's only MooseX::Declare, but it might be many other modules later.
What are other MooseX::Declare people doing to have their stuff indexed?
I'm also thinking about this for my BackPAN indexing bits, which uses my module Module::Extract::Namespaces. That's a PPI-based module, which I guess I now have to mutate to understand Moose. I haven't thought too much about that, so I'm not sure how I'm going to do that.
The Astro-satpass distribution contains classes to compute satellite position and visibility. The recent ‘Heads up’ posts were the latest chapter in its life, and that chapter comes to an end with the release of version 0.040. The only code modification since the most-recent ‘Heads up’ was to have the satpass script take advantage of the new lazy_pass_position attribute.
So who uses this distribution anyway? Since it is open source, the only users I find out about are the ones who write me — usually with a problem of some sort. Most of these represent an opportunity to improve the distribution, even if only to try to make the documentation a little clearer.
My impression from the correspondence is that most uses of this package are casual — hobbyists, interested amateurs, and the like. This is not to deprecate those users: I am one myself.
But it appears to be be in serious, day-to-day use in at least four places. These are:
Recently, we had to rework a legacy project using Catalyst. We chose HTML::FormFu as our Form engine because we had good experience with it in other projects.
However, we had to face one problem: Forms had to be different for every user. Well, the difference is based on the user's roles, to be precise.
As a rescue and a generic approach, we chose to create a simple HTML::FormFu::Plugin that can get applied to every or some of the forms, just as needed. To get things working, we need to do two things:
mark certain fields inside the form with the rights we need for editing
have our plugin make the privileged fields readonly
A simple form (in perl syntax) might look like this: