Yesterday I decided to stay with MySQL, but today I face something a little more creative: What should the data model look like?
So far today I've collected a list of all the information I would like to store, and marked out all the information that is currently stored. It doesn't look like I have to add a lot of information, but I'm certainly changing how it's stored.
In the current version of the application a whole lot of the information is stored in static configuration files.
For example, the concept of a "Morph Rule" is a configuration variable.
So a case type is changed in accordance with a "Morph rule".
When this was designed it was not clear how often these things would change or need tuning, so it was hard coded in a way that would make it very fast to load at start-up, and very easy to access while running, but very impractical for the application to change.
Changes are currently done by manually editing .pm files.
Now that you can log in to MetaCPAN via Twitter, Github and Facebook it's trivial to update your author profile. For example, if you look at my author page, you'll see some pretty icons with links to various other sites I care about. All of this takes just minutes to set up and it does two things:
1) It makes your author page sexier
2) It makes you easier to find, follow, pester etc
One aim of MetaCPAN is to make it easier to contact authors in the Perl community. The author info is available via the API. For example, if you want a list of every author to date who has logged in to update her info (91 at the time of writing):
For a long time now I've been saying to anyone that would listen that the only thing preventing Perl from being a good language for desktop development was a lack of decent library support, and a lack of decent tools to make development relatively efficient.
With Padre, we've certainly gone a long way towards demonstrating that building large desktop applications in Perl is possible, and the stresses caused by Padre on it's underlying libraries has driven the improvement of Perl support for the dominant cross-platform GUI toolkit wxWidgets.
With library support relatively mature, and a number of people working on improving installers for Padre and Perl desktop applications, the next outstanding problem is the complexity of the Wx.pm API and the fairly steep learning curve when it comes to producing Wx.pm GUI and dialog code.
So it with great pride that I present the first working production release of Padre Form Builder, the first native cross platform GUI design solution for Perl.
Before I let my enthusiasm overpower me and jump into this rewrite with all it's worth, I have to take a long and hard look at what technologies are being used, and what I want to replace them with.
Swapping out Class::DBI with DBIx::Class is an easy choice, and I'll get back to that in a later post, but what of the engine behind it?
Currently, the whole thing is built on MySQL, but during the lifespan of this fairly complex CRM application I have seen some of the limitations of MySQL up close.
A lot of my contacts and friends also insist that while MySQL is fine for a website or any simple CRUD operations, it will let you down when it comes to more complex queries.
A colleague @$WORK found this: The Development of a Perl-based Password Complexity Filter. I was going to comment in the site about the presented Perl code looking rather like it was a straight shell script port (though the "use strict" pragma and lexicals indicate some safety, but I'm sure the more experienced Perl hackers here can smell worse.) Too bad it needs approved registration.
But that's not what I'm really wondering; are there more password checkers out there in the CPAN? I've seen Data::Password and its ::Simple variant, but a casual search doesn't bring much. I guess those two modules would be ok, if not for the former's use of global scalars such as $DICTIONARY and $GROUPS to configure the checker (I guess I could submit a patch fixing that... what do you think, lazyweb?)
When you upload module to CPAN, PAUSE checks that archive does not contain world writable files, because if
you install files with such permissions, files may be changed by any user.
If files are found, PAUSE creates modified archive, with correct permissions and uploads it with the same name,
only "-withoutworldwriteables" is added. Usually such archives are created by tar on Windows, but they can
be created on Linux too - it depends on permissions of files on authors hard drive.
Solution of this problem depends on which module framework you are using.
Module::Build version 0.31 creates archives itself and does not suffer from this problem.
Users of ExtUtils::Makemaker can:
1. migrate to Module::Build using my App::EUMM::Migrate
2. use ptar from Archive::Tar with "-C" (CPAN) option that I've added. Just upgrade to version 1.66 and add
dist => {
TAR => 'ptar',
TARFLAGS => '-c -C -f',
},
to WriteMakefile call.
For Module::Install you can use Module::Install::PerlTar 1.001, it also uses Archive::Tar 1.66.
Add following code to your Makefile.PL:
use_ptar() if author_context; #from Module::Install::PerlTar
Comments about errors in English can be sent to alexchorny@gmail.com
After just two weeks from the closing of YAPC::NA 2011, the conference survey site has been busy. We have 60 responses so far to the main conference survey, and 312 responses for the talk evaluations. Many thanks to everyone who has submitted their responses.
However, with 75% of attendees yet to submit their survey responses, it would be great to get some more submissions, both for the main conference survey and the talk evaluations. The results are extremely useful to organisers and the speakers, to help improve the conferences and the talks respectively.
If you haven't responded as yet, please check for your unique email with your personal keycode login, and click the link provided. If you cannot find the mail, please check your spam filters first and failing that please let me know and I can resend you your keycode.
For further details please see the Wiki page on the YAPC::NA 2011 site. Results of the Conference Survey will be posted on the YAPC Surveys site at the beginning of August.
The surveys close on Friday 29th July, so you still have just under 2 weeks to submit your responses. Please try and take some time to complete and submit your responses, as they really do help to improve the event for everyone.
Not Perl, mind you, I'm not in that area (yet?). But some key terms I keep hear buzzing around, and, in the tradition of starting the Christmas season in late July, I'll begin my Festivus preparation with some minor Airing of Grievances.
I'm about to embark on a project to rewrite a mod_perl2 application to Catalyst.
I promised mst I would blog about it, or otherwise make the process known, so that others might follow my example.
Sure, I'll do that, but is it really a good idea to follow in my footsteps?
I'll leave that up to you, my reader. I obviously have at least ONE reader, as you're currently reading this. Right?
I can't share any of the source code in the larger context, since I don't own it. My employer would probably fire me outright if I shared the proprietary software, and I'll even do my best to keep my employers name out of this. This is about the process of rewriting, not about my job in general.
I also won't go into the old software too much, except where it's relevant for the rewrite, and I won't comment on the choices made when it was written or anything of the sort. This is about modernizing, not about dredging up the past.
Let's just hope I remember to update this as frequently as I want!
A few friends of mine are currently working on a community website of sorts, which means they'll have tons of user-provided content and interaction. This also means there are possible XSS problems all over the place.
So they stated dutifully adding `| html` all over the place. But that's stupid. It's playing whackamole because this sort of issue will keep cropping up again and again, often only to be noticed after it's abused.
However now it's really easy to fix this by having the html filter applied to all tokens in a template:
To break this down:
This is your typical TT view for your Catalyst app. It uses on Catalyst::View::TT as base class, but defines v0.37 as a minimum. This version (released today) supports the CLASS parameter, which allows you to set the class to be used to create the TT object.
Documentation is a social asset, but it's balanced by a technical debt. Documentation describes code that changes over time. As the code changes, so must the docs.
I want to write good documentation for my Perl distributions, but my standard of "good" documentation requires a lot of effort to write and maintain. I'm working on Pod::Plexus to make it easier. It doesn't replace anything, as far as I know. In fact, I've begun using it with Pod::Weaver in my Reflex distribution.
For example, I tend to write modular, cross-referenced code. Everything but the most superficial interfaces is used somewhere else in the distribution. I'd rather not contrive usage examples, so why not reuse parts of the distribution in the documentation? So Pod::Plexus includes an "=example" directive to insert live code into the documentation.
It has been a while since I've blogged, even more so over a webapp such as this. It has been quite some time even for my own personal blog, which I'm now considering to retire as so much of what I share usually now goes to Plurk (and recently, Google+.) Still, I would like to write more about my Perl experiences in depth, so getting an account on this side sounds like a good idea.
Oh, BTW, introductions are in order: I'm Zak, just another Perl hacker from the Philippines. My day job as the head BOFH of Orange and Bronze has me mostly working with infrastructure like Ubuntu and OpenBSD, and dealing with issues with some Java webapps (*cough*) for clients, but I've been a fan of Perl for quite some time. I currently maintain a couple of CPAN modules, with a third one coming, and have been meaning to break into some more serious web development work with Perl, via Mojolicious.
Most of my distributions are on GitHub and built using Dist::Zilla. As the dependencies of each vary widely and I don’t want to muck up my workstation’s libraries, I set up a local::lib for each distribution’s development.
Tussle, or "Tom's Unicode Scripts So Life is Easier", is a collection of some of the utilities that Tom created to explore various Unicode things. If you've read some of his Unicode treatises, you've probably seen him uʍop əpᴉsdn ʇsod. With his leo script, you can type just like Leonardo too. Some of this will undoubtably be in Pʀᴏɢʀᴀᴍᴍɪɴɢ Pᴇʀʟ (there's a script to do small caps too), but you don't have to wait (that's not CSS doing that).
Besides the fanciful programs, there are various utilities to check the normalization forms, do better case mapping than Perl's builtins do, and various programs to search the Unicode Character Database. I've been having quite a bit of fun playing with them today as I tried to figure out how to write a short description for each.
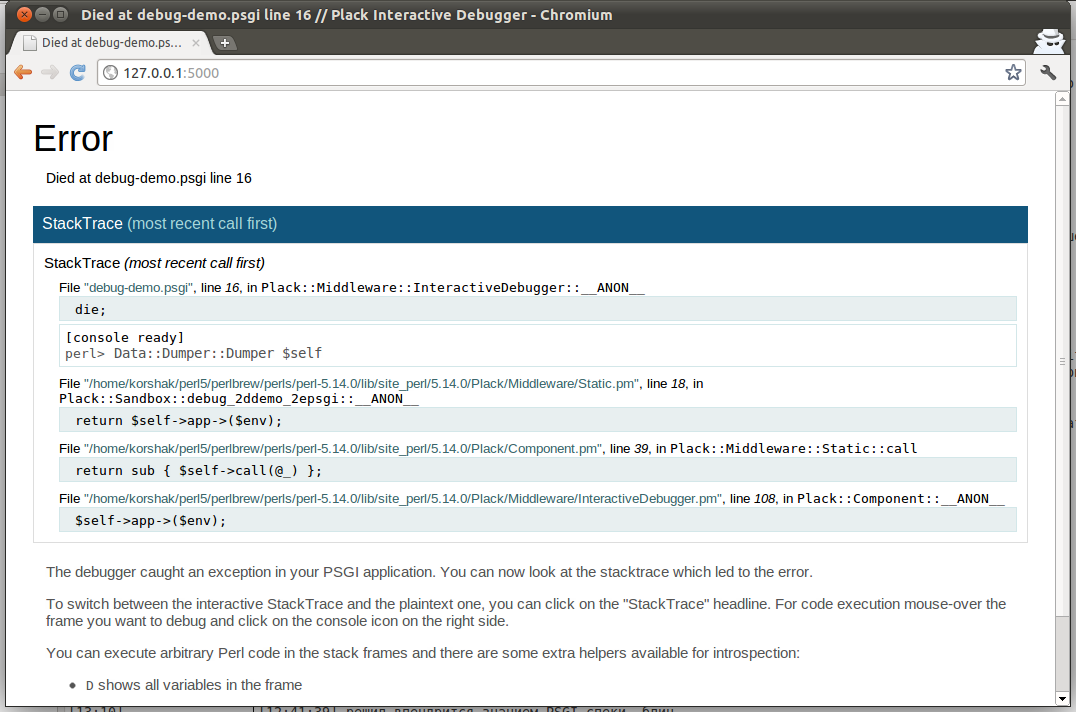
Another tool to debug your Plack application is InteractiveDebugger
You can dive into your code, explore your stack and see all variables in each frame.
And execute arbitrary code at some level!
Just try it:
plackup idebug-demo.psgi
firefox http://127.0.0.1:5000/
It is only one month left before YAPC::Europe 2011 Modern Perl! The conference is on 15-17 August in Riga, Latvia.
Yesterday we reached another record of 200 committed attendees. We know that Perl community is much bigger and would like to see everybody in Riga. People from 40 countries and 60 monger groups are going to attend the conference.
Our talk list is enormous and dense. Three days of four or five talk tracks. Three hours of lightning talks. Track for beginners. Larry Wall Monday morning, Damian Conway Tuesday morning, Jesse Vincent Wednesday morning. Talks about Perl 5, 6, 5.14 and even 5.16. Talks on web frameworks, DBIx et. al., NoSQL and clouds, and much much more.