I am planning on a new project, and a friend suggested me to look to Arango, as an alternative do Mongo, specially because it includes a graphs query language integrated. As I am not really used to Mongo at all, decided to give it a try.
Unfortunately I did not find a proper module to use Arango from Perl. Therefore I decided to start one from scratch. Probably not a great idea as my free time is likely non-existent. But nevertheless, I did it.
I am trying to abstract major entities (database, collection, document, cursor) in order to use them directly as proper objects in Perl, and at the same time, try to keep a low code profile, delegating most options directly to Arango REST interface. In order not to be too relaxed, I am using JSON::Schema::Fit to validate the parameters sent to Arango API.
Language specification of SPVM 1.0 is described in this document. SPVM is in beta testing for the 1.0 release. Language specifications are subject to change without notice.
The Perl Toolchain Summit (PTS) is taking place later this month in Marlow, in the UK, as previously announced. This event brings together maintainers of most of the key systems and tools in the CPAN ecosystem, giving them a dedicated 4 days to work together. In this post we describe how the attendees are selected, and how we decide what everyone will work on. We're also giving you a chance to let us know if there are things you'd like to see worked on.
This blog post is brought to you by cPanel, who we're happy to announce are a Platinum sponsor for the PTS. cPanel are a well-known user and supporter of Perl, and we're very grateful for their support. More about cPanel at the end of this article.
Create a script to generate 5-smooth numbers, whose prime divisors are less or equal to 5. They are also called Hamming/Regular/Ugly numbers. For more information, please check this wikipedia page.
Regular or 5-smooth numbers (or Hamming numbers) are numbers whose prime divisors are only 2, 3, and 5, so that they evenly divide some powers of 30.
A Perl 5 Solution
Generating just some 5-smooth numbers is a trivial problem. For example, if you want 6 such numbers, you only need to generate the first six powers of 2 (or the first six powers of 3, or six powers of 5), as in this Perl one-liner:
The saga goes on! This time we talk about enviles, a way to pass key/value pairs without polluting the environment while still keeping it dumb simple. Find the article here: Dibs - Envars Envisaged As Enviles and, as always, enjoy!
Hopefully, the sesquipedalian polysyllabalisation of the title will have made your eyes glaze over. Now to wake you up: MASSIVE PERFORMANCE GAINZ!
Memoising, as any fule kno, is storing answers after they're calculated, against each set of inputs, so you don't have to keep re-calculating the same thing. If the calculating process is expensive, or even just more expensive than normalising (see below) and a lookup, this can make your programs run faster. Possibly much faster!
This is a thing that works great for computing factorials or Fibonacci numbers. It's a terrible idea for calculating the lengths of simple lists, since normalising would take longer than simply recalculating, and worse would be very unlikely to give repeated hits.
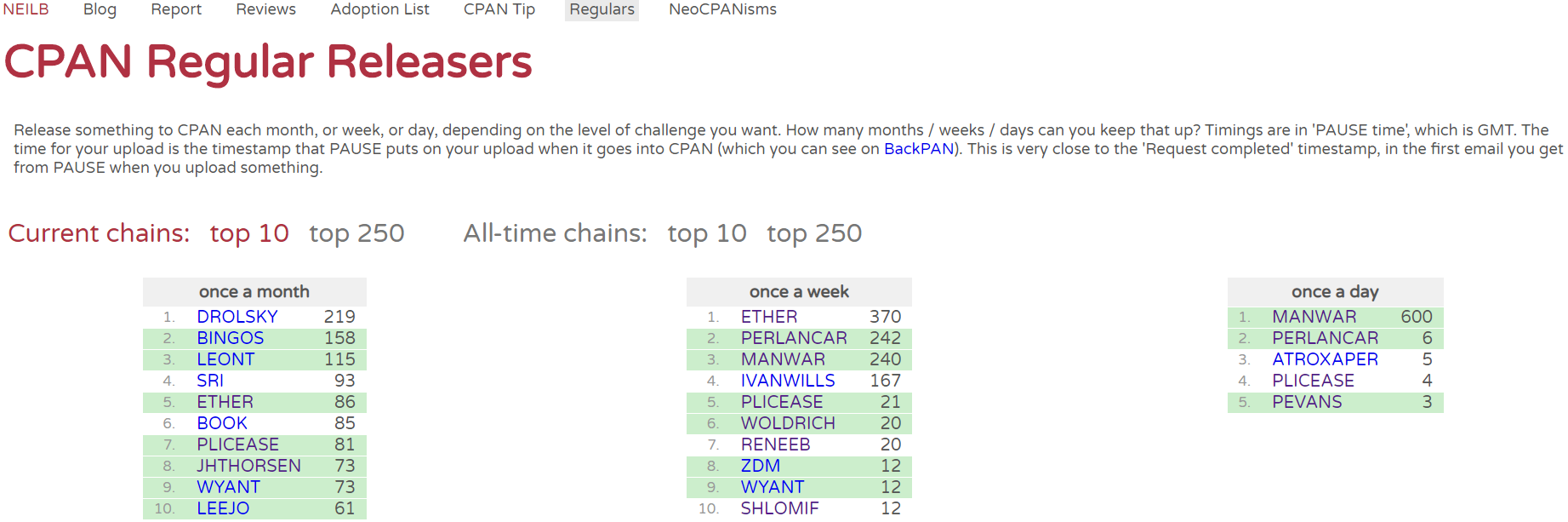
Today is a very special day for me, why? I have now completed 600th day daily upload to CPAN. So what is the big deal? Honestly speaking it is not. Having said that I enjoyed playing this CPAN Game and would like to continue as long as possible. Where did it all started? Well it was one of the blog by Neil Bowers that inspired me and introduced to the fun game. At that I point, I only had handful of modules to work with. I knew I needed lots of distributions to get me going. Nearly a year later, Barbie blog about his completion of one year of daily CPAN upload.
OWASP (Open Web Application Security Project ) is a project that is focused on the visibility of software security and it needs our help updating its wiki entry on Perl related technologies.
Why am I posting this? Well a few months ago OWASP had listed Perl in its list of programming languages but presently Perl has been removed from the listing and I assume this is due to the fact that the Perl section has not been updated.
So if you are still reading this and you are a contributor to any of the Perl 5 and 6 ( cuz why not ) Web frameworks that are in use and available today please consider taking some time to update the OWASP Perl wiki.
The wiki needs updated information about the Web Frameworks that exist for Perl 5 and the available plugins used for Authentication, Authorization and Password policies. The current list of web frameworks listed on the OWASP Perl wiki are ( Catalyst, CGI, Dancer, Jifty and Mojolicious )
Please Note: Wiki Account requests to the OWASP wiki system are subject to approval by the OWASP organization ( so I can't guarantee an immediate response to an account request.)
- Debian Stretch 9.8 and Linux Kernel 4.15.
- New installation wizard for Ceph in the UI,
- New HA policies freeze/fail-over/default for greater flexibility,
- Suspend to disk/Hibernation support for Qemu guests,
- Support for Universal 2nd Factor (U2F) authentication,
- Improved ISO installation wizard,
- New options for Qemu guest creation wizard
As we're building Tau Station, a narrative sci-fi MMORPG written in Perl, we've encountered any of a number of challenges, not the least of which is that this is a very "write-heavy" application. Further, because it's a universe where people interact, there's often no clear isolation between what you can change and what I can change. Thus, there's a lot of writing to the database and often to the same data!
By now you've probably heard of the Object-Relational Impedance Mismatch, which is just a fancy way of saying "collections of objects and databases aren't the same thing."
One problem which is particularly difficult is handling "syndicate credits". Syndicates ("guilds" in other MMORPGs) can tax their members and every time a member gets credits deposited in their bank account, a certain percentage goes to the syndicate. So let's say two syndicate members each earn 100 credits at the same time, paying 10% tax to their syndicates. It can look like this:
It runs tests using a precompiled working version of rakudo.js fetch from npm using a roast revision we know passes.
What's missing or fudged?
Tests that are broken under precompilation on all backends
In the browser we precompile tests before running which means the tests are run differently then
how they are tested on other backends.
As a result a whole bunch of tests fail under precompilation even on the Moar backend.
They need to be fixed as they are real bugs in Rakudo on all backends (as most proper codes
tends to live in precompiled modules not scripts) but that's work separate from the js backend.
Tests that don't make sense in the browser itself.
These are some answers to the Week 2 of the Perl Weekly Challenge organized by the hugely prolific CPAN author (and, besides, very nice chap) Mohammad S. Anwar.
Challenge #1: Removing Leading 0's
Write a script or one-liner to remove leading zeros from positive numbers.
A Perl 5 One-Liner
This uses a simple regular expression to remove zeros from the start of the string. Here, we're just using bash for piping four lines with input numbers to a very simple 7-character Perl 5 one-liner.
This year's Swiss Perl Workshop is just a few months away, and we're looking forward to another interesting and fun event in Olten. The workshop takes place just a week after this year's The Perl Conference in Riga so perhaps if you're attending one you could spend a little more time in central Europe and attend the other, and if you're planning to give a talk at The Perl Conference then...
Either way, we encourage you to submit talks and we welcome a broad range of subjects, your talk does not have to be specifically Perl related. Share your experience with others, be it your daily messing around with bugs, writing interesting modules, hardware hacking, Perl 5, Perl 6, devops, and so on.
One thing to note for any attendees is that the wonderful kitchen crew from previous years will be helping us again in Olten, and we would like to give them a list of dietary requirements as far as possible in advance. If you need to let us know of this then please tell us by adding information to the SPW Wiki here.
We look forward to seeing you in Olten this August.
Great thanks go to our sponsors, who have already committed to the event:
Thruk is a multibackend monitoring webinterface which currently supports Naemon, Nagios, Icinga and Shinken as backend using the Livestatus API. It is designed to be a 'dropin' replacement (for Nagios web UI etc) and covers almost 100% of the original features plus adds additional enhancements for large installations and increased usability. Written in perl.
(I am not a project contributor, just a fan who uses it and has "upgraded" several $clients from Nagios to Thruk+Naemon)