This year the ongoing support of sponsors such as CV-Library have meant we’ve been able to add conference t-shirts for attendees. Thank you CV-Library for your continued support of the workshop and local Perl community.
I think there will be very little new code today but I did incorporate a large volume of changes. First I dropped 'Database::Accessor::Roles::AllErrors' as I no longer see any DAD writer ever having any user for it not that it does not throw an error;
The code from that I added into the 'Database::Accessor::Types' and I did not even have to make a single change to the code. I also took out all the commenting out junk code and waring from that class for good measure.
I then went into Accessor.pm and made the following change;
– sub _loadDADClassesFromDir {
++ private_method _loadDADClassesFromDir => sub {
The contemporarily unique strengths of CGI as a deployment strategy are that CGI scripts ⓐ can just be dumped in the filesystem to deploy them and ⓑ do not have any of the issues of long-running processes: they tie up no resources when not in use and are extremely reliable because of the execution model, in which global state always starts from a blank slate when serving a request and there is no process that outlives the request and could wedge itself. Anyone who consciously chooses CGI over alternative deployment strategies nowadays probably has a fire-and-forget use case where the script will be seeing too little traffic to be worth any effort to tend to it regularly.
Sponsors make it possible for us to run LPW without charging for tickets, and as an organiser last year Pete Sergeant knows just how important this is! Thank you Perl Careers for your ongoing support.
Its hold your head in shame smarty pants day here in the Moose pen.
So here I am with a little 'mea culpa' for yesterday post. I had what you would call a real newbie flaw to to that I should of caught right away.
Now it was not in the re-factoring or the implantation of the re-factoring that was all ok my problem was assuming that the coercion of my objects was not happening on a new. Of course it was so when I hit the test where I had an coercion error on new on a coerced object I was getting a double fail that would wash out my original fail.
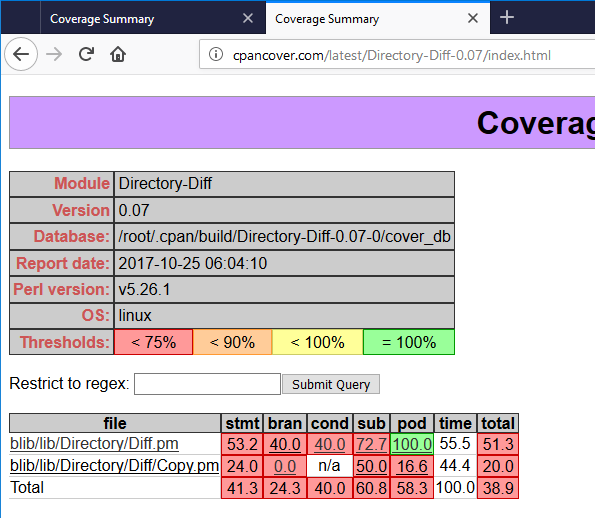
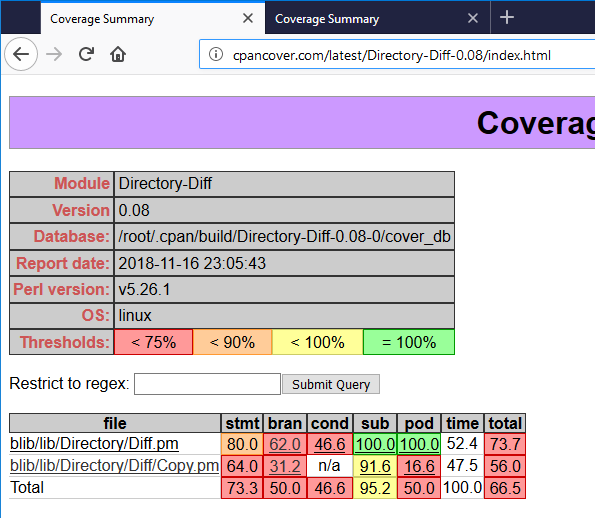
to find out how to tell it that these routines were never meant to be documented, but couldn't find anything except for a regular expression which ignores routines with a leading underscore.
Can anyone tell me how to tell the coverage meter to not measure these routines?
There is less than a week left until the 2018 edition of the London Perl Workshop on Saturday the 24th of November.
If you have not signed up but want to come, there is still time to register for your free conference ticket. If you have already signed up, please make sure you have confirmed your attendance and selected a t-shirt size. We can only get a conference t-shirt for you if you've done this by tomorrow (Tuesday) at 12:30 GMT.
Are you already in town on Friday evening? Come to the social event and meet your fellow Perl Mongers. We will meet at The Hope in 15 Tottenham St, W1T 2AJ from 6:30pm in the upstairs room. Drinks at the event are sponsored by Oleeo.
Not a good way to start another year of blogging as I was reviewing my tests and when I got into '47_dynamic_gathers.t' I was getting a duplication on the number of conditions on a gather which is not a good thing.
Somewhere in the last few days I really buggered something up.
Well after much hair pulling and debugging I finally stumbled into it. It seems I have added so many warns and comment out code over the past few days I was playing with subs that look like this;
If you're a Perl developer in the Charlotte, NC area, come to the first social event for the Charlotte Perl Mongers! For more details, or to RSVP, check us out on Meetup.
With the workshop just over a week away we have created the schedule. You'll notice we still have room for a few talks, so if you have something you would like to talk about then don't hesitate to submit a talk
We have tweaked the schedule a bit from previous years to start a little later than normal and allow a little more time for lunch. You'll also notice we have a dedicated Perl 6 track and a dedicated "mentoring / beginners" track.
We also have room for more lightning talks and will favour those that are submit early. Note we may tweak the schedule slightly to make room for more talks and/or depending on other factors.
Final final final clean up day here in the Moose-Pen
Just a quick postette today cleaning up the last of my messages on my error retruns. Starting with this one;
'Database::Accessor Database::Accessor::add_condition Error:
The following Attribute is required: (conditions->left)
With constructor hash:
{
'predicates' => {
'operator' => undef,
so two thing to get rid of here, get rid of that 'Database::Accessor::' in front of 'add_condition' and change that constructor has so it dose not show that hidden 'predicates' key
the first fix is easy enough;
After this weeks discussions about naming a shovel a spade, and how that would increase sales in the hardware store. I hope to start a substantive discussion around promoting Perl.
Dear Reader, please don't let the above metaphor become a stumbling block. Your ingenuity is desperately needed.
The first hypothetical question I would pose is:
If you had $10,000 to promote Perl - what would you do with it?
Please don't get lost on the dollar figure. This is intended to be an exercise in stretching the imagination.
Another question pair is:
What meaningful metrics could be used to measure Perls growth? (github stars? ithub commits? cpan releases? others?)
What activities could be co-ordinated and performed, that would increase these key metrics?
A quick Google search (or, DDG) provides many peoples thoughts about growing open source projects:
After fixing some strangling bugs and implementing some unimportant but fickly to implement
features rakudo.js now passes our targeted test subset. Some of the fickly features where
things like basic support storing fetching and ++'ing int64/uint64 variables etc. (rakudo.js is 32bit because that's what fits into basic JavaScript numbers).
Focus has now moved to running the roast tests in the browser itself.
For this I'm first precompiling the test files (which has it's own share of problems that I'm working around as rakudo doesn't yet fully support precompling scripts only modules).
For example all the compile time deps are recorded with a custom CompUnit::Repository
Then I'm bundling them together with parcel into a single .js file.
I'm running it with a Karma runner and Headless Chrome.
When running under karma the nqp runtime intercepts the TAP on STDOUT and reports the results to the karma harness.
After a brief break (and local hosting of The Perl Conference 2017), we are again hosting the DC-Baltimore Perl Workshop in Silver Spring, Maryland on Saturday April 6, 2019! The day will be dedicated to two tracks of Perl-related technology talks, targeting all levels of programming experience.
I've like to propose adding a ROADMAP section to module documentation.
It would be a *short* summary of planned changes for future versions, noting what features would be removed or changed, or upcoming new features that will be added.
More detailed roadmaps should be put in a separate file (e.g. `ROADMAP` or `ROADMAP.md`) that should be referred to in the section. Or link to the roadmap if it's online.