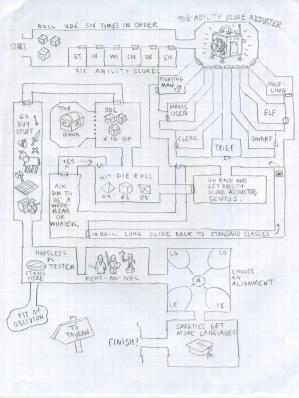
As most of my recent posts have been looking at what nice little goodies Moose has to offer and I now that I have solved my last role problem I figured it was time to take a little break from coding and look as general Design a little
I could just do like the old days and draw something up like this;
It think (well know) that there is a mindset out there against this sort of work, I know I have been told many times by 'Pointy Headed Boss Types', to stop that nonsense and get back to work and even once got fired for doing it.
I had mapped out a rather piss poor DB design and hung it on my cube wall. I was told I wasted company time by creating it. At the 'Warning Interview' I had to admit I was distracted, not by doing the diagram but by the steady stream of other developers who come into my cube to consult it.
I say this is "beta" because it can only compile "Hello, World" so far! But we have working data-types support, and it is relatively easy for me to finish up the rest of the control structures and basic operators to get the full RPerl v1.0 release out soon.
Sub::Trigger::Lock is a workaround for the problem that Moose read-only attributes aren't really read-only; at least, not in the way that people might expect them to be. Here's an example:
packageFoo{useMoose;hasbar=>(is=>'ro',isa=>'ArrayRef');}my$foo=Foo->new(bar=>[1,2,3]);push@{$foo->bar},4;# does not die!
I left off on my last post stubbing in a little code to take care of loading my 'Player Class' (Fighter, Thief etc) into my 'Character' class. I did mention that there are some real subtle rules, I will look at just one of them.
Unfortunately 'Mordol the Moose' rolled a '1' and failed his 'Saving Throw' vs traps and ended up like this;
Like 'Player Class' at first glance it looks very simple thing to do '4 Player Classes' and '5 types of saving throws' for each. Well what happens if you player is 'Mutil-Classed' such as 'Gutboy Barlehouse' a 9th/8th level Dwarf Fighter/Thief. In the game saving throws for a muti-classed player always use the most favorable result from the tables. So there are times when 'Gutboy' saves as a thief or saves as a fighter.
Happy new year, and welcome to Planet Moose, a brief write up on what's been happening in the world of Moose in the past month, for the benefit of those of you who don't have their eyes permanently glued to the #moose IRC channel, or the MetaCPAN recent uploads page.
If you'd like to contribute some news for next month's issue, you can do so on the wiki.
Perl Advent Calendar
There were a handful of Moose/Moo-related articles in the 2013 Perl Advent Calendar:
In my last D&D post I had at least the first problems worked out for Character race. Now I think I will move into the most challenging of all the 'Class' of a character.
In D&D a 'Class' is the role (JOB) a character plays in the game ie fighter, thief, mage etc. There are 5 primary Classes and 5 sub classes which is easy enough to model with Moose a 'Role' for each of the 10 and we are done.
Unlike the epic adventures above a character's 'Class' is not that easy to nail down. The rules around class are a mix subtle complexities, there may be only 5 basic 'Character' 'Classes' for 'Players' and 'NPCs' but each Character falls into one of these types
NPC with no class ie (0 level human farmer, Halfling barkeep, etc)
NPC or Player with a single class (Fighter, MU, Cleric)
NPC or Player with multi-classes (Fighter/MU, Cleric/Assassin)
NPC or Player with two Classes (Fighter-MU, Cleric-Fighter)
Just now, I've uploaded three distributions to PAUSE: Sereal-Encoder-2.01, Sereal-Decoder-2.01, and Sereal-2.01.
This means that version 2 of the Sereal serialization protocol is finally considered public, stable, and ready for production use. There was a long article about Sereal v2 on the Booking.com blog a few months ago. Since then, at least one major new feature was added to Sereal version 2: Object serialization hooks (FREEZE/THAW). Let me summarize the two major user-visible new features.
In a recent post, Chris K asks, why do I recommend using function() rather than &function() or &function. I happened to see it right before heading to bed, but I wanted to respond, so who knows if this is a good example or not. Anyway here goes, look at this code (seen below if you have javascript), it prints 6 lines, do you know what they will be?
In trying to find places that I might be able to exchange links to get traffic to my tutorial site, I found an article about how one should determine if a tutorial is good. One of the things that they mention is that a tutorial that teaches
&subname()
as a valid subroutine calling convention is out of date. It continues to explain that this does do something, but not what people think it does.
As a matter of fact, I just finished writing a major tutorial on subroutines myself last night. I have looked at numerous resources, all of which say
&subname;
(I know that's slightly different, but similar enough to cause alarm)
and
subname ()
are both acceptable. I looked again today, and found the same information. So could someone please clear this up...what (if any) difference is there between these two conventions, and am I making some major mistake if I write tutorials with the ampersand method?
I'm relatively pleased with my work in creating parallel testing with Test::Class::Moose, but I wanted to make sure that it worked with a real world example, so today I took a small, but real test suite and converted it and tried out my parallel testing code. The results were interesting.
The purpose of Alien modules is to provide external libraries or other dependencies for CPAN packages. This Alien2 Manifesto updates the original Alien module description based on practical lessons from existing Alien module implementations and some perceived limitations.
The original Alien manifesto provided the idea but not a framework for how modules in the Alien namespace were to work. The plan was to "let evolution work for us and see what individual Alien packages need and then eventually factor it out". We are now more than 10 years after this first proposal and there are now some lessons to be learned from current implementations of Alien modules. Let's start with a review of the responsibilities of an Alien module and some observations.
On installation, make sure the required package is there, otherwise install it.
This is the main purpose of Alien modules, to provided external library or program dependencies needed for CPAN modules installation and operation.
In my last post I again ending up like poor Keith Haring in his picture below.
I programmed what I wanted but it was beginning to look like the same stuff I started with.
So playing around a bit I remembered that Moose has the before, after and around Method Modifiers that work like DBI's callbacks that some of you might remember form one of my earlier posts. The great thing about these is that can be used from inside a role for code outside the role as long as the code is referenced in a 'requires'.
So I to move the max values out of the Character class and into the Dwarf role I gave this a shot
There's a common programming challenge where you write a program to take a dollar amount from the user, and then return the simplest way to create that amount with only coins (using the fewest coins possible). I took a crack at this a while back, and I would like to know if there are ways it could be improved or if you would have done it differently.
This is part 4 of an ongoing series where I explore my relationship with Perl. You may wish to begin at the beginning.
This week we look at code legibility.
Last week I talked about why Moose is important to my journey as a Perl programmer, and where I feel that it could be even better. I concluded that it all comes back to code legibility.