I was pleasently surprised to find out that there is already a Plack Middleware that improves security against CSRF attacks. And it's very easy to use.
I'll demonstrate with a Catalyst example but any app running with Plack can make use of it.
In your application you simply configure the middleware.
(Note: Plack::Middleware::CSRFBlock depends on Plack::Middleware::Session)
# lib/MyApp.pm
use Catalyst qw/ EnableMiddleware /;
__PACKAGE__->config(
# ...
'Plugin::EnableMiddleware' => [qw/
Session
CSRFBlock
/],
);
And that's it. From now on CSRFBlock adds a token to your forms and when you submit the form it will check if the token is valid.
I've always found it difficult to comprehend the relationships between all the Perl modules in a large application. So for a long time I used GraphViz to create dependency graphs. But I was never quite happy with them because they were fairly static and hard to understand once you had more than a couple dozen modules in play.
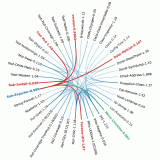
Then a few weeks ago, I discovered D3. The sample gallery has a very nice interactive dependency graph. Since it is organized in a circle, it scales to a large number of modules very well. So now, every repository on Stratopan will have graphs like this one (click the picture at left to view the interactive demonstration).
The graph isn't as intuitive as I would like yet, so let me explain a bit... What you're seeing are the relationships between all the distributions on a "stack" in a Stratopan repository. In this case, the stack contains everything required to build, test, and run Perl::Critic. When you hover over a distribution name, the relationships are highlighted. Dependencies (i.e things it requires) are connected with red lines, and Dependers (i.e. things that require it) are connected with green lines.
Over time, I hope to add more helpful visualizations like this to Stratopan. If you've got some ideas, I'd love to hear them.

When I first read about the idea to remove CGI.pm from core, I was like "Yeah!". And then I thought about it and I was like "meh".
Who cares? Your typical noob that needs to be protected from the horrors of CGI.pm is not the kind of guy who builds his own perl. He is also not the kind of guy who uses an up-to-date perl. He probably has some company server running 5.8 or he might use whatever his hoster installed. Before he learns that there even is a core, he'll have a zoo of spaghetti cgi-scripts that won't work when using strictures.
But here is someone who will care about a missing CGI: the package maintainers of all the Linux distros out there. They will have to decide whether to pack CGI.pm into their main perl-package or whether to put it in its own new package. Since there are about a gazillion packages that quietly depend on CGI.pm, their most likely choice will be the former option.
So what I am trying to say is: You will not kill CGI.pm by removing it from core. But removing it from core will also not be noticed by any kind of user who doesn't know how to use a cpan client.
I just read chris fedde's response to Ejecting CGI.pm From the Perl Core, my head nodded in agreement from start to finish. It helped me clarify a few of the thoughts and concerns I've had bouncing around in my head for the past several days.
So here goes: I think it would be a mistake for perl core to not "Dance with the one that brung ya".
How many of us are using Perl because of CGI.pm? When I first got my feet wet with programming it was for the web, using Perl. It was a good month before I got a feel for where perl ended and CGI.pm began. At first they were very much one in the same.
[ This is cross-posted from its home on the Ocean of Awareness blog. ]
Marpa works very differently from the parsers
in wide use today.
Marpa is a table parser.
And Marpa is unusual among table parsers --
its focus is on speed.
The currently favored parsers use stacks,
in some cases together with a state machine.
These have the advantage that it is easy
to see how they can be made
to run fast.
They have the disadvantage of severely limiting
what the parser can do and how much it can know.
What is table parsing?
Table parsing means parsing by constructing a table of all the possible parses.
This is pretty clearly something you want -- anything less means
not completely knowing what you're doing.
It's like walking across the yard blindfolded.
It's fine if you can make sure there are
no walls, open pits, or other dangerous obstacles.
But for the general case,
it's a bad idea.
Call For Papers is now open for YAPC::Asia Tokyo 2013!
As I have previously posted here, YAPC::Asia Tokyo is the world's LARGEST YAPC. Last year we brought 841 people together for the two day geek-fest. This year we're doing it again in the lovely Keio-University Hiyoshi Campus.

Why not come and mingle with the Japanese Perl hackers? If you use tools like Plack, Test::TCP, Parallel::Prefork, Mouse, plenv, etc then you're got to come talk to their authors! Meanwhile, we'll be even more delighted if you choose to give a presentation. Please submit your talk proposal here
Should you need more info/help, please contact @lestrrat on twitter. I'll be more than happy to help you get to this conference!
In Ejecting
CGI.pm From the Perl Core chromatic discusses the pending deprication
of a storied module. I needed to address a perhaps overlooked aspect
of the argument.
Nearly all web ui are written to support small usergroups inside some
kind of organizational infrastructure.
Very few websites are moderate to large. Most are small. With maybe
a few dozen to a hundred or so users. Most are tools used to provide
some internal organizational function. Not to serve media websites to
thousands viewers or general public readers. On the complementary side
of this, most perl users have some other axe to grind. Web development
is at best a side interest. Or maybe a self defense skill they picked
up out of a need to automate away some function of their job.
I have just ranted about removing old bad code from the Perl core. Let me lighten the mood by talking about some good, new code.
I have loved Moose for some time now, but like others, I disliked how heavy it was. Then Moo came along and it was great … until I found myself not availing myself of the type system, because it was harder to get to than in Moose. I was skipping validation more and more.
A recent project came up and I really wanted to do it right, so I tried Toby Inkster’s new Type::Tiny and may I say, “hat’s off to you sir!” The combination of Moo and Type::Tiny brings that Moosey feeling back, while still being light and responsive and even fat-pack-able! Great work to all involved in both projects!
Welcome to Perl 5 Porters Weekly, a summary of the email traffic of the
perl5-porters email list.
Topics this week include:
- perl v5.19.0 is now available
- blead is now thawed
- RFC: Deprecating Module::Build
- Perl 5 Porters BOF at YAPC
- Committers: PLEASE run test_porting before pushing
- RFC: Removing CGI.pm from the core distribution
- I made t/podcheck.t less sensitive and fixed various pod issues
There is a reason large software companies provide free or relatively cheap license for their super-expensive software to students.
When these people finish school and look for a job, they will already know how to use that super-expensive software and not the other one.
So when a company hires them, either they let the person use this super-expensive program they need to train the person to use the other one. Even if the other one is free of charge, the training cost and the time it takes to get up-to-speed in that other tool will mean that most companies will opt for the software that has a larger pool of knowledgeable users.
With programming languages there is a similar effect.
Yesterday I came across another Perl-related site, called PrePAN, that asks me to log in with some other site's login information. I've seen this before on MetaCPAN and Play Perl and it makes me very uncomfortable. It goes against the security advice that I've been given for decades.
I’m sure most of the readers of this blog will have seen that both Module::Build and CGI.pm are up for removal from the Perl core. I thought I would toss my $0.03 (inflation) in on the matters.
My Polish Perl Workshop talk on taking an existing Perl installation and creating a CPAN-like repository that would create it.
Stratopan is a slick new service for hosting custom CPAN-like repositories in the cloud. I've been doing all the development work for Stratopan on my laptop computer. But the other day, I decided to try running it on the Linode server I rent.
So I logged in to the (nearly pristine) server, fired up cpanm to install all the prerequisite modules, and launched the application. Lo and behold, it was broken! Read on to find out how Stratopan actually saved me from hours of debugging pain...
Today I was looking at old automated Perl test based on Test::WWW::Mechanize. It was it testing a complex form. For each of about 10 tests, it loaded the form (with a get_ok() call), and then submitted the form with a variety of input.
Now that we run about 25,000 tests in total in the test suite, I’m always looking for ways to speed up the tests. HTTP calls are relatively slow, so systematic ways to slim them down are attractive.
In this case, I found there was a simple change that I could apply that sped up the particular test by about 28%.
Each time the test was calling get_ok() on the page, it was getting back the same result, which is wasteful. I refactored it like this:
my $base_mech = Test::WWW::Mechanize->new;
$base->get_ok($page_to_test);
Then, everywhere we had a get_ok() call to load the page again, I replaced it with this:
the Chief Ticket Monkey of the Perl Mongers.
24.17 min of video or audio only.
And yet another short status update for the GPW 2014. The official Act-website is now available. You're now able to register and to submit talks.
http://act.yapc.eu/gpw2014/
German version: http://www.perl-community.de/bat/poard/message/167756
 I'm at a conference in Portland this week to learn about a web framework called Symfony2 for my $DAYJOB. The Symfony2 stuff is all co-located with DrupalCon 2013 and one of the rooms across the hall from our workshop was for Drupal sprints. The sign in the picture was posted outside - and it makes it super clear that newbies are welcome, and who they should try to find to get going on a task quickly.
I'm at a conference in Portland this week to learn about a web framework called Symfony2 for my $DAYJOB. The Symfony2 stuff is all co-located with DrupalCon 2013 and one of the rooms across the hall from our workshop was for Drupal sprints. The sign in the picture was posted outside - and it makes it super clear that newbies are welcome, and who they should try to find to get going on a task quickly.
This is an idea we need to steal for Perl hackathons.
CPAN authors should look at the smoke tests for their modules to ensure that they're passing on Perl 5.18. The hash randomization change (and a few others) has bitten many a module that may currently be relying on undefined hash behavior. If you haven't checked your modules recently, you may be in for a surprise.
The problem is significant, especially when compounded by the fact that a single misbehaving module can block many more modules that may depend on it.
As an example (not to finger-point, but just to illustrate): Crypt::DES, Crypt::IDEA, Crypt::Blowfish, and Crypt::Twofish had a single line of XS code that was incompatible with Perl 5.18 (which happened to not be related to hash randomization). As a result, all modules that depended on any of these modules also would fail to install on Perl 5.18. This includes Authen::Passphrase, and Crypt::OpenPGP, as well as dozens of others.
Interested in meeting new people at YAPC::NA? Hallway++ means you're never interrupting