So I have sketched out my test suite lets have a look at the API I am trying to express.
For me the API is the most important part design. Have a good workable general purpose one it will become a de-facto standard, like DBI, do a very narrow one it will languish in the niche that is was designed for. It has been said many times before, but it bears repeating here, that any API should be
Easy to Learn
Easy to Use
Easy to Extend
Consistent and
Hard to misuse
Well on the higher level my Data Accessor will be easy to use with just the basic four CRUD operations so that should be easy to use and learn.
We're very happy to announce that SureVoIP are supporting the QA Hackthon as a gold sponsor.
SureVoIP® (Suretec Systems Ltd.) is an Ofcom-registered Internet Telephony Service Provider supplying Hosted VoIP solutions, SIP trunks, UK inbound numbers, International SIP numbers, a partner program, public API (powered by Catalyst) and other related VoIP products and services.
Having failed to find a working profiler on npm I ended up webpacking nqp-js-on-js and profiling it directly in Chrome.
It turns out the first big slowdown was the lack of multi caching.
I implemented them.
The second big slowdown was actually the slurp() function.
MoarVM doesn't handle concatenation large amounts of huge strings very well so the cross compiler so instead of concatenating bits of javascript code it's often much faster to write them to disk and then slurp it back in.
On the nqp-js-on-js due to a misset buffer size slurp turned out sluggish.
Due to profiling a webpacked version (which doesn't do IO as it runs in Chrome) this has baffled me for a bit.
Changing the nqp::readallfh buffer size from 10 to 32768 speed up stuff a lot and I'm back to compiling rakudo.
Based on the output of the profiling there seem to be a few low hanging fruit optimalizations for bunch of easy ~5% speedups but I'll work on them later on as having actual Perl 6 running instead of NQP will give me a better vision of how we want to optimize things.
I think subroutine signatures don't need arguments count checking,
because performance is more important than utility.
Subroutine signature should be optimized from performance perspective, not utility.
Arguments count checking is one logic, so it damage run time performance.
And I like simple and compact syntax.
sub foo($x, $y) {
...
}
# same as
sub foo {
my ($x, $y) = @_;
}
Well lets see as I am in a testing mode right now lest have a quick look at the DA.pm's expressed API to see what I should test or at least how I should organize my tests.
Always start with the basics so I will have
00-load.t
that will do your basic load checks to see if it will work on the perl that is trying to run it. No need to go into details there.
As well I will add in a
02-base.t
And this will test just a little more than load. Perhaps the use of a driver and some basic set and get checks of the higher level stuff.
I have updated perlmodules.net with an important feature.
PerlModules.net is a site that notifies you whenever your favorite Perl modules get updated.
Up until now, it let you track changes to your favorite modules through an RSS reader. If you wanted to receive email updates instead, you had to use an RSS-to-email gateway, but that didn't work too well (important color and styles were lost from the text, and the emails were full of advertisments).
From now, perlmodules.net sends its own emails to the users. It is opt-in, so if a user doesn't provide their e-mail address and check a checkbox at their feed's page, they won't receive any emails, plus all emails sent contain an easy unsubscription link at the bottom.
Although YAPC::Europe::2016 preparations are well underway in Cluj, it
is time for the venue committee of the YAPC::Europe Foundation (YEF) to
think about the location of the 2017 conference. YAPC::Europe wouldn't
exist without dedicated teams of volunteers, and we are always excited
to see the enthusiasm and learn about the new ideas the community has to
offer.
Further information about preparing a complete application can be found
on our website.
Proposals submitted to the venue committee will be added to
this public repository (you may provide
private information separately) to benefit future organizers.
The deadlines which apply to this portion of the procedure are:
Friday, 20 May: Deadline for sending a letter of intent. This letter
simply expresses interest in hosting the conference and provides contact
information (both email and telephone) for at least two organizers. This
is an optional step but it can be to your advantage to alert the venue
committee of your proposal.
Thursday, 7 July: Deadline for sending proposals to host YAPC::Europe
2017.
If you do not receive a confirmation for your letter of intent or
proposal within a couple of days, please personally contact a member of
the venue committee.
Please send your questions, letters of intent, and proposals to
venue@yapceurope.org.
In which I show the tools that I use to clean up and cut releases
In the 12 years I've done CPAN releases, I have acquired my share of experience
through botched releases of modules. Much of that experience has dribbled
into tools and a release process that is mostly automated to allow me to release a module
at the end of a hacking session without needing any mental strength to remember things. My judgement also gets clouded when I'm fixing a module in anger, so having Perl keep me honest and preventing the more obvious failure modes is highly convenient then.
Well I would not be a very good CPAN programmer if it did not think of a set of tests before I started any project so let take a look at what I have.
Fortunately for my Data Accessor (still haven't come up with a new name for it) I have inherited a rather large test suite of about 200+ tests. Unfortunately for my Data Accessor I have inherited a rather large test suite.
Logdog is yet another sparrow plugin to analyze various log files.
One my use logdog for various tasks like finding errors in nginx/apache logs or inspecting suspicious entries in your sshd log file.
One killer feature of logdog is it parsing log lines for the given period of time. Like one can ask to find only entries for last hour or for last 2 days or even 15 minutes. It is very handy as often this is probably what you need - to identify what have happened recently and to not re-examine all the events happened a long time before.
Let's see how one can monitor BAD ssh logins using logdog. The rest part of this blog will look like a formal documentation, but I hope you won't be frustrated! :)
Installing logdog
First of all we need sparrow and a minimal prerequisites:
I've gotten a bit of grief over the title of a TechBeacon article I recently wrote: Why Perl 6 is the "Game of Thrones" of programming languages. I wrote the article, but the editors chose that title based on a throwaway line a couple of paragraphs in:
Like A Song of Ice and Fire (Game of Thrones), which was started back in 1991 and is still being, ahem, "developed," good things come to those who--well, you know.
To be completely honest, I could have objected and the editors at TechBeacon would have changed it back. However, I didn't object because I was honestly curious what the reaction would be. The general reaction so far has been "great article, awful title." I've no idea if that clickbait title helped draw enough traffic to offset the bad impression of the title itself.
Today is Devel::Cover's 15th anniversary. Version 0.01 was released on 9th
April 2001. Which was a day after Perl 5.6.1 was released. Perl 5.6.1 was the
first Perl version which provided the necessary infrastructure for Devel::Cover
to work.
In commemoration I have released Devel::Cover 1.22, which is the one hundred and
twenty-second release of Devel::Cover.
Over that time there have been 1394 commits from at least 87 authors, though the
first 50 releases were made without version control. In 2004 I started using
svk and later migrated to git.
My thanks to everyone who has been involved with Devel::Cover in any way. I
still consider it one of the best coverage tools available in any language.
I think it is about time I got down to brass tacks and get some code written for this project of mine or at least look at it.
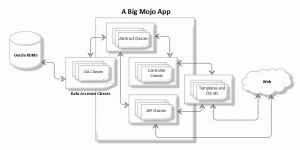
Well they say a picture is worth a thousand words and this little diagram (from a production instance, I too off all the names to save the innocent, will give you an idea of where I have used DA and how I see other using it.
So it sits out in left field as a separate class set that is connecting to Oracle. My app's abstract classes then instantiate these classes to actual work on the DB that is called by the Controller and API classes of the Mojo App.
No I know what some will say;
Why not just use ORM or Fey or some other ORM and skip both of these layers?
[This is a post in my latest long-ass series. You may want to begin at the beginning. I do not promise that the next post in the series will be next week. Just that I will eventually finish it, someday. Unless I get hit by a bus.]
Today’s blog post is brought to you by CPAN Testers. CPAN Testers: testing your code on every version of Perl on every operating system in every possible circumstance ... so you don’t have to.
I’ve talked about CPAN Testers before. If you’ve read that, you probably know how awesome I think they are already. And, with this foray into creating a date module, they’ve stepped up again.
Now, you will imagine that I made sure all my tests passed on my machine before I dared upload Date::Easy to CPAN. But that doesn’t mean they’ll pass on everyone else’s machines, so I watched CPAN Testers with some trepidation. Remember that dates are annoying to get right, and, even though I’m trying to mess with the underlying date code as little as possible, there’s still chances aplenty for things to go tragically wrong. Which is pretty much exactly what happened.
Archive::SevenZip had been laying around on my computer since a long time.
7-Zip has the great advantage of being able to read a plethora of archive
formats, including ISO9660 image files. Its main use is to unzip and sort
incoming downloads on my desktop machine, but I have also used it to extract
files from ISO-rips of CDs and DVDs.
So I guess the best thing for me to do now is answer good old question 4 from my last post.
Is this just going to pollute the name-space?
So as I said in my last post DBIx::DA was the name-space I picked some 10 (or is it 11) years ago for my take on the DataAccessor package, and I would agree it does pollute the name-space as like I said it adds nothing to DBI except, some wrapping and SQL generation.
So where to put it?
Well I was thinking under Data:: as something like Data::Accessor.. but when you look at that name-space a good chunk of the modules in there are for working with Data directly i.e. dump it, change it, sanitize it etc. So I think something that just gets data may not work there.
We're very happy to announce that Strato are supporting the Perl QA Hackathon, as a gold sponsor, for the second consecutive year.
Strato are a global hosting company; they are a subsidiary of Deutsche Telekom, and have their HQ in Berlin. Their ISO 27001-certified data centres are home to four million domains and about 60,000 servers. Strato offer domains, email, homepage and wordpress packages, online storage, web shops and basic servers through to high-end solutions.
Dist::Zilla is an extremely powerful and versatile CPAN authoring tool, which has enabled me to reliably publish many distributions with minimal fuss. It has the ability to automate your entire distribution building, testing, and releasing process, customized to almost any workflow, but this ability does not come without cost. One of the biggest difficulties newcomers face is sorting out the overwhelming number of available plugins and how to use them together effectively. A good way to start is with the tutorials at dzil.org and the standard [@Basic] plugin bundle. Unfortunately, the [@Basic] bundle is out of date; notably, it does not include the [MetaJSON] plugin, to generate META.json which is now the preferred metadata format for CPAN distributions. For backwards compatibility reasons the bundle itself can't easily be updated with new plugins.
nqp-js-on-js (NQP compiled to JavaScript and running on node.js) passes it's test suit (almost, there is a bug with how regexes compiled at runtime capture stuff which I haven't yet figured out).
While nqp-js-on-js compiles parts of rakudo (with a minor bug fix) it turn out for some reason it's unacceptably slow on some of the larger files (like Perl6::World).
As such I have turned my attention to figuring out what's the problem and speeding nqp-js-on-js up.
Hopefully the next blog posts will be more detailed and contain the description of some nifty optimizations.
 We're very happy to announce that
We're very happy to announce that