In the first part I showed some problems and possibilities of the B::C compiler and B::CC optimizing compiler with an example which was very bad to optimize, and promised for the next day an improvement with "stack smashing", avoiding copy overhead between the compiler stacks and global perl data.
The next days I went to Austin to meet with the perl11.org group, which has as one of the goals an optimizing compiler for perl5, and to replace all three main parts of perl: the parser, the compiler/optimizer and the vm (the runtime) at will. You can do most of it already, esp. replace the runloop, but the 3 parts are too intermingled and undocumented.
So I discussed the "stack smashing" problem with Will and my idea on the solution.
1. The "stack smashing" problem
B::CC keeps two internal stacks to be able to optimize arithmetic and boolean operations on numbers, int IV and double NV.
Berlin.pm is glad to announce that the 15th German Perl Workshop is going to happen in Berlin from March 13th to 15th 2013.
Thanks also to the people of Frankfurt.pm who support us in organizing. More details will follow.
Data::Dumper version 2.136 was just uploaded to CPAN. It's been over a year since the latest stable release of the module. Generally, I just synchronize changes to the module from the Perl core to CPAN releases and do so very carefully with lots of development releases.
Recently, however, there was a reason to look at Data::Dumper performance critically. A very simple change meant a speed-up of the order of 50% on my test data set. In a nutshell, Data::Dumper used to track each and every value in the data structure just in case you were going to want to use the Seen functionality. That pertains to a tiny fraction of all Data::Dumper uses and everybody was having to pay for it. For example, if you're using the functional interface (like most), then you wouldn't even ever get access to that information, yet everything was being tracked instead of just things with high reference counts.
LinkedIn recently changed its endorsements so that you can target specific skills in your connections. I was presented with some prompts that I found amusing, as if the entire universe already knew this:
Of course, LinkedIn is a trust network. Things like these endorsements, or the CPAN Developers Group and the Advanced Perl Users Group, let someone outside the Perl universe know one person inside then discover trustable people they don't know. With so many companies looking hard to find good Perl programmers, your endorsement might be able to help a friend who's a good programmer but not highly discoverable.
I was amused at a few other possible endorsements. Does Randal Schwartz know Perl?
Is Damian Conway good at public speaking? I can endorse him, although they don't have a button for "Everyone else should just give up":
Right after I finished my LinkedIn tasks, I watched Rachel Botsman's "The Currency of the New Economy is Trust" TED Talk, which just happened to be next in my podcast feed. She mentions Stackoverflow:
My name is Kevin Carillo. I am a PhD student currently living in Wellington (New Zealand) and I am doing some research on Free/Open Source Software communities.
If you have joined the Perl community within the last 2 years, I would like to kindly request your help. I am interested in hearing from people who are either technical or non-technical contributors, and who have had either positive or negative newcomer experiences.
The purpose of the research is to work out how newcomers to a FOSS community become valued sustainable contributors.
You can complete the survey via my university's survey platform. For more detail on the project aims, see below.
What is the project about?
I am basically studying how the experience of a FOSS community newcomer has an influence on this person’s actions and project contributions in the community.
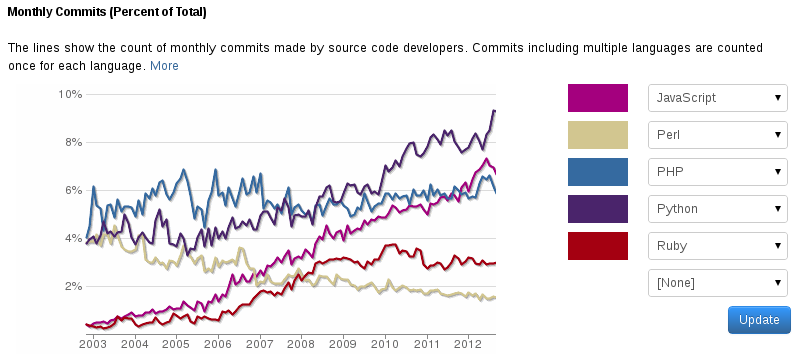
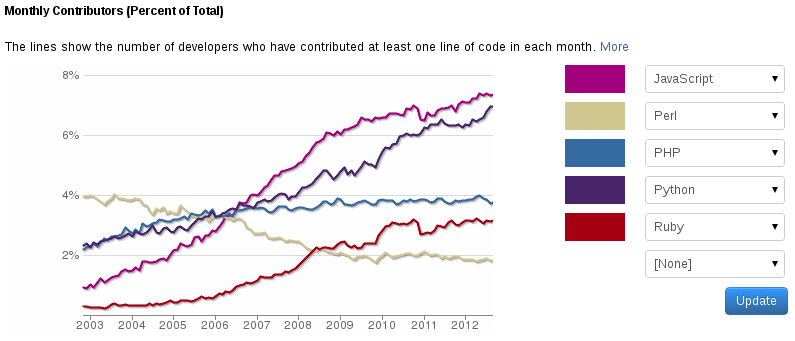
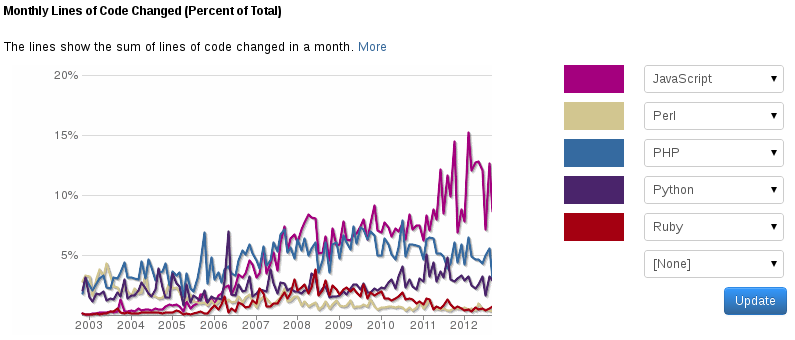
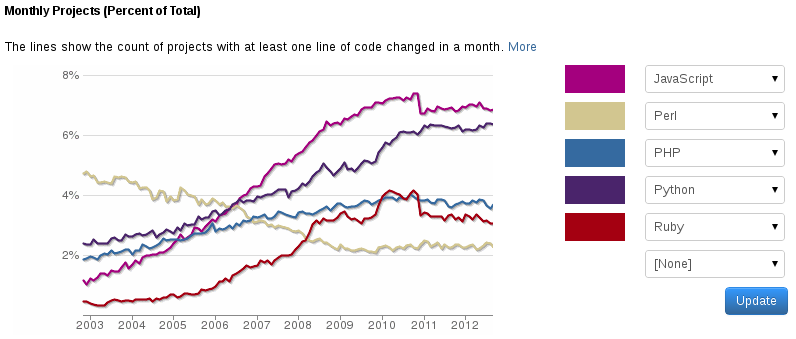
I'm thinking no. Yes, Perl hasn't gained market share. It tends to stabilize these last three years, see especially if you see the contributors graph. But Perl was way too popular back then anyway, due to lack of alternatives for web languages (which is bad, in some ways). Come to think of it, there should be a lot more PHP and JavaScript developers than Perl developers, right?
I am, somewhat famously, one of the last holdouts in the Perl community when it comes to moving away from svn to git.
I fought against the most for a long time, on the basis that the tool support for git on Windows was just terrible and it would make contributing to Perl difficult for Windows people.
Fortunately, with the availability of tools like SmartGit and GitHub for Windows this is no longer a problem.
So it looks like the time has for me to start the giant job of moving my repository over to GitHub myself (no small task considering it contains something like 300 modules).
As a first step, I am porting my personal release automation over to allow me to release modules from GitHub directly without the need for git client integration or a checkout at all.
The core of this new release automation is my new GitHub::Extract module.
The actual intention behind perlybook.org was to make module documentation from CPAN more portable. Ebook-Readers today are designed for reading-pleasure everywhere - in your garden at daylight or in your bed at night... and this works so far.
But recently I noticed an effect which could also be of interest for "normal" Perl programmers who just work at a the computer and also prefer reading the docs there.
I always found it a bit complicated to read documentation on CPAN. If the author does not give a lot of love to the documentation it's even complicate to browse through all the docs of each module, since there is no auto-generated TOC over the complete distribution (only on inside each modules doc).
But there are even more issues.
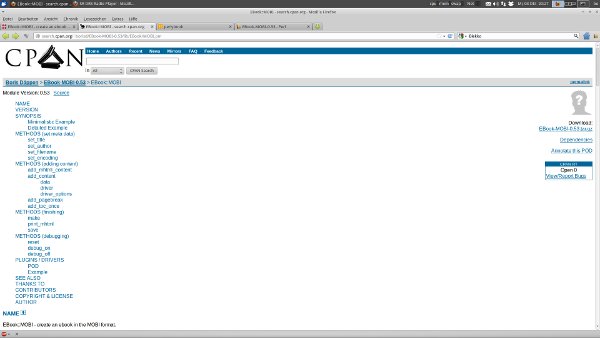
See how the documentation of EBook::MOBI looks like on my screen (1920x1080):
This is what you see first. It is a horrible layout, isn't it? You have so much unused space and the TOC is so big that you don't see what you are probably most interested in... a small description and the example in the SYNOPSIS.
Hi All
How i can access a website with the help of Perl
- I am able to open the website and can enter the username and password and then log in into it
- After loginned i have to select a value from a drop down box(How Can i do that?)
So, like my entry on YAPC::Asia Tokyo 2011 last year, I thought I'd give you guys a very brief tour of what it was like this year. Before I start, you can find the full set of photos here, and videos will be uploaded here.
Find my signature in the Google NY office, tell me where it is (you're not supposed to take pictures), and I'll send you a set of my books. It's not hidden, but it's not out of place either.
You don't have to work for Google to make good on this. The same technical sourced that gave me the tour can do the same for you. Ask for for the referral and I'll tell you who you have to talk to. If you were at dinner with me and NY.pm at Wildwood, you've already met him.
Google isn't known as a big Perl user, but Google isn't really looking for skills, unlike most companies I visit. They want people who know how things work, and everything after that is just tools.
Maybe I should send Google a set of books too. In there several walls of tech books, they have the right Perl titles, just in older editions.
Please note: the following was done as an exercise in intellectual curiosity and not in any way an example of a real optimization. Any comments about "premature optimization" will be downvoted as soon as we get a voting system ;)
We're deep in the heart of micro-optimizing some extremely performance-intensive code when I stumbled across this:
if ( $number == -1 ) {
# do something
}
Clearly a numeric comparison isn't expensive and I managed to find a few areas where we could improve some performance, but out of curiosity, I decided to benchmark $number == -1. The -1 is returned if a function failed (because throwing an exception would be far too expensive here) and we test for that. In reality, we only care if the number is less than 0. I was mildly curious to know if I could get a tiny performance increase in bit comparison (again, this was curiosity only. If I have to get this deep in optimization, I have more serious issues than this).
Welcome to Perl 5 Porters Weekly, a summary of the email traffic on the
perl5-porters email list. Normally, I'd have a dusty thread and some
"witty" banter here, but I'm just running too far behind for that this week.
Topics this week include:
Perl 5.17.4 is now available
Parrot 4.8.0 "Spix's Macaw" Released!
WANTED: "whole program" benchmarks
Changing the Perl error message when a module is not found
The time has made its 2% and brought us one week closer to the YAPC::Europe 2013 in Kiev!
This time our main news is that we are also closer to the point when we are able to fix and announce the dates of the conference. This week we explored a couple more venues, and there are only two left in our list.
Interestingly, we found a venue we did not met before, and it is the venue that a Python Pycon conference is exploiting in October. So far, there're President Hotel and European University that we will see in the following days. And then -- we select the venue based on different metrics :-)
I'm trying to get Plync to work with my Nexus 7, mainly because I want non-Google calendar synchronization between my mobile, my desktop and this shiny toy. Authentication works, but the Nexus 7 does not want to list the available folders at all and does not attempt to synchronize the Calendar folder.
To further debug this, having a good+free (or at least, available) ActiveSync server that I could use to debug the network traffic against would be very convenient. $work does not use ActiveSync, so it won't be much use there...