So, in addition to Lausanne, Aarhus, and London, I am now also going to be visiting Stockholm in the next month.
Just two weeks ago, Claes Jakobsson and the wonderful folks at Init AB got in touch and invited me to come and speak at the Nordic Perl Workshop on Sunday October 14, and then to run two public Perl training classes on the following Monday and Tuesday.
I am extremely excited to be able to add these events to my schedule as I have never before been to Sweden, nor to an NPW. At the Workshop I'm going to talk about (and demo) my new Regexp::Debugger module...including some brand new and hitherto unreleased features.
If you're going to be in or near Stockholm in the middle of next month and would like to take part in any of these events, you can find out about the Nordic Perl Workshop from the yapc.eu website, and sign up for the training classes on Init's course page.
When creating an article for blogs.perl.org, place only one or two paragraphs in the BODY section. This is the lead (pronounced "leed") to the article. Place the bulk of the article in the EXTENDED section.
The design for parrot, the vm (virtual machine) under rakudo (perl6),
envisioned a platform and version compatible, fast, binary format for
scripts and modules. Something perl5 was missing. Well, .pbc and .pmc
from ByteLoader serves this purpose,
but since it uses source filters it is not that fast.
Having a binary and platform independent compiled format can skip the
parsing compiling and optimizing steps each time a script or module is
loaded.
Version compatiblity was broken with the 1.0 parrot release, that's why
I left the project in protest a few years ago. Platform compatibility
is still a goal but seriously broken, because the tests were
disabled, and nobody cared.
There is a little bit of overlap here with the first blog on Devel::Trepan. I apologize for that, but I don’t see how this can be avoided. The focus here though is more on the existing Perl debugger rather than Devel::Trepan which is given as one concrete example from which to draw lessons from.
A number of people, myself included, have talked about modernizing or replacing the venerable Perl debugger, perl5db.pl. Here I’d like to suggest a plan of action.
First the situation. It is in many ways similar to the challenges faced say in going from Perl5 to Perl6 — and in other languages Ruby 1.8 to 1.9 or Python 2.7 to Python 3K. What is there is:
We are now offering free Perl Dancer hosting at http://1.ai we offer free hosting 512 MB of space + 512 MySQL database both in solid state drives. This is a totally free service with no paid plans or ads. You can see some sample hosted apps at here and here
Please mention this blog post in your hosting application to speed up the approval process!
The editor is our most closest tool we spent most time with, any discussion will spark highly emotional reaction. But because it has to be the cosy seat to our personality I started Kephra.
Lets be honest most people I know see it like my little pet project ("good you allowed to upload to CPAN" but i will use vim/emacs/.. anyway), some like it enthusiastically but that's it mostly. But Kephra is not about to have a Editor written in Perl - Perl is just IMO the best tool for the job. It's not about certain features like nice integration of your favorite Perl tools, not even the TIMTOWTDI interface (having the best of vi, emacs, jedit, komodo, notepad in one place). My deepest satisfaction is to think things through and offer solution that go beyond mostly known and are deeply satisfactory (which is the Perl 6 approach of things too).
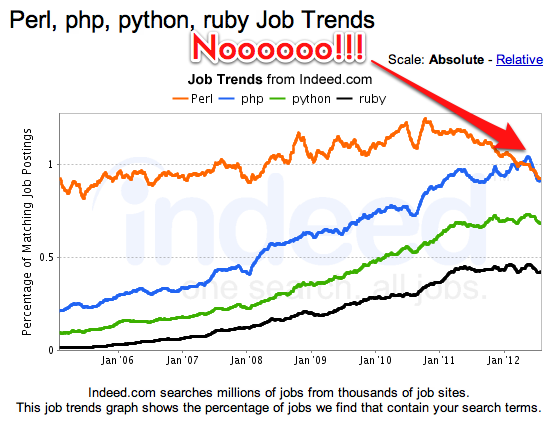
Every once in a while I check out indeed.com to see how Perl is doing vs. other languages like PHP, Python and Ruby in the job market. There's a worrysome trend lately - I'll let the graph speak for itself.
It's been some time since the last update on the progress.
A few weeks ago we set the new dates which is the weekend of 13th and 14th of October.
Stockholm is usually quite beautiful during early october and if weather permits I'm hoping that we can arrange a relaxing trip out to the archipelago before or after the workshop.
I'm happy that Damian Conway will be visiting the workshop this year to talk about regex debugging and will also provide training the days following the workshop thru our sponsor Init AB. Other speakers that are accepted so far are Jonas Nielsen who will present how to run Perl on Stackato and Ulrich Wisser on perlcritic.
But to make this workshop as good as NPW usually is we need you to attend and preferably also give a presentation.
We have a web developer position open in Helsinki, Finland. As I'm personally involved with this recruitment, and Perl can be the main tool in this job, I think it's ok to be posted on this forum. Read the full advertisement at our site, or below.
It's been a while since I've posted anything about Perl.
It's been a while since I've written much Perl as well, looking at my CPAN page shows a long gap since I moved over to America (and the Microsoft stack) to work at Kaggle.
The break has caused quite a few problems in terms of maintainership of various things. Padre's progress towards 1.00 has suffered quite a bit, and I've handed off a few modules where people showed interest in taking them over.
The time away from Perl has also given me a chance to reassess my work and the CPAN ecosystem and to think about which parts of it are actually important and which are in desperate need of a shake up.
The first project that badly needs some love is CPANDB, which is a single relatively small SQLite database (and ORM) layer that aggregates all the most important data about CPAN authors, distributions and modules together in one place.
This review is the conclusion of 2 rewrites. Today I'm still uncertain
about a final opinion about this course.
Definitely, the video series is a course. And it does hook up onto the
"Mastering Git" video series from the same authors. Content is rich,
very rich. Most of day to day Git users will probably learn a lot on
this marvelous tool that is Git.
But, Git is a tool. Basically a developer (or whatever user of text
files which can make use of a revision control system) knows one or
more languages, and tries to extend that knowledge as far can be. The
Git tool serves him in solving bugs (by i.e. finding diffs which
introduced them), keeping track of released versions, etc. There's a
lot Git can do beyond this, and the course covers lots of these. But
is that knowledge required?
After a wonderful vacation, I came back to discover that I had far more work to do than I had realized. I have only just started to claw out of the heap and arrive at a place where I have had some time for Perl-ing.
First of all I need to apologize. I missed my Grant Report this month. While this is no excuse, there also was nothing to report. I do hope to keep honing in on the few remaining problems that Alien::Base has developed, but I am increasingly believing that a few of my initial assumptions may have been too flawed, possibly requiring a little bit of rewrite. That said, what I really need is someone who has a longer beard than I (metaphorically) to help me understand some Makefile/linking stuff to help me over the hump.
Perl modules are not like dynamically loaded libraries in other programming languages. Thanks to the import function, sub prototypes, symbol table hacking, parser hooks, magic like Devel-Declare, ties and other voodoo, Perl modules can shape and craft the flavour of Perl that is available to their caller. A practical example: Perl's exception handling via eval and $@ is weird, clunky and error-prone. But by loading TryCatch or Try::Tiny you get a clean syntax for catching exceptions that Just Works. You're not just loading a library and using it at arm's length; you're changing the very syntax of Perl - locally, within your module.
(Aside: there are of course plenty of modules that don't do any of this - say those that are designed to be used in an object-oriented fashion. Those are great too of course - different approaches are appropriate for solving different problems.)
In order to override the C compiler with ExtUtils::MakeMaker, one can
do something like:
perl Makefile.PL CC=/usr/bin/clang
Which will make the "CC" variable in the generated makefile be set to
/usr/bin/clang instead of the default. Apparently, setting the
CC environment variable does not work like it does with CMake.
Welcome to Perl 5 Porters Weekly, a summary of the email traffic on the
perl5-porters email list. The smartmatch discussion continues to be very
popular, so its summary will go at the end of this post. There was also a
very long, very tedious thread about how Perl ought to handle UTF-8 output
which almost demonstrated [Godwin's Law] [1] (the longer a thread continues,
the higher the liklihood someone will call someone else a Nazi.)
If you're reading this on my blog or somewhere else on the web, you
can now find the summaries in Markdown format in [this github repository] [2].
Also, since there seems to be influx of new readers, ohai! I started writing
these summaries after YAPC::NA 2012 after having a breakfast conversation with
Gabor Szabo. If you don't already read his Perl Weekly email newsletter,
you really ought to sign up for it.
Topics this week include:
Term::ReadLine::Perl not moving forward
DTrace probes for loading-file, loaded-file, op-entry
My Perl Foundation Grant for Improving the Perl Debugger Was Accepted
MTMH 2012 was a joint hackathon between the people working on p5-mop (a project to get a Moose-lite metaobject system into the Perl 5 core) and the Perl RDF toolkit, with a few Rakudo people thrown in too, ostensibly for convergence between the p5-mop and Perl 6 metaobject systems when possible. As somebody in the RDF camp, though with a toe in the Moose water, I decided to get a better feel for Moose by playing around with a few MooseX projects. (The results include MooseX-DeclareX and MooseX-Interface.) There's really a lot of cool stuff behind $self->meta. If you've never gone behind has, extends and with when using Moose, you really should.