Joel Berger will give a talk at YAPC::NA 2012 described as:
Many scientists use Fortran for their numeric modeling. Some of my fellow Ph.D. candidates have done all of their work in Mathematica. Closer to home, L<PDL> provides Perl with some really nice numerical array handling power. Still, all of these tools left me looking for something higher level.
In this talk I will present some of the modeling paradigms I have been using in my research. These simulations model physical systems as Perl objects (rapid designing of classes via L<MooseX::Declare>). Dynamics are closures which genereated by some objects and influence others. Using this paradigm, simulations are written quickly and are tremendously flexible and extensible.
For the majority of the talk, I will use a Perl-level fixed time-step differential equations solver. At the end, I will introduce (ever so briefly) my L<Math::GSLx::ODEIV2> module, which I use to solve systems of differential equations which are made of closures over these object/closure systems.
I hope this talk will show that high-level languages can be used to model physical systems and make it feel very natural to the Perl programmer.
There's a discussion on Perl-QA about whether the use of use_ok should be discouraged. I argue that it should be. It really doesn't gain us much, it's historically been buggy, and simply using the module is enough to cause a test failure if the module doesn't compile. So someone asked how to write this t/00-load.t if we didn't have use_ok:
At YAPC::EU 2012 Matt S Trout will tell you something about the "State of the Velociraptor":
"What shall we do tonight, mst?"
"Same thing we do every night: Try to conquer the world"
As usual, mst presents a madcap recap of the last year in the perl5 community combined with some thoughts on how both madness and method can inform our approach to our language, community and culture over the next year.
We accept sponsorships in increments of 50,000JPY. For our sponsors, we offer to publicize your logo on our pamphlets, and on our site, as well as a dedicated entry for you under our site (example).
If you have swag to give away, we are happy to distribute them at the venue, along with any advertising material (pamphlets or the like). If you are sending someone over to promote, we are happy to arrange something. Please contact us for details at info-at-perlassociation.org.
Ingy döt Net will give a talk at YAPC::NA 2012 described as:
Acmeism is trying to hack in several programming langugaes at once. Come learn you an Acmeism for great good.
In this talk Ingy döt Net will talk about a module that he has released and maintains in over 6 programming languages. He will talk about his primary acmeist tools: C’Dent, Pegex, TestML and Stardoc, and how they helped him in the process.
If you try running Cygwin from another program (say, the Ponderosa tabbed terminal emulator) and you get a "missing cygwin1.dll" error, you should check that you have put Cygwin into your Windows PATH environment variable. Cygwin does not do this by default.
On my last entry,
I told you that I have had an idea for a Perl-related April Fools' day gag,
and that I would possibly reveal it on 2-April with a big disclaimer
on top, just for kicks. Well, it's already 9-April, but I guess it is better
late than never, right?
OK, here is the big disclaimer: THIS IS A JOKE. IT'S NOT SERIOUS. SO
RELAX - IT IS NOT GOING TO HAPPEN SOON (AND HOPEFULLY WILL NOT EVER
HAPPEN)..
Bruce Gray will give a talk at YAPC::NA 2012 described as:
Why do you use “my” instead of “our”? When should you use “our”? Why not “use vars”?
Why does `use strict` catch “$typo”, but not “$Data::Dumper::typo”?
Why do *you* need to care about namespaces? And what are they really?
Why does your module name need to agree with your “package” statement? What happens if it doesn’t?
Most of the answers are easy to learn, but much harder to remember, so many Perl programmers end up doing the right thing only through repeated references to examples and docs.
The answers become both clear *and* memorable in this talk, via a rapid walk through the history of Perl.
As we skim the timeline of key language elements, you will see the problems they were needed to solve, and understand where and how they should be used.
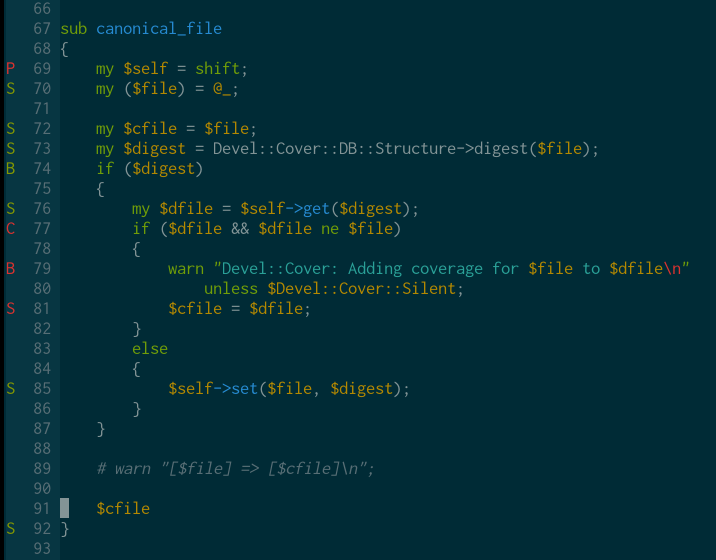
At last week's QA Hackathon in Paris I put together a Vim report for Devel::Cover to show coverage information as Vim signs. See https://blogs.perl.org/users/paul_johnson/2012/03/vim-report-for-develcover-perl-qa-hackathon.html
Whilst nice, and somewhat useful, this was very much a proof of concept. It only worked for statement coverage, it wasn't particularly clever, nor was it particularly pretty.
I've just released Devel::Cover version 0.86 which solves a number of these problems. It shows all types of coverage data (that Devel::Cover knows about), it seems to be pretty usable (at least in the way I use vim), and it provides a way to customise it to make it pretty (I'm fairly happy with the way mine looks).
In this image you can see some of the features. The column on the left-hand side shows the coverage information. Five coverage criteria are displayed as:
P - Pod coverage
S - Statement coverage
R - Subroutine coverage
B - Branch coverage
C - Condition coverage
R Geoffrey Avery will give a talk at YAPC::Europe 2012 described as
When attempting to learn Dancer I ran into the problem that all the documentation started from "Here is a 'Hello World' script". But that was assuming many things were set up and configured and that just was not true, at least not on my server.
I wasn't looking forward to dealing with this XML feed because I hate anything that deals with XML. However, with Mojo's DOM stuff, I don't even have to know it's XML. Here's the interesting bits from a program that's not much larger than this snippet:
use Mojo::UserAgent;
my $ua = Mojo::UserAgent->new;
my $response = $ua->get( $feed_address )->res;
my @links = $response->
dom( 'item' )->
grep( sub { $_->children( 'title' ) !~ /.../ } )->
map( sub {
$_->
children('guid')->
map( sub { $_->text } )
} )->
each
;
One week ago, I happily had the opportunity to be at the QA Hackathon in Paris. In the past I had been vaguely aware that the hackathon exists and I had some shadowy idea of what goes on at such a thing, but I just never considered getting involved. I didn't think it was very much related to the sorts of things I work on. Happily, it turns out that I was wrong.
So March ended on quite a high, following the 2012 QA Hackathon. With so many key people in one room, it was impressive to see how much got done. You can read reports from myself (parts 1 & 2), David Golden, Ricardo Signes, Miyagawa, Paul Johnson, Ovid and Dominique Dumont, and there were several tweets too, during and after the event, and the wiki also has a Results page. There was a significant number of uploads to PAUSE during and after the event too. And CPAN Testers has benefited hugely from the event.
So I did a search for Yet Another Society today and the first hit is http://www.yetanother.org. (No real surprise there.) I click the link and (surprise!) am greeted by a page that was last updated in 2003 and every link that doesn't point to static content is broken.
Who maintains http://www.yetanother.org these days? I emailed kevinm@yetanother.org (the only email address found) but it bounced.
At a minimum, it should redirect to http://www.perlfoundation.org. Ideally some of the original content would remain that explains the relationship between Yet Another Society and The Perl Foundation as well as relevant links to other parts of the Perl community.
Brenno de Oliveira will give a talk at YAPC::NA 2012 described as:
Data::Printer is a simple and powerful solution to viewing your complex Perl data structures.
Contrary to Data::Dumper and similars which stringify your data in a restrictive way so it can be eval’d back into your code, Data::Printer cares only about letting you easily see what’s in there using colors, filters, a lot of customization and no hassle.
In this talk I’ll showcase Data::Printer and walk through some of its main usage scenarios, customization, filters, and general tips for you to tame your variables!
There's a discussion on Perl-QA about whether the use of use_ok should be discouraged. I argue that it should be. It really doesn't gain us much, it's historically been buggy, and simply using the module is enough to cause a test failure if the module doesn't compile. So someone asked how to write this t/00-load.t if we didn't have use_ok:
Testing is hard - not necessarily to do, but to start with - it is so hard, that yet I haven't started writing tests for my code and I considered this to be a handicap for me as a developer.
I've heard about this Behavior Driven Development stuff ( BDD ) and I said to give it a try.
After some research to see what is available for Perl, I found Pete Sergeant's Test::BDD::Cucumber module and although it's only at version 0.05, it is usable and functional.
Comming back to BDD, the main idea behind it is that your user stories are your tests. As an implication, you could get to the stage where your business analysts write your tests (with little, or even no developer intervention).
Ulrich Wisser will give a talk at YAPC::Europe 2012 described as
Perl::Critic can and should be used to greatly improve the quality of any Perl code. The only disadvantage of Perl::Critic is that it provides no history. I will show how .SE (the Swedish country code top level domain registry) uses Perl::Critic to improve code quality and how we mitigated Perl::Critic's disadvantage.
Bonus: How to convince management to fund a Perl::Critic evaluation and improvement of your codebase.