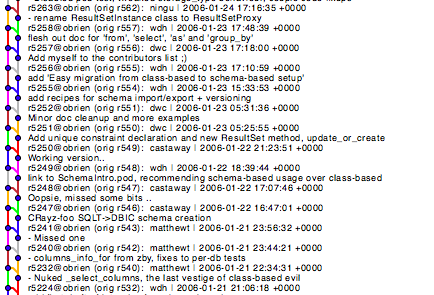
After the previous steps, the git repository has an accurate history of what was done to the SVN repository. It is a direct translation though, and shows more the process and tools that were used, rather than developer intent. I proceeded to simplify how the merges were recorded to eliminate the convoluted mess that existed and make the history usable.
Two main classes of these problems existed. There were branches were merged one commit at a time, as that was one way of preserving the history in SVN. The other case was trunk being merged into a branch, and immediately merging that back into trunk. Some other issues match up with those two merge styles and the same cleanup will apply to them.
Here is a section of the history of the 'DBIx-Class-resultset' branch being merged, one commit at a time. Obviously not ideal, but you can mostly tell what is happening.
"You can get fired for not knowing Perl" I'm still sad that I had to miss the Nordic Perl Workshop in Reykjavík, but I'm going through talks that they've linked on their @nordicperl2010 Twitter feed. I like Tryggvi Björgvinsson's mutation testing talk, especially since he tells how he got a lecturer fired for not knowing Perl. I wish I was there to see if, but I only get to see the slides.
He points out an important but often ignored part of Perl's testing culture: we let the foxes guard the henhouse. That is, the code author and test author are often the same person. Not only that, but CPAN Testers runs the tests that the author provides. Tryggvi asks "Who watches the watchers" (with plenty of appropriate artwork).
How can we suss out problems with tests? One idea is to mutate the source code to see if the tests fail. For instance, we might change a comparison operator. The original code might test for greater than:
One of my client's schemas contains a table which contains a column named 'can'. In his context this is a convenient abbreviation for 'Client Access Number'. In Perl however, ->can() is already spoken for. Since DBIx::Class::Schema::Loader creates an accessor method for each column of each table in your database, things went sideways on me today when I tried to auto-generate classes for all tables in that database.
Luckily irc.perl.org #dbix-class came to the rescue again, and Caelum was quick to patch the bug. So if you have clients like mine, rest assured the next push to CPAN will cure what ails ya. :)
One of my little obsessions is attempting to figure out a way to create a money-spinner (also known as a cash cow) by predicting the outcome of football matches (also known as soccer matches to those in North America). I did some research and I found that there is a frequentist (I don’t want to get into the argument of Bayesian vs Frequentist approaches to Statistics) method for doing this. Most of the research is from econometrics and has to do with predicting crowd sizes rather than actual outcomes of matches.
I’ve been thinking, why is it that Character strings, and Binary strings are mostly the same in Perl. If you read in a binary file, why would you want it to behave as if it were a Character file?
The main difference currently, is that Unicode Character strings have the utf8 bit set. There isn’t really any difference between ASCII Character strings, and Data strings. It also presents a challenge if you want to read in Data strings that have Character strings in them, especially if the encoding of the Character strings is anything other than UTF8.
There are some historical reasons for this conflagration, Perl was originally designed to work with ASCII Character strings. Since there was almost no difference between the 8 bit ASCII, and 8 bit data; there wasn’t any real need to separate the two. Unfortunately the world (of programming) is no longer this simple, Perl needed to change to handle Character data that wouldn’t fit in a single 8-bit byte.
We will cover a range of topics from understanding Dancer, writing your own Dancer applications (tutorials included!) and writing a plugin or engine backend to Dancer.
The work on the articles already benefited applications and modules. If you follow the articles, you'll be able to understand how they were all written, in complete detail.
You don't write Perl 6 documentation like a story. Not only i can't make it up freely but its also almost impossible to know all details in that time. So you write about the bits you are shure you know. Thatswhy i also layed out the structure for the tablets 4-6, even if there is almost no content. This way I sort the thought in my head and can link to proper spots now. The magnitude of links is a serious part of the work but it will make it much more usefull.
You know, when I look at Russian Cyrillic, or Greek letters, it looks like squiggles. I've never studied it, so I have no means to relate it to sounds, let alone meanings.
So, when people say, "I can't read Perl", it only tells me they haven't studied it.
And if people choose to be vocal about their own ignorance, saying "Perl is unreadable!", that's saying a lot more about them than it does about Perl.
As far as I can tell, millions of people speak Greek and Russian. I'm not one of them, and that's ok. I don't keep saying "Russian is impossible", simply because I personally don't know it.
If it matters, I've seen some pretty impenetrable Python, Ruby, and Java code. And I even pretend to know those languages at least in passing.
I presented OOP approach for solving workflow tasks in my previous post.
Now I'd like to show you, how to deal with workflows in a slight different manner.
I'm gonna write about Workflow lbrary from CPAN. And I'm going to present you some kind of a tutorial on how to use this lib, and what features does it have.
The main idea of Workflow lib is configuration over coding. Flow is described in XML files, of course 'some' coding is still required.
So let's implement our request management using workflow lib.
First of all, we'll create application, with all that simplifications, that we had in previous post, and than enhance it to real world web application and add some complex and interesting features that workflow lib can offer.
I have a minicpan on my laptop in my home directory. My home directory gets included in my backups. This means that by looking at my old backups, I can get a good idea of how much the CPAN changes ...
daily.0 is my most recent backup, and monthly.0 through to monthly.5 are backups from 1 month ago up to 6 months ago. We can see that the rate of change on the CPAN is fairly constant. It's also surprisingly high, with almost 10% of the "active" part of the CPAN (that is, the bits that you can trivially access by typing "cpan Some::Module" to install, changing every month.
Yes, I realise that this is a gross simplification.
In my last post I mentioned my attempt to provide syntax highlighting for the Perl debugger. It works and I think it's useful, but I did that by hacking directly on the debugger. Every version of Perl gets a slightly newer version of perl5db.pl (the debugger) shipped with it and hacking on a particular version doesn't help¹. Thus, I need to write a separate module which encapsulates my hack and (relatively) cleanly alters how the debugger operates.
I could do something stupid like try to override print or something like that, but it's fragile. Instead, I only want to highlight Perl code and I can do that by only highlighting the code in @DB::dbline. That's because if you know the debugger, you know this little tidbit:
The array @{$main::{'_<'.$filename}} (aliased locally to @dbline via glob assignment) contains the text from $filename, with each element corresponding to a single line of $filename.
At this point, you may be wondering "what the hell is $main::{'_<'.$filename}?" Basically, the *::main{"_<$filename"} typeglob contains a lot of special information useful for the debugger. The array, scalar and hash slots are where the debugger has a lot of magic. Regrettably, this magic typeglob comes straight from the Perl internals and because of this, I have a problem.
Let's make some code.
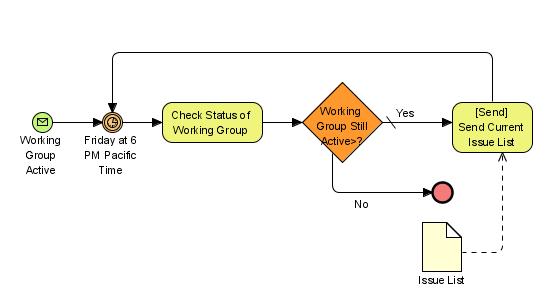
(Check my previous post for flow chart).
Let's use quite simple straightforward approach, and then modify it with some design patterns.
General idea:
We will have simple request object. (We wouldn't care how it's populated with data, let's assume that we have some collection object, that gathers requests from database and creates objects). Request will have following properties: id, description, state. We must be able to change states and perform some actions during that state changes.
I have recently tried to streamline my daily assignments in a task list, so I'll have track of stuff I do, or need to do. However, the way I work, I often find that a simple list does not suffice.
I would like a second level todo list that will collect several tasks that need to be accomplished before I can mark an item completed. Most of these are common for each job, but some are not. For instance, I want to tick off "merge from master before pushing" for every task, but "write POD" might not apply for pure-GUI (Template::Toolkit, HTML and JavaScript) jobs. Naturally, I want those to be available every time I add a task, and selecting from those should be as simple as possible.
Sadly, I found that, for all the plethora of solutions available, none gives me what I actually need.
This is not a perl blog post... Unfortunately I have not posted for a good while, and theres going to be a further gap before I start again properly.
So, following a week of holiday, a week on an intensive training course, a week running a theatre show and two weeks organising things for pantomime; I am about to start 2 weeks of pantomime stage management.
So basically I am not going to do much more in terms of blogging until late December.
I'd like to start series of posts related to workflow, workflow management systems and of course Perl. Workflows seems to be quite “hot” topic in all that world of enterprise software for the last ~5 years.
First, let's figure out what workflow is, why we should care and how Perl can deal with it.
What is workflow?
A workflow is just a bunch of states with rules on how to move between them. These are known as transitions and are triggered by some sort of event. A state is just a description of object properties.
A workflow application is a software application which automates, at least to some degree, a process or processes. The processes are usually business-related, but it may be any process that requires a series of steps that can be automated via software. Some steps of the process may require human intervention, such as an approval or the development of custom text, but functions that can be automated should be handled by the application.
The final report for the Perl Survey is now available, after many delays. The report is fairly bare bones, but it should be sufficient for you to get a handle on the structure of the Perl community (or at least the sample who responded to the survey). I've gone for the approach that I'm presenting salient findings, rather than overwhelming you with detail.
There is a lot of data summarised in this report, and rather than producing a long turgid document with every possible analysis that I can think of, I thought that the better way to approach things would be to make a fairly short summary report so that people can ask questions, or request any additional information via the comments here, by email, or by grabbing me (kd) on irc.perl.org.
There's a thread on the Israeli Perl mailing list regarding "What don't you like in Perl". There are the usual answers (Perl thread model is a disaster, Perl OO model does not go well with scotch etc.), but the real answer is only revealed on another thread, where a guy who made the unfortunate mistake of replying personally is getting berated for three or four paragraphs, before is also accused of "Top-posting".
Now, for the record, netiquette was invented by a bunch of nerdy snobs who really wanted something to use when explaining why others are not worthy of their time. The less people obey them, the faster we can get to a point where corporations are willing to listen to what "geeks" have to offer, since every time an "Enterprise" guy is looking in a Perl mailing list, all they see are bunch of petty "you do not follow rule 23 of how I want the world to act".
It's also hard to explain the benefit of the "Unix culture" to anyone who just was told to "RTFM means read the FUCKING manual, FUCKER" on #DBIx-Class. It's even harder when said someone is the owner of the leading Perl/Catalyst company.
OTOH, DHH is also known to be an F-bomb terrorist so maybe it's a prerequisite or something.