I spent a few hours this last weekend trying out MongoDB, and its Perl driver.
I was curious to see how I could put NoSQL databases to good programming use. MongoDB stroke me as a good contender for some experiments: it's easy to install, well documented and has an intuitive query language that reminds me of SQL::Abstract syntax. Besides, MongoDB allegedly is very fast and scalable, which left me wondering how my configuration management apps could benefit from a backend switch from relational to a non-ACID document based DB like MongoDB, just like these people did for their server monitoring software.
I added a Perl backend version of the SproutCore tutorial to the wiki. It was useful to see how Tatsumaki (the new framework by Tatsushiko Miyagawa) worked, and also because PSGI is quite fun to use!
Thanks to the CPAN testers, I have found out that there is an exciting bug in version.pm. Somewhere in between versions 0.74 and 0.82, qv()'s behaviour changed, and so my CPAN::ParseDistribution started failing two of its tests.
There's no reason to ever use version.pm, which only exists to support the absurd practice of using things other than number as version numbers. Use of version.pm makes tools for dealing with the CPAN an order of magnitude more complex.
Ovid posted an interesting question about how to sort threads in a forum so you'll get the posts that belong to each thread before the next thread starts. Perl part here.
The question is,
Can I do that in straight SQL (this is PostgreSQL 8.4) or should additional information be added to this table?
As a matter of fact, in PostgreSQL 8.4 you can do it in straight SQL with no further information necessary. I will show how.
To set up the example we'll need a table:
CREATE TABLE nodes (
id int PRIMARY KEY,
parent int REFERENCES nodes(id)
);
Everytime I browse through CPAN recent uploads, and see versions of modules with RJBS's automatic numbering scheme, like 2.100920 or 1.091200 I tend to read it as 2.(noise) and 1.(more noise).
The problem is that it doesn't look like a date at all (is there any country or region using day of year in their date??). I've never been bothered enough with this though, as I don't use this scheme myself, but have always had a suspicion that this obfuscation is deliberate for some deep reason.
Turns out that it's just a matter of space saving and floating point issue. I'm not convinced though, is x.100513n (YYMMDD, 6 digits + 1 digit serial = 7 digits) really that much longer than x.10133n (YYDDD, 5 digits + 1 digit serial = 6 digits)? Is there a modern platform where Perl's numbers are represented with 32-bit single precision floating point (only 7 decimal digit precision) where it will present a problem when n becomes 2 digit using YYMMDD scheme?
Back In January, I reported how Microsoft had launched what amounted to a denial of service attack on the CPAN Testers server. It seems that 4 months later, we have yet again been targeted for attack from Microsoft. After the last attack, any IP address matching '65.55.*.*', hitting the main CPAN Testers website, was blocked (returning a 403 code). Every few weeks I check to see whether Microsoft have actually learnt and calmed down their attack on the server. So far, disappointingly, despite an alleged Microsoft developer saying they would look into it, the attack on the server has continue with little alteration to their frequency and numbers. Had they changed and been considerably less aggressive I would have lifted the ban.
You can now create "statistics" about Rakudo performance (perhaps to augment your "lies" and "damn lies" ;-) using new funtionality added to the 'tools/test_summary.pl' script. It's under the title "Simple Relative Benchmarking", and needs at least two runs to give usable data. Please try it, and compare findings in #perl6.
With up to about 2% additional run time, test_summary gets Rakudo's Test.pm to emit per-test timestamps to microsecond resolution. Then test_summary calculates the (real) execution time of each of the more than 30000 spectests and inserts the results into 'docs/test_summary.times' in JSON format. That accumulates the results of the five most recent complete runs in FIFO fashion, occupying about 2.5 MB.
Yesterday I was in a class taught by one of the folks at Percona, the MySQL and LAMP stack performance experts (they're the ones behind mysqlperformanceblog.com). Sharding was covered and though I learned a lot, it also reinforced my opinion that this is a dubious technique which fanbois like to reach for waaaaay too soon.
This is the obligatory first post on the site..and back in the perl world.. I've been away for a while (long story for another blog).. but am back and excited to continue the trek!
perlmv is a script which I have personally been using all the time for years, but has only been uploaded to CPAN today. The concept is very simple, to rename files by manipulating $_ in specified Perl code. For example, to rename all .avi files to lowercase,
$ perlmv -de '$_=lc' *.avi
The -d option is for dry-run, so that we can test our code before actually renaming the files. If you are sure that the code is correct, remove the -d (or replace it with -v, for verbose).
perlmv can also save your code into scriptlets (files in ~/.perlmv/scriptlets/), so if you do:
There is a Perl module (by coincidence, also Portuguese authored) named Text::ExtractWords that performs more or less the same as the unix command toilet^H^H^H^H^H^Hwc. It returns an hash of words mapping them to their occurrence count.
The module is not bad. It is written in C making it quite fast when compared with Perl code on big strings. Unfortunately, it has a main limitation: unicode. Although it supports a 'locale' configuration parameter, it seems not to affect its behavior regarding unicode characters, that is, looking to them as single ASCII characters.
I do not have any experience on dealing with unicode from C. I remember looking to some 'w' functions (wchar.h) but not getting real good results. Probably when I have more time I will look into it.
But for now, I need a way to compute a word histogram from a unicode Perl variable. I am doing it by splicing the string with white spaces, and for each element, adding it to an hash.
It works. But it is slow.
This raises two different questions:
is there any faster way to do this from Perl?
is there any other module that I can use to perform this task?
I took over the first perl FFI, C::DynaLib some years ago, when gcc still defaulted to the simple cdecl calling convention. Push args with alloca on the stack, and call the functions without args, but the alloca'ed args were picked up by the called func. Simple and fast.
For some time now cdecl does not work anymore OOTB, and I thought it's the new gcc-4 stack-protector, tls or such which broke the ABI. It was not. It also fails with gcc-3.4 with the same new layout, but at least I understand now the new gcc ABI and found a way to continue with cdecl. Interestingly some platforms like freebsd work OOTB with gcc and cdecl, msvc also.
The fallback to cdecl is the hack30 scheme, which is ugly. hack30 cannot do floats nor double.
The Perl Survey is reaching its final stages, and will be going live within the next week or so. While I had planned to host it myself, the autocomplete functions that I added into the survey weren't fast enough for the speed your typical programer types at, and I got the very kind offer from Strategic Data to host it using their existing infrastructure (and to continue to run the survey every couple of years).
German Perl Workshop are kindly sponsoring me to come and speak at their conference, where I will be giving two talks. The first will be on the preliminary results of the Perl Survey, and I hope to finish up the grant shortly after that. The second is titled Don't RTFM, WTFM! where I hope to go over some of the approaches to documentation we've used in the Catalyst project over the years, and then go through how to document a distribution with many moving parts in a way that a developer with basic skills can then use to write their own software. I'm hoping to use the example of WWW::Facebook::API, pending my ability to work out how to use it.
Someone responded to my first post and asked a question: How differs Kephra from Padre?
In many ways:
* Kephra has much less dependencies (Wx and config parser)
* different feature set
* much older project
* smaller dev team (currently)
of course we stay upon the same core technologies but we have different goals i think. So far I understand Padre, they have the known IDE and larger editor (Ultraedit and Jedit and ...) in mind and want to slowly grow into that direction. And thats good for Perl, but thats not desirable to me. I started Kephra to make things differently then I saw it around. And the editors I've seen didn't provide the degree of freedom I needed to make the changes I wanted there. So you need to build a new "platform". Yes I was only one but brave. Today we have an editor with the
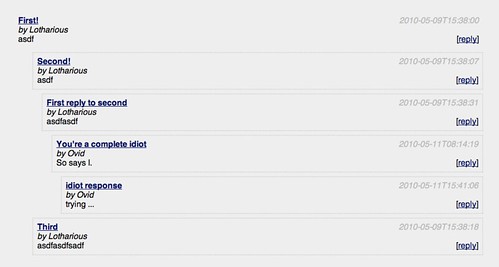
Not too much about Perl, but just wanted to say that sometimes I have a lovely feeling of accomplishment after struggling to find a good approach. After considering my options about forums, I decided to continue on my own. With the proper tool selection, they're incredibly easy. Below is sample output of my alpha code.
A late and very short summary this month, as I was hoping to have a bit more news this time around. As David notes in his update, the work on the Metabase has been continuing, with some stress testing to ensure we can handle a high volumes of report submissions. There have been some upgrades to the code during the last month, as we have refined the APIs. Unfortunately we've hit a hurdle with the search API at the current time. Once we overcome this, then we should be in a good position to make the switch to fully support the Metabase submission system. It's been a long time coming, but we are getting close.
This month has also seen lesser fixes to the Reports website and Statistics websites, mostly to correctly reference the newer GUID identification system. Unfortunately a lot of attention has been taken up by the release of version 2 of the CPAN Meta Spec, which several of us involved with CT2.0 have also been involved with, particularly David Golden. Hopefully we'll have a longer summary next month, with many more details of progress.