So today, to start the new year right, I really am going to have a look at Moose coercion which I have been promissing to do since this
post
. So to refresh your memory I had created my
types
role and one type and added it to my accessor like this
has view => (
is => 'rw',
isa => 'View',
);
So what exactly does coercion do for us? Well as I had illustrated in a early post what I want it to do it take an input hash and then create an object from that hash to save us from typing up such unsightly things as
Welcome to the Perl 6 Hands-On Workshop, or Perl 6 HOW, where instead of
learning about a specific feature or technique of Perl 6, we'll be learning
to build entire programs or modules.
Knowing a bunch of method calls won't make you a good programmer. In fact,
actually writing the code of your program is not where you spend most of
your time. There're requirements, design, documentation, tests, usability
testing, maintenance, bug fixes, distribution of your code, and more.
This Workshop will cover those areas. But by no means should you accept
what you learn as authoritative commandments, but rather as reasoned tips.
It's up to you to think about them and decide whether to adopt them.
Project: "Weatherapp"
In this installment of Perl 6 HOW we'll learn how to build an application
that talks to a Web service using its API (Application Programming Interface).
The app will tell us weather at a location we provide.
Sounds simple enough! Let's jump in!
One of my tasks when I'm not working or writing Perl code is to keep the
finances of the Frankfurt Perlmongers e.V. club in order.
Part of this is doing the taxes but a more important part is to pay the
incoming invoices in time and to keep all the receipts for this in order.
As we do most transfers electronically, it was a long-term goal for me to
provide the board with an automated monthly account statement.
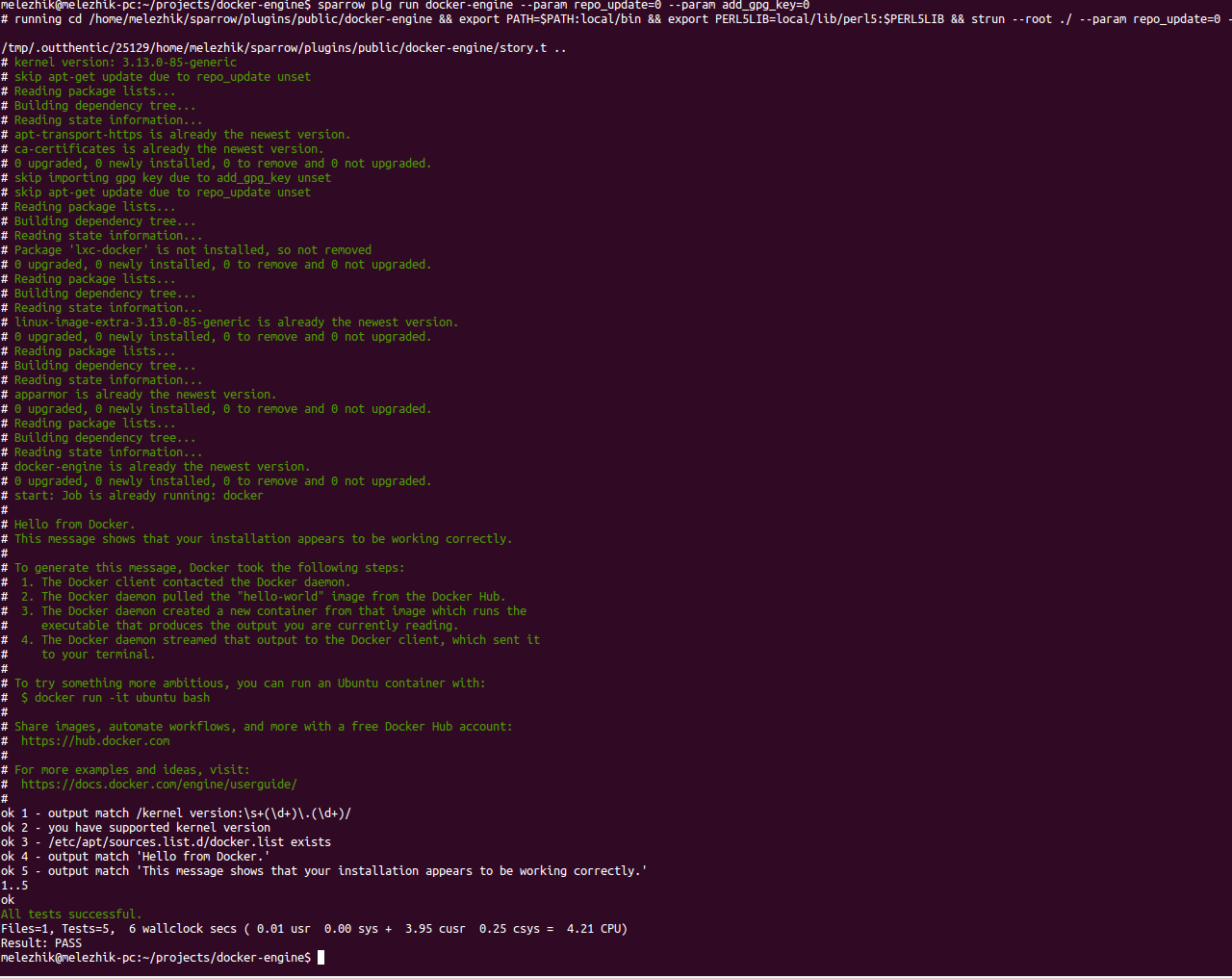
Docker is quite popular solution to rapidly spin up developers environments. I have been playing with it and it seems fun for me. The other fun thing I found that Sparrow could be a good solution to build up new docker images.
Here is short example of how it could be. A few lines in Dockerfile and you have a GitPrep server up and running as docker container. Whew!
Well off track again. So I am not going to do my bit on coercion today after all. If anyone out there was actually downloading my code and running my tests you might see this;
Load of Database/Accessor/DAD/Types.pm failed:
Error=Can't locate Database/Accessor/DAD/Types.pm in @INC (@INC contains: D:\GitHub\DA-blog\lib D:\GitHub\Replay\lib C:/Dwimperl/perl/site/lib C:/Dwimperl/perl/vendor/lib C:/Dwimperl/perl/lib .) at (eval 378) line 2.
Database/Accessor/DAD/Types (Database::Accessor::DAD::Types) may not be an Database Accessor Driver (DAD)!
fREW's article on using it, although the specific setup refers to a previous repository that can still be cloned but it's probably not maintained any more (not reachable from Github's portal, anyway);
Currently rakudo.js is at the point where: node rakudo.js --setting=NULL -e 'use nqp; nqp::say "Hello World"'
works but node rakudo.js -e 'say "Hello World"' doesn't.
What's needed for the later is to get rakudo.js (Rakudo compiled to JavaScript) to compile the setting
The general work-flow for that is:
Try to compile the setting with rakudo.js.
While rakudo.js is compiling some error appears.
I then figure out wheter it's a result of a missing feature or some bug in the js backend.
I implement the feature and write tests for it or fix the bug.
I then repeat the process.
Lather, rinse, repeat.
Until the setting compiles Rakudo.js is not yet usable by users.
Even getting something very simple like say "Hello World" requires a fair chunk of the setting to work.
The rakudo specific work is done in the js branch of rakudo https://github.com/rakudo/rakudo/tree/js.
Most of the work on the backend itself is done in the master branch in the nqp repo.
I recently wrote about Veure's test suite and today I'll write a bit about how we manage our database. Sadly, this will be a long post because it's a complicated problem and there's a lot to discuss.
When I first started Veure, I used SQLite to prototype, but it's so incredibly limited that I quickly switched to Postgres. It's been a critically important decision, but I want to take a moment to explain why.
All software effectively has four "phases" which amount to:
Initialization
Input
Calculation
Output
Note that we could rewrite the above as:
Initialization of data
Input of data
Calculation of data
Output of data
Notice a pattern?
Yeah, I thought so. There are all sorts of areas where we could get things wrong in software, but the further down the stack(s) you go, the more care you need to take because the more damaging bugs can be. Data storage is often pretty low in your stack and you don't want to get this wrong. So what happens?
Now to get back on track to what I wanted before I made a little Boo-Boo, So in today's post I am going to have a quick look at Moose and its Coercion abilities. One thing about moose Coercion is it works along with Moose Types so you can't have one without the other.
So lets start wit the Accessor.pm 'View' attribute.
Right now we have this
has View => (
is => 'rw',
isa => 'Object',
);
Which is fine but there is noting stopping my from entering any type of object in there so lets fix that
Back in the day, I wrote Perl 5 module
Number::Denominal that breaks up a number into "units," say, 3661 becomes '1 hour, 1 minute, and 1 second'. I felt it was the pinnacle of achievement and awesome to boot.
Later, I ported that module to Perl 6, and recently I found out that Perl 6
actually has .polymod method built in, which makes half of my cool module entirely useless.
Today, we'll examine what .polymod does and how to use it. And then I'll
talk a bit about my reinvented wheel as well.
Denominated
The .polymod method takes a number of divisors and breaks up its invocant
into pieces:
While playing with docker I created a simple sparrow plugin to install docker engine on Ubuntu Trusty 14.04 (LTS) - https://sparrowhub.org/info/docker-engine . Please let me know if other platform to support you need! ;))
Well in my last post I made a little boo-boo. Well a few really. I wanted to get rid of my 'View' class as it was the same as my 'Element' class once I stripped out some parts. Unfortunately I discovered that I have to add in a number of other attributes to my 'Element' class which should never be part of the 'View' class. So I am going to backtrack on taking View out and put it back in.
Now my second boo-boo from my last post, I wanted to have first letter upper case names for my Accessor attributes like this
Much of what I do involves retrieving stuff over the HTTP family of protocols.
My go-to solutions are either the APIs of LWP::UserAgent/WWW::Mechanize
or the API of AnyEvent::HTTP, depending on whether I want some kind
of concurrency or not. Since I found Future as a somewhat nicer way of
structuring callback hell a bit differently, I've looked around for a nice
implementation of a HTTP client that works with various backends and maybe
even without a backend.
DISCLAIMER: data theft is a serious crime in many jurisdictions. The author does not condone or encourage anyone to break laws. The information provided here is for educational purposes only.
PART I: Anguish: The Invisible Programming Language
You may be familiar with funky esoteric languages like Ook or even Whitespace. Those are fun and neat, but I've decided to dial up the crazy a notch and make a completely invisible programming language!
I named it Anguish and, based on my quick googling, I may be a lone wolf at this depth of insanity. In this article, I'll describe the language, go over my implementation of its interpreter, and then talk about some security implications that come with invisible code.
The Code
Here's an Anguish program that prints Hello World:
If you have been following along you may remember this post, in which I introduced what my API was going to look like. Up till now I had only a few of the basic parts of that list in the in Accessor.pm jsut for quick testing. Now before I add in these new elements into my code I think it is time to review my Accessor.pm and see how I can clean it up before I add the others.
So I started with the 'View' and 'Element' classes, bundled in Accessor.pm and I see that I still have a 'retrieve' sub in each. A few posts ago I gave up the idea of trying to enforce the DAD writers to create these subs so there no reason to have them there at all. So out they go.
[This is a post in my latest long-ass series. You may want to begin at the beginning. I do not promise that the next post in the series will be next week. Just that I will eventually finish it, someday. Unless I get hit by a bus.
IMPORTANT NOTE! When I provide you links to code on GitHub, I’m giving you links to particular commits. This allows me to show you the code as it was at the time the blog post was written and insures that the code references will make sense in the context of this post. Just be aware that the latest version of the code may be very different.]
I search Perl information everyday. I'm Japanese. But I don't know what web site write about Perl. I want the site which I can see Perl latest information.
Personal blog entry is very interesting. But personal don't have power of advertise. Many information by company hide these entries.
I want to read the good Perl entry written by good Perl programmer. I want to find good topics. If anyone don't read the entry, the entry is sad.
Please tweet about Perl for many people to be able to read you entry
"Perl Tweet Timeline news" pick the tweet which contains "perl" or "Perl". If you write your entry and tweet by using English, You inform people your entry through this site.