My talk from this months SydneyPM. Wherein I install OpenWRT on to an inexpensive TP-Link pocket router, install perl and attempt to smoke CPAN.
I also introduce OpenWRT in possibly too much detail, and dont really explain what smoking CPAN is.
Exception::Stringy - Modern exceptions for legacy code
A small recap of Perl exceptions
Basic Usage Of Exceptions
In Perl, exceptions are a well known and widely used mechanism. It is an old
feature that has been enhanced over time. At the basic level, exceptions are
triggered by the keyword die. Exceptions were initially used as a way to stop
the execution of a program in case of a fatal error. The too famous line:
open my $fh, $file or die "failed to open '$file', error: $!";
is a good example.
The original way to catch exceptions in Perl has a somewhat strange syntax,
it's based on the eval keyword and the special variable $@:
eval { code_that_may_die(); 1; }
or say "exception has been caught: $@"
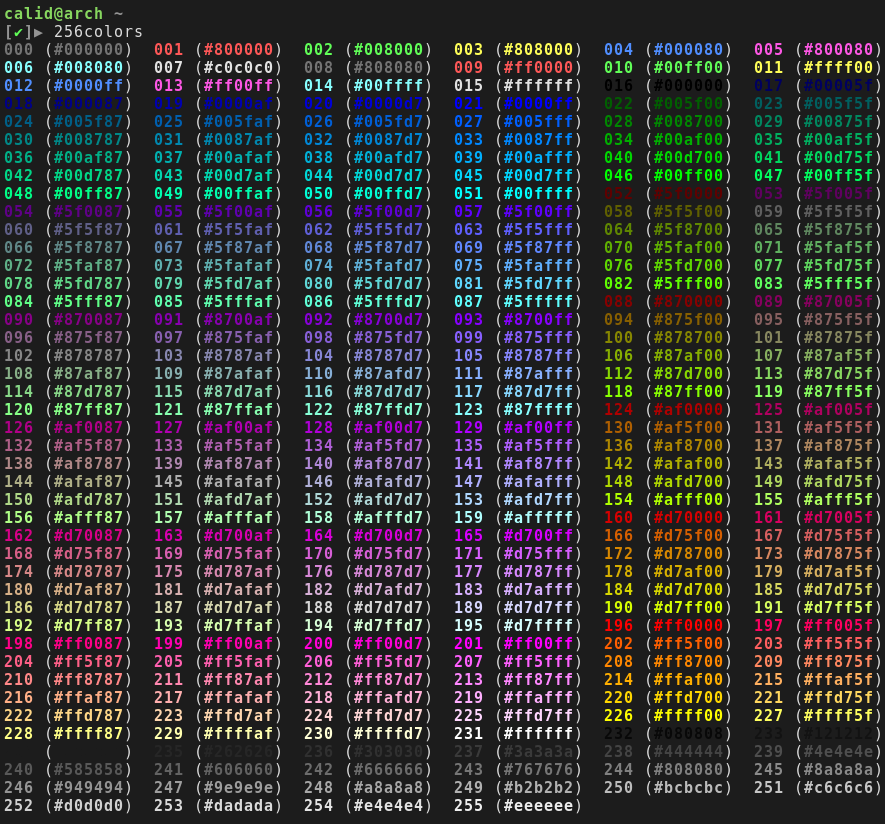
I was surprised to see there aren't any 256colors scripts installable from the CPAN. I have one I've been using locally for awhile, so I turned it into a proper module and uploaded it as App::256colors (first!).
Compared to the many other 256colors scripts floating around the internet, this one will print 256 color codes in both integer and hex/rgb format, which can be useful depending on what you're tweaking (e.g. Xdefaults vs PS1). I also think the output format is pretty nice (although I may be biased :) )
Based on the size of your terminal it will wrap the column output accordingly, as well as invoke the less pager with suitable options if the terminal is too small to display all the codes.
It's a pretty simple script, but I've found it invaluable for getting my color schemes "just right."
We can has shirts! Grab one tomorrow for AUD$30 or contact us for shipping etc. (Thanks CSW for the rush order)
Front
Back
We have no Raptors in Australia, so settled on the Australovenator - which is as real and factual as anything on wikipedia.
Speakers:
Lloyd Fournier - getting started with perl 6
Kieren Diment - TBD
Myself - Perl and OpenWRT
Jim Donovan (Lightning Talk) - Skills required nowadays in the Perl5 environment
Location: Date: Wednesday, 16th December 2015
Time: 6-9pm
Place: Ooyala and Telstra Software Group Office, Level 9, 175 Liverpool St, Sydney
Best train station: Museum seems best, followed by Town Hall
The London Perl Workshop 2015 was the first workshop in a long time where I did not present a talk. This left me free to listen to the talks without worrying about my slides or wanting to go through my demo one more time. So, without further ado, here's my retrospective of the talks I saw:
[This is a post in my latest long-ass series. You may want to begin at the beginning. I do not promise that the next post in the series will be next week. Just that I will eventually finish it, someday. Unless I get hit by a bus.
IMPORTANT NOTE! When I provide you links to code on GitHub, I’m giving you links to particular commits. This allows me to show you the code as it was at the time the blog post was written and insures that the code references will make sense in the context of this post. Just be aware that the latest version of the code may be very different.]
Last time I actually got down to it and wrote some code: Date::Easy now has a date constructor for turning arbitrary human-readable strings into date objects. Now it’s time to expand on that and allow even more formats.
My
latest blog post
looks at a grammar reuse, comparing regular expressions, PEG, Perl 6 grammars and general BNF parsers, including Marpa. A good property to have in itself, grammar reusability is crucial if a parser is going to be the basis for language-driven programming.
I released Validator::Custom 1.01. More simple and more flexible interface is added.
Document is rewrited completely. Backword compatible is kept completely.
Checking functions and filtering functions is added. You can use these in your source code.
A validation object which save the result of validation is added.
Usage
You can use checking function and filtering functions. The validation result is saved to the validation object. You don't need to learn complex things.
On the 1st of October I launched a daring crowdfunding campaign. I asked over thirty companies directly relying on my open source work to split a rather modest bill, allowing me to exclusively focus for at least a year on several key parts of the Perl5 library repository (CPAN). Two months later, after a really promising start, the campaign is effectively dead.
I'm doing heater runs in Taungoo Station when someone tells me about a problem in Nouveau Limoges, another station in the Sol System. I mosey on down to the port, hop in Serenity, my corvette class spaceship (with some "quiet" modifications), and launch. Serenity's an older ship and she higher maintenance than I would like, but she keeps flying and that's good enough for me.
A little over 7 segments later (a long, boring flight), I arrive at Nouveau Limoges. And that's when the trouble kicks in. You see, I'm a Consortium citizen, but Nouveau Limoges is a Gaul station and I forgot to renew my visa. Immigration computers notice my status and I get auto-deported back to the station I came from: except I am still on Serenity and she doesn't have enough anti-matter reserves to make the flight back. An HTTP redirect loop ensues and ...
I found that bug hilarious and it will be fun to resolve. Sadly, it probably won't be me who fixes it, even though I want to dig in.
We started a kickstarter to write and print a Dancer book. We have less than 10 days to sponsor it and we need your help!
We want to thank Evozon, Booking.com, and Weborama who have provided a generous donation to make this happen.
If you would like to see this book published you can help fund it. And if you work for a company that uses Perl and could use a few copies of the book, please consider suggesting they help sponsor the book as well.
What will you get? You will get an official Dancer book written by the core team. You will get the latest features covered - Dancer2! You will get examples that cover practical usage - websites and web APIs. You will get our appreciation and thanks. And above all, you will get to know you helped sponsor a new Modern Perl book, by people who write modern software out of community interest and wrote the book for the benefit of the community and the language.
I uncovered and fixed many 5.22 problems with
cperl already, but in the last months I
was busy to port the 3 compilers B::C, B::CC and B::Bytecode to 5.22.
As I said in my interview
it's my belief that if all current p5p core committers would stop
committing their bad code it would be actually be the best for the
perl5 project. They weren't able to implemented any of the already
properly designed features from perl6 in the last 12 years, and every
feature they did implement is just so horrifibly bad, making our
already bad code base, which led to reimplementation efforts of
perl6/parrot with a better core, even worse. With cperl I can only
undo a little, but when they start breaking the API and planned
features in an incompatible way they should just stop.
Nevertheless, 5.22 added a significant improvement from outside,
syber's monomorphic inline caching for method calls besides the
internal improvement of multideref by Dave Mitchell.
Please join us at Sydney Perl Mongers for our December/Christmas meeting and last meet for the 2015 year.
Date: Wednesday, 16th December 2015
Time: 6-9pm
Place: Ooyala and Telstra Software Group Office, Level 9, 175 Liverpool St, Sydney
One of the developer evangelists from the Ooyala API team at the TSG will present a short intro/talk. Mandy, who so generously organized this, hopes to also show off Ooyala features via perl code!
We will hopefully have the lifts open during that time, so people can freely come to level 9. Once there, they will see an Ooyala / TSG sign and can come over and knock/wave through the glass door.
If the lifts are not letting people up there will be at least one person from Ooyala/TSG to ferry people up the lift they will just need to call you or me or something like that.
Best train station: Museum seems best, followed by Town Hall