Side note: Why did I miss that last Perl QA-Hackathon? I've attended every one since they started ... except for the last one. I missed it because the damned French government can't get around to reissuing my damned visa, despite the fact that they're legally required to. I've also had to pass on some business opportunities and a trip Romania. /me is very unhappy with France right now.
In my last post I had promised to write an update on the status of the GPW 2014 in May. It is only a minor update, but here it is.
We are happy to announce that everything is working out great so far. We've found a really cool venue. It's pretty central and will fit up to 200 perl hackers comfortably. We have also made progress on getting the talks on video.
Regarding the social event we are still in the finding phase and do not have any concrete information yet.
The progress on the official Act website is good, too. I will be online at the beginning of June.
There is more than one way to do it.Toby Inkster’s Creating your own Perl hits the nail on the head: with Perl you can choose the language that you code in
"So go on; create your own Perl. Make it your gift to yourself."
( Syntax::Collector makes it very simple, and will also help you bundle your “most used modules” - more useful modules in Toby’s article)
Today i’m going to explore one aspect of the Perl language:
how do you check that a list contains a given element?
This one is easy to miss if you only develop in Perl part-time. If you have to upgrade a CORE module (usually because another module needs that upgraded CORE module), then you need to add UNINST=1 to your make(1) invocation.
There are few things more aggravating than to "make install" several times with different tweaks only to always end up with the same, out-of-date module stubbornly still installed. All for the lack of an UNINST=1.
The QA Hackathon website has had a bit of an update today. Primarily a new page and new photos have been added, but plenty of other updates have been included too.
In the meantime we also got access to the English version and prepared translations of the article. I am really glad to announce that just within a few days
there are now 8 versions of the tutorial:
Similar to the Pinto Tutorial, there are many other articles on the Perl Maven site that have been translated. For each page, on the left-hand side you can find links to other versions of the specific article.
I am really impressed with all the work the translators have been doing in the past several weeks. For the list of contributors, and for the number of pages each language has, visit our Meta site.
A highlights/summary of recent activity and discussion on the #perl6 IRC channel on Freenode.net:
nwc10: "jnthn: WTF did you just do? nqp head is 28% faster than 5 hours ago"
nwc10 noted a 10-fold speed up for some NQP code: "nqp-jvm: 1.4725e+02 ... nqp-parrot: 2.0425e+03".
pmichaud landed Rakudo commits to "Speed up repeated shifts of large lists/arrays by 70%+" noting that "More improvements are coming; this patch just gets a couple of the current big bottlenecks out of the way".
Two days ago I was so excited! I had an idea how to make the Perl world a bit better, faster and simpler. Of course, I didn’t spread such exciting news until I checked and double-checked and benchmarked, until I’m absolutely sure I’ve found The Holy Grail.
Well, see the title. It hurts. All my benchmarks contained a terrible mistake. And those +20%, or, maybe even +100% speed boost PugiXML interface could provide doesn’t worth all the buzz I created.
I was recently interviews to the Russian online Perl magazine Pragmatic Perl. It was a pleasure and truly an honor. The last issue just came out and the interview is appearing there in Russian. If you speak Russian, go ahead and read it here.
If, like me, you do not speak Russian, following is the uncensored version in English.
One of my next reviews is going to be web frameworks. I've posted my current plans on my new blog, where I'll be recording progress as I work through the review. I plan to implement the same application in each of the main frameworks I review, but would also be happy if others want to join in.
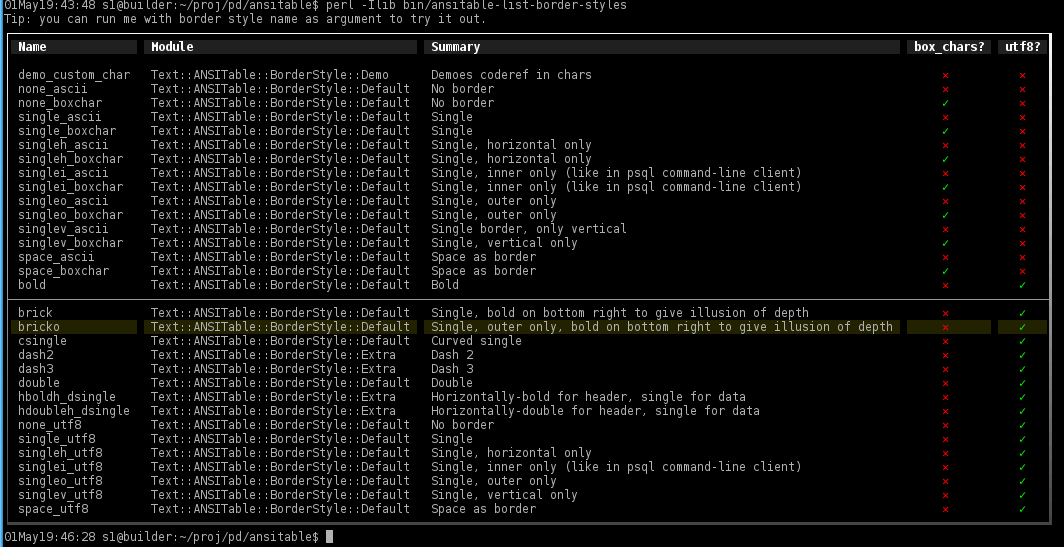
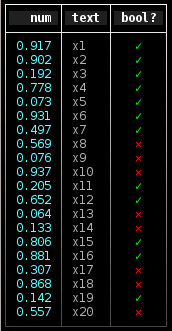
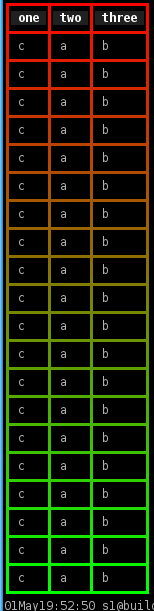
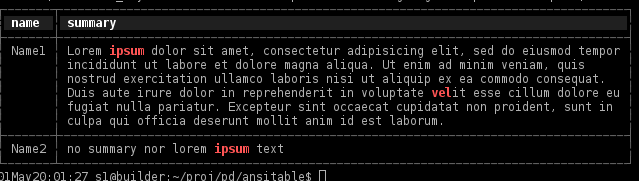
Even in the good old days of DOS, we already had color tables and extended ASCII characters to draw various border styles. So why limit ourselves with something like Text::ASCIITable? Introducing Text::ANSITable to make your text tables look pretty in terminals. See pictures for some examples:
Unfortunately, the idea contained fatal flaw. See the following post for explaantions.
Once upon a time I faced a huge pile of HTML files which I had to analyze. Say, there were about 1 000 000 of them. Say, 100 Gb of data.
Most of you would say “It’s not that much!”. And you are right. It’s not.
But then I’ve decided to estimate time required to process that pile of files. I quickly put XPaths of what I was needed together and got a prototype in Web::Scraper. And here I go: ~0.94s per file, i/o overhead not included. That occurred more than 11 days on my laptop. Phew!
There are only a few more days left to chip in to sponsoring work on Pinto. If you're still unconvinced or haven't thought about it yet, let me give my point of view on why you should spare a few minutes and a few bucks to sponsor Pinto.
My experiment to crowd fund Jeff Thalhammer's Pinto development is going well. It's 87% of the way there. We need $503 to reach the campaign minimum. We have a week left to get that remaining 13% to get the campaign to "tilt", and I think we can get even more than that. Our secondary money goal is $5,000, all of which goes to Jeff to work on open source features of Pinto. I like $6425 (two perfect squares next to each other). That's 0b0001100100011001 (repeats the bit pattern) or 0x1919 (repeated, and the same prime next to itself).
On Monday Sean Quinlan became the 100th contributor. We have a week left to get 128 contributors. Part of the experiment is to get as many people involved as we can, at any level. I don't care how much you donate: a $1 donation is just as good as $100 when we are counting contributors.
Padre, the Perl IDE, is the work of a number of people with the goal of creating an IDE written in Perl itself.
Padre 0.98, according to the Release History page has finally been released 1 year and 1 week after 0.96.
This is a long time between releases. In part this can be put down to me as the Release Manager. As things go, we all have interests and busy times in our lives that can take us away from projects that we give up our free time to contribute to. For me, it's been a case of discovering photography. So instead of looking at code I'm looking at images I have taken.
This has meant, that try as I might, I never focused back on Padre and releasing Padre enough to get the new version out the door.