Recently we were trying to fix a database performance issue and I had to hit the DBIx::Class irc channel for some advice. Specifically, mysql has an issue where a query with text or blob columns forces a disk sort under certain conditions. Suffice it to say, we hit those conditions with several text columns and benchmarking certain queries showed that removing those columns from a query significantly sped up said queries. That, unfortunately, is a bit tricky under DBIx::Class, but Matt Trout made an excellent suggestion which I later implemented. Why not do a virtual vertical partition of our tables?
Rakudo Star, the first [almost] complete and usable implementation of Perl 6, is expected to be released this Thursday, July 29. It is obvious that the community is looking forward to it as there has been a lot of talking, so the Barcelona Perl Mongers will be celebrating, taking advantage of the fact that it coincides with our monthly meeting.
We have prepared a pretty complete menu to introduce you to Perl 6:
20:00 - entrée: a little tutorial to install Rakudo and Parrot
20:30 - first course: the translation of the Perl 6 presentation in Warszawa.pm
21:00 - second course:Pm's presentation at this year's OSCON
22:00 - desserts:/(sausage|beer)*/ out in the fresh
The chosen venue is the traditional C6-E101 room in the C6 building at UPC's Campus Nord (the same place for those of you who have attended previous mongers parties). If everything goes according to plan, we will even be broadcasting the event.
Edit: Thanks to snarkyboojum for reminding me that it's not fully complete yet, but almost there.
The YAPC::NA 2010 Surveys have now closed. I'm now reviewing the data to produce the emails for speakers, the website pages for results for public consumption and the feedback documents for organsiers. If all goes well expect to see some postings tomorrow.
In addition, I've been refining the scripts that I use to perform the analysis of the results. One aspect that has been missing for the past few years is the output that provides the raw data. I'm please to say that this has now been added. This now means that when I upload the webpages, I can now provide all the data used to perform the analysis for the webpages. Note that the feedback questions and all the talk evaluations are omitted from this data.
Many people are saying that Perl 5 should be renamed. I disagree. Perl is Perl. That's what makes it great. However, I agree that the 5.x version naming is a burden for people who want to advocate the modern relevance of Perl. So, why don't we just drop the "5."?
Perl 12. The current version of Perl is 12.1. That looks right to me. It just fits. Perl 12.x (and 14.x, etc...) just makes more sense because it conveys that Perl is mature (it is) and it has a healthy schedule of stable major releases (it does.)
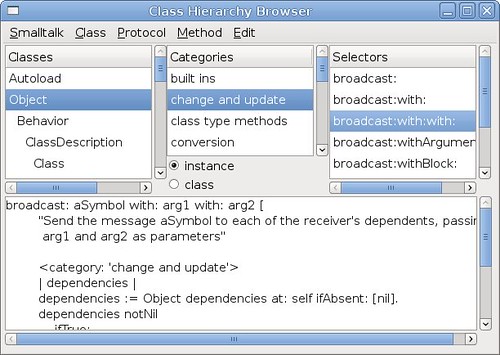
You may have seen or played with the Smalltalk browser before:
If you have, you'd love it. It makes it trivial to browse through, visualize and manage a project. However, we don't have anything like this for Perl. brian d foy has tried to create a Perl browser (with code on github), but that's the only significant effort in this direction I've seen. Padre has a ticket for a subset of this functionality, but as far as I can tell, it has the same limitation as brian's approach (please correct me if I'm wrong): it's file-based.
Given Perl's dynamic nature, what if we ditched the file-based heuristics and actually examine running code? I've been thinking about this.
I already reported about WxDocular and about the WxPerl course I will give in Pisa. I even wrote about Kephra which will have a new release really soon.
What i want to tell now, touches all these 3 topics. For the WxCourse i write a specialized Editor-App for easy skipping between the many examples, alter and run them and browse some docs. And this App is also the goal, all these examples drive toward. I like the concept of working with life and real purpose code if you really want to learn something useful. The other effect of this selfhosting concept is that most essential information are always at reach for the students.
What do I mean by this? - Over the last 10 years I've given half a dozen or so presentations at conferences, each time someone sets up a video recorder and I think 'great lots of people will hear me present this' (I upload the slides, but it's never the same). Unfortunately each time the work it takes to organise and sort these videos mean they never get uploaded anywhere (have you tried video editing? - it's REALLY slow & hard work).
So, this year (in addition to anything others have organised) I'm going to record my own presentation... and I'm going to use software!
http://silverbackapp.com/ (Mac only - 30 day free trial - this will cover YAPC::EU if you download now! http://camstudio.org/ sounds similar for Windows) lets you record not only what's happening on your screen, but also your audio, and optionally uses the laptops built in camera to record your face (this can be turned off).
Wednesday I gave my roles talk at OSCON (please rate it if you've seen it) and, as usual, I came away learning things from the questions. My favourite, by far, was Perrin Harkins asking whether or not we at the BBC found method conflict resolution to be our greatest win when we switched one system over to roles instead of inheritance.
Today was pizza, hellos, installation of EasyEclipse for each of us, a short Heated Discussion about Eclipse and pros and cons of it, installs of Mason locally and on the server machine, capped off by some testing and promises to work on this tomorrow.
The current plan is to get us versed in Mason and build an example project together. Cross your fingers for cohesiveness.
Event: Birmingham.pm Technical Meeting
Date: Wednesday 28th July 2010
Times: from 6pm/8pm onwards (see below)
Venue: Birmingham Science Park Aston, Faraday Wharf, Holt Street, Birmingham, B7 4BB.
Details: http://birmingham.pm.org/tech/next
Talks:
Into the Black: Exploring North Korea (or, how I learned to stop worrying and love the bomb) [Mike Kemp]
Details
This month's meeting will be at the new tech meet venue, over at The
Birmingham Science Park Aston. Car parking is available, as is wifi and pubs nearby :)
Announce: Rakudo Perl 6 compiler development release #31 ("Atlanta")
On behalf of the Rakudo development team, I'm happy to announce the
July 2010 development release of Rakudo Perl #31 "Atlanta".
Rakudo is an implementation of Perl 6 on the Parrot Virtual Machine
(see http://www.parrot.org). The tarball for the July 2010 release
is available from http://github.com/rakudo/rakudo/downloads.
Please note: This is not the Rakudo Star release, which is scheduled
for July 29, 2010. The Star release will include the compiler, an
installer, modules, a book (PDF), and more.
The Rakudo Perl compiler follows a monthly release cycle, with each release named after a Perl Mongers group. The July 2010 release is code named "Atlanta" in recognition of Atlanta.pm and their Perl 5 Phalanx project, which they selected for its benefits to Perl 6.
Some of the specific changes and improvements occurring with this
release include:
I really like the Perl QA wiki. Is there something similar for Perl module authors? I'm looking for updated information on name recommendations (and don't say to send a message to modules@perl.org because the "official" list says it's a closed list), tools to help create new distributions (I haven't been able to install Dist::Zilla yet, I'm working through it's long list of dependencies), and any other suggestions that module authors might need.
I'm working on learning what currying can be used for. I tried at first to install from the cpan shell on my WinXP netbook, but this failed a large chunk of testing and I didn't bother attempting the install. PPM did the job, however, and after confirming the install is good, I have moved to flipping between reading HOP and trying code out.
When testing a subroutine, it might interact with another subroutine. A useful trick is "mocking", which is to provide a given answer back from that subroutine, helping you imitate some situation for your subroutine to run into, and for you to test.
There's a very easy way to do this:
{
no warnings qw/redefine once/;
*My::Object::connect = sub {
ok( 1, 'Reached connect' );
isa_ok( $_[0], 'My::Object' );
is_deeply( $_[1], { something => 'else' }, 'connect method params' );
};
}
This is a very simple and relatively controlled way to override the subroutine in the symbol table. It is usually what I use.
If you prefer not to play around with the symbol table yourself and leave it to the professional, there's always chromatic with his excellent Test::MockObject which is great for this particular purpose and both you and I should be using it. :)
http://www.perl.com/ has been relaunched! - VERY basic at the moment, but this is the start.
Tom (who owns the Domain) and O'Reilly (who's strong support of Perl over the years has helped make it such a great language) have been kind enough to let the TPF take on Editorial control and the site has now joined the Perl.org family.
As you can see initially we've ported the existing content over (but still need to link it all in to make it easy to find) - Chromatic aims to have a least on post a week about the Perl language, it's libraries, and the great community surrounding Perl.
Basically watch this space - or rather watch http://www.perl.com/!
While doing research for my OSCON talk on roles, I was struck by something very interesting. You could, if you wish, group OO languages into multiple inheritance and single inheritance camps. Languages like C++ and Perl, which allow multiple inheritance, generally have taboos against it. As a result, experienced developers create designs which allow them to avoid multiple inheritance.
Single-inheritance languages, such as Ruby and Java, tend to offer language features to substitute for the lack of MI (e.g., mixins and interfaces). For these languages, use of these features is encouraged and hyped, as opposed to MI being discouraged and avoided. I'd be rather curious to know how this impacts the software design trends in those languages.
This time I am writing mainly for beginners, and not specifically for Perl programmers, but any programmer of any language. Skels (my abbreviation for skeletons) are totally relevant in a programming environment.
What are skeletons? There are different names for the same thing. You can call it a template, or call it a snippet. Skels, for me, are both: pieces of code, that might work or not, that might have placeholders or not, but that save you time by remembering how something is done.
I have a bunch of skeletons ready to use in my Emacs. I would like to have more, but sometimes I am too lazy and forget that with skeletons I can be yet more lazy. Some examples of skeletons: the line used in XML to refer to an external CSS file; an empty HTML document; an empty LaTeX document with the more usual packages; a LaTeX presentation document; a common POD document structure; etc.
This can be done in different ways. TextMate let you start typing something, press tab, and get your snippet expanded. I am sure vim, komodo and other editors have similar mechanisms. The important is not what editor to use. The important is to have the skeletons ready to use.
Olaf Alders's recent post about CPAN on your iPhone gave me the impetus to look at an idea I had after iBooks became available on the iPhone and iPad: to convert Perl Pod documents to ePub format for offline reading.
So I created a simple pod2epub program and here are the results along with some free books from the iBooks store:
The screen shot shows the Moose::Manual and Spreadsheet::WriteExcel documentation converted to ePub and transferred to iBooks on my iPhone. Here is a sample from the Moose::Manual ebook:
And here is another with some code:
All of the heavy lifting was done with the stalwart Pod::Simple and Oleksandr Tymoshenko's comprehensive EBook::EPUB.
I still have a few issues to resolve and formatting to tweak and after that I will upload the code to Github and then to CPAN