Its change my case yet again day here in the Moose-Pen
Yesterday as I had finishing off my tests for the Case class I was just about to move over and start writing up the code for Driver::DBI when I remember that I should have a test or two to ensure that Database::Accessor can use the new 'Case' class and that is passed it correctly down to the DAD.
I am using it right now as a field and I can test by just adding to the '31_elements.t' test case.
Frist I add in just a simple 'case' as I have already tested all the funny permutations in the '15_case.t' test case;
Talk submissions for #TPCiSLC are currently being accepted! Round 1 closing/Round 2 opening Jan 28/29.
We will be accepting proposals for the following session types:
Short Talks (20 minutes)
Standard Talks (50 minutes)
Tutorial Sessions (80 or 110 minutes)
To submit proposals for a talk/presentation, please fill out this form: https://goo.gl/forms/2qxdfgtRsdc6lXBZ2.
We encourage you to submit your talk as early as possible. We will be choosing speakers in an ongoing process, with the final submissions to be accepted no later than March 18th, 2018.
Round 1: January 1st - January 28th, speakers notified by 2/7/18
Round 2: January 29th - February 25th, speakers notified by 3/7/18
Round 3: February 26th - March 18th, speakers notified by 3/28/18
Final Speaker Lineup Announced: April 1st, 2018
Apply at https://goo.gl/forms/2qxdfgtRsdc6lXBZ2
More information at https://perlconference.us/tpc-2018-slc/cfp/
You probably have read a recent Open Letter to the Perl
Community. The letter has
generated a lot of response (173 reddit
comments as I
write this). Unfortunately, a lot of the responses are quite negative and do not match my
understanding of the letter.
I figured I share my interpretation of the words and if that interpretation does not match the
author's intent, I hope my interpretation captures the mood of the community on the matter.
A Radical Idea
The first thing the letter talks about is what it calls a "radical idea". The suggestion is for Perl 5 compiler to upgrade its backend. Instead of the current Perl VM the perl compiler uses, it would be ported to NQP compiler toolkit and will support all of the backends NQP supports, which currently is MoarVM, as the leading option, with JVM and JavaScript backends at various stages of completion as alternatives.
I started down this particular rabbit hole when (a) I had to check for date range overlaps when worrying about scheduling appraisals; and (b) my attempts to use SQL BETWEEN resulted in complicated, hard-to-read SQL.
Now you would think that BETWEEN should give you easy-to-understand SQL for date ranges. Maybe in the hands of others BETWEEN does, but for me by the time I accounted for all of the cases the BETWEEN-based SQL date range overlap detection got more complicated than I thought it needed to be. So I drew up some diagrams, which eventually led me to the realization that this:
dateA.start <= dateB.end
AND
dateB.start <= dateA.end
is all that you need. No BETWEEN needed, simple to read, and should work in any useful dialect of SQL.
In yesterday's post-ette I ranted on about how much of a smarty pants I was to use a 'param' in as the type for my 'message' part of a case statement. That was working fine until I blundered across this perfectly valid SQL
SELECT StockID, OnOrderQuantity,
CASE
WHEN Stock - OnOrderQuantity > 30 THEN 'Over Stocked'
WHEN Stock - OnOrderQuantity > 0 AND Stock-OnOrderQuantity <=30 THEN 'Stocked'
ELSE Stock - OnOrderQuantity
END
FROM Stock;
The 'else' in this case is an 'expression' and if I prototyped this out like this
As I reviewing some of my code for 'Case' statements I had chanch to stop and think about why I was using a Param class for the message on a case. Right now I have something like this;
{
left => { name => 'Price', },
right => { value => '10' },
operator => '<',
message => { value => 'under 10$' }
},
Before I had that just as a simple string like this
This month, I was tasked with implementing FIDO/U2F support for two factor authentication for a client. U2F two factor authentication requires a FIDO/U2F hardware key that you insert into your devices USB port and press a button to complete two factor authentication. There are many different vendors that make these devices, such as Yubikey etc. Thanks to the excellent Authen::U2F module by CPAN author ROBN, and Google's u2f-api.js library, implementing support for this proved to be fairly straightforward, but the process for doing this is not the point of this blog post.
The point of this blog post is that, at the time, there was no easy way to write any kind of automated tests for this. As a result, I ended up writing Authen::U2F::Tester. Authen::U2F::Tester acts like a virtual hardware device to complete FIDO/U2F registration and authentication (known as signing in U2F terms) requests.
During the ongoing development of graphql-perl, I have found it valuable to generate data structures, and to compare those with expected values. Often, these have been highly detailed rather than a subset, because I wanted to know when anything changed.
When, however, something does validly have to change, it might change quite a few "expected" outputs. If those all need updating manually, that is a lot of repetitive activity. What if the computer could do that instead? What if Perl had "snapshot testing" as used in JavaScript frontend development, most popularly in Jest?
use Test::Snapshot;
my $got = function_generating_data();
is_deeply_snapshot $got, 'test description'; # could also be in a subtest
Its test post-ette day again here in the Moose-Pen
I guess I am following a very predictable pattern The weekend is here and I just do a post on test results. Well why spoil a good thing?
Since my last test round I have changed a good number of things about but I am fairly sure that Database::Accessor is in good shape though I am not looking forward to see what sort of state Driver ::DBI is in.
As I suspected there was only very minor problems with Database::Accessor;
Looks like you planned 2 tests but ran 6.
t/15_case.t ................. Dubious, test returned
I just have to update that test count and now I get
I wrote an article about the maths behind the game Dobble (known as Spot-It in some countries). It has no pretense of strict formality but it works for reminding me the though process that leads to designing Dobble-like games. The whole process prodded me to write Math::GF, a module on Galois Fields that can be used together with Math::Polynomial, so... there's also Perl in it!
I've tried to make this blog post copy/pastable as valid perl and valid markdown. So with luck it can be copy/pasted into an editor if you want to use this.
Confluence. I don't really like it, but the major thing it's got going for it is that it's not Sharepoint. As I am spending the summer holidays doing some documentation at work, one of the things I wanted to do was to make confluence less hateful. So I cracked open the REST API to see how far I could get.
There used to be good tools, but atlassian got rid of the XMLRPC API not that long ago.
Progress I made was:
Got a list of all spaces, and all pages in each space.
Worked out how to obtain the content of a page.
Worked out how to change the content of a page (for when the time comes).
Where I got stuck:
Working out how to round-trip the confluence markup to/from markdown.
The rest of this post describes the script I put together. It's not useful enough for me to put on the CPAN but it's worth putting up somewhere.
Back in the day, when I came upon a particularly juicy tip/hint/trick/kludge/etc. I would write it down somewhere (way back -- in a paper notebook; more recently, somewhere like TiddlyWiki). But I don't do that anymore -- why?
The answer is Stack Overflow. When I have a question, a web search often has 1 or more Stack Overflow answers at the top - answers that usually help me fix (or work around) the problem I have. It really is impressive how often Stack Overflow has just the answer I need and in just enough detail. (Disclosure: I answer questions on Stack Overflow on a semi-regular basis.)
We are pleased to FINALLY bring you the news everyone has been waiting for!
It is with great enthusiasm that we happily announce The Perl Conference in North America, 2018 will be held Sunday, June 17th through Friday, June 22nd at the Little America Hotel in Salt Lake City, Utah!
The main event will run from Monday, June 18th through Wednesday, June 20th. Master Classes, training, and other activities will be held on the 17th, 21st, and 22nd. We highly encourage you to attend all days, but especially look forward to seeing you at the Main Event.
Sitting on my TODO list has been a refresh (resurrection perhaps?) of the FormFu website.
In 2017 the various contributors consolidated into a single Group on GitHub - authors of related modules are invited to donate them into that group for future maintenance etc.
Having some time off has allowed me to get through much of that aforementioned TODO list and over the last few days, the FormFu website has been ticked off of that list.
GitHub has a "pages" feature, which is based upon Jekyll. This is a convenient system for generating a static site from templates and content from Git - which also includes the hosting part for free. Everyone in the group can make changes, with 3rd parties able to use Git's normal mechanisms to send PR's, issue reports etc.
So I donated a funky new .rocks domain and used the GitHub pages to create simple new website for FormFu. Any and all feedback is much appreciated.
Looking back year 2017 brought many sweet moments, both at professional and personal front. On personal front, I have been blessed with twin girls, Aabia & Aania. Raising twins without family support is not easy for me and my wife. I am told to be prepared for more surprises.
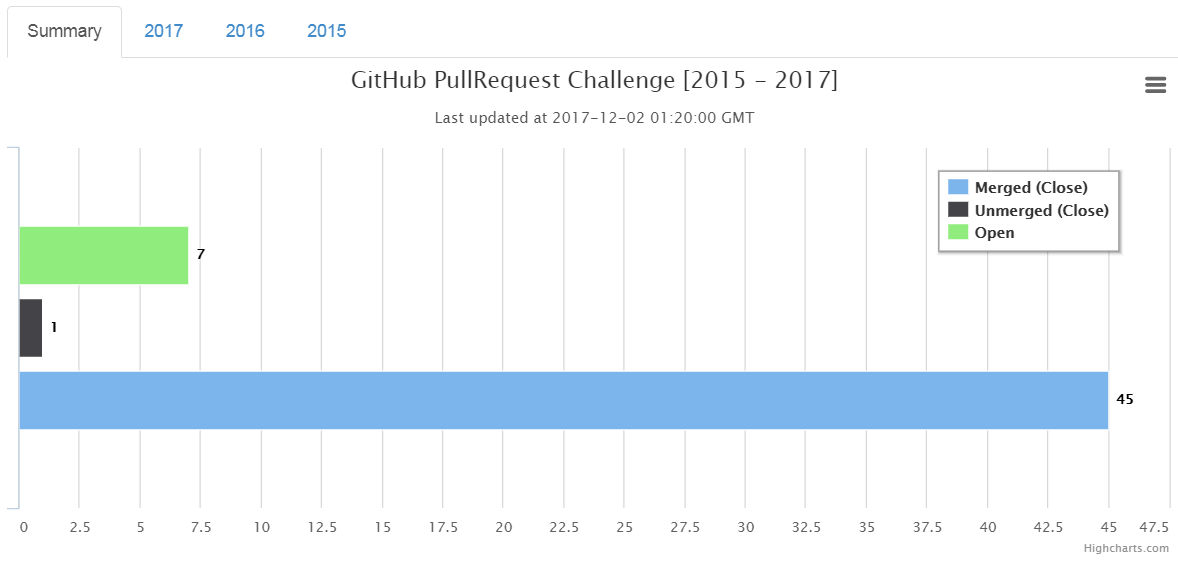
On professional front, there have been many positives to talk about. First I completed third consecutive years of CPAN PullRequest Challenge without missing a single month. I hope to carry on with the same spirit in the year 2018.
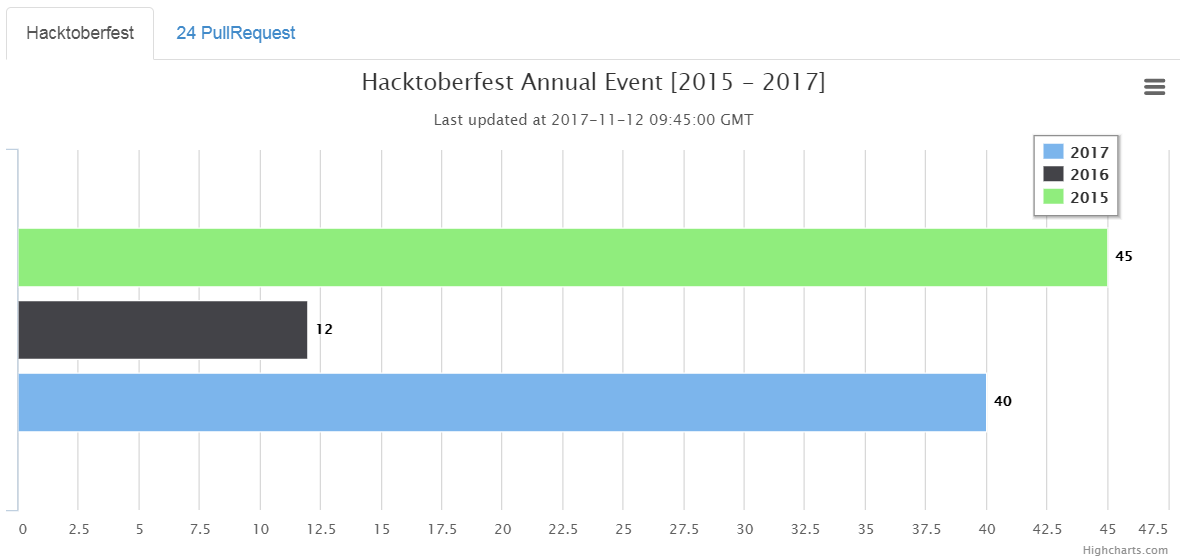
Took part in Hacktoberfest challenge, third consecutive years, and submitted 40 PR. Recently received the specially designed T-shirt, Thanks Digital Ocean.
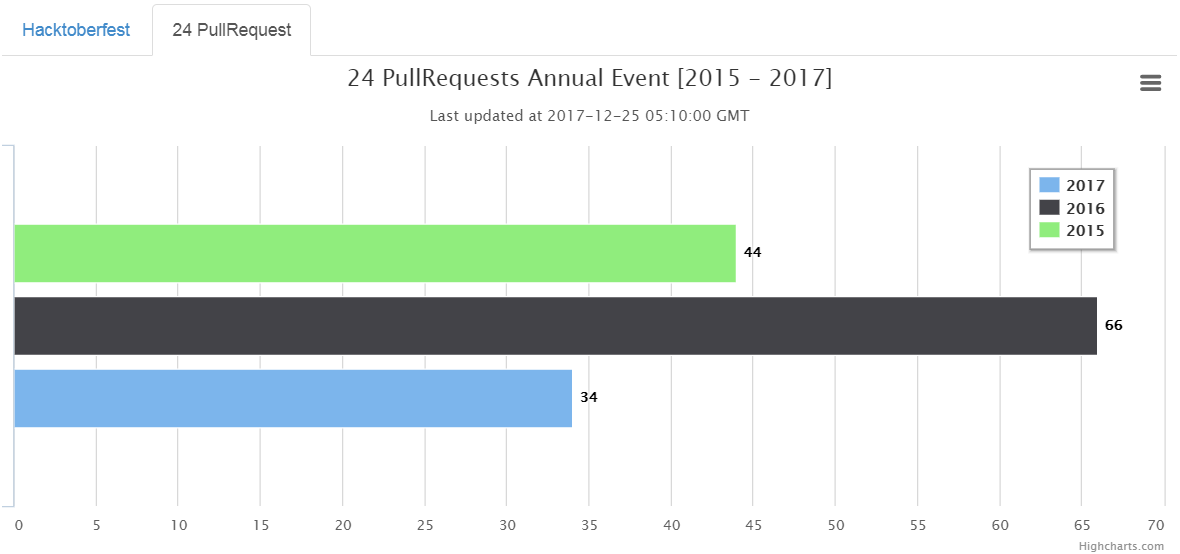
I also completed 24PullRequest, again third consecutive years, and submitted 34 PR.
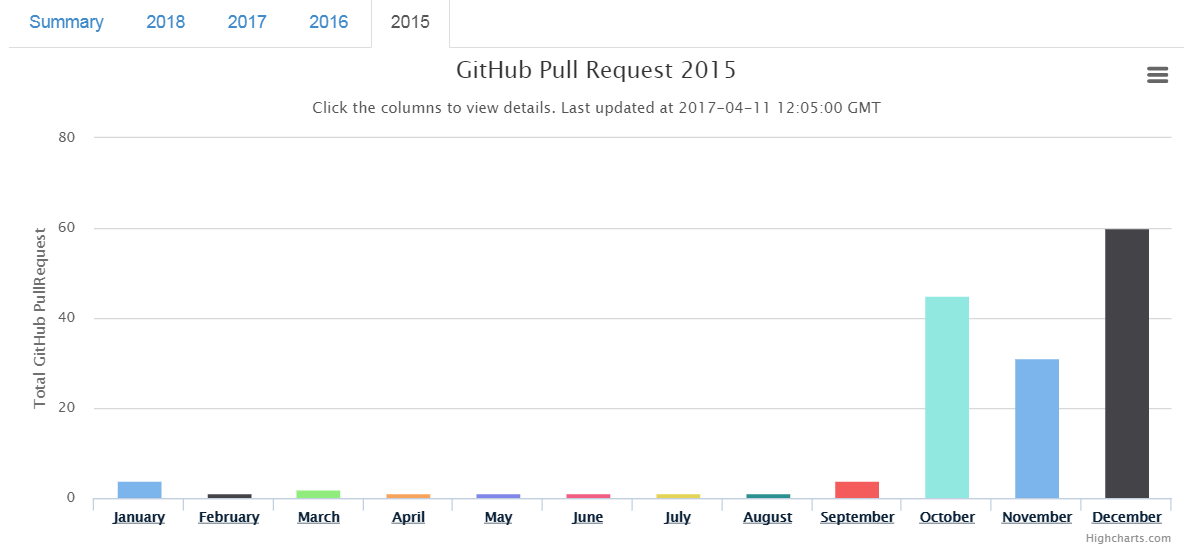
On the same line, submitting PR, I planned to do at least 1 PR each day on average most of the months in the year. Before year 2017, I was able to do that in 3 months at the most (in the year 2015).