Learning XS - Prototyping
Over the past year, I’ve been self-studying XS and have now decided to share my learning journey through a series of blog posts. This fifth post introduces you to subroutine(method/function) prototypes in XS.
Over the past year, I’ve been self-studying XS and have now decided to share my learning journey through a series of blog posts. This fifth post introduces you to subroutine(method/function) prototypes in XS.
All three of us attended.
readline and the filehandle error flag once again, starting over by revisiting the basic premise of the error flag. We think we now have a better understanding the overall situation, and this led us to a different approach about how to correct the overall situation, which we will outline as a proposal soon.readline situation.
Playing with AWS S3 using LocalStack platform.
Please check out the link below for more information.
https://theweeklychallenge.org/blog/localstack-aws-s3
Many thanx to Shawn Laffan for testing this version on Strawberry Perl.
I test it on my Debian machine first of course.
It took Shawn and myself a number of attempts to make all the test pass under the 2 types of OSes.
Over the past year, I’ve been self-studying XS and have now decided to share my learning journey through a series of blog posts. This fourth post introduces you to overloading operators in XS.
We were all present.
CVE-2024-56406 is published and has been addressed by new point releases. Please upgrade or patch your perl promptly if affected. We thank Steve Hay, Andreas König and Stig Palmquist for doing the heavy lifting, as well as Nathan Mills for discovering the problem, and Karl Williams for providing the fix. We re-/learned a number of old and new lessons about the handling of security issues, which we will write up as new process for the PSC, the Perl Security Team, and the CPANSec group, to be jointly reviewed and agreed at the looming PTS.
We started winnowing this release cycle’s pull requests for potential release blockers. We briefly reviewed all 72 pull requests and identified 11 of interest for a closer look.
We reviewed the 2 new issues filed since last week for release blocker potential and put one of them on our list for closer review. We then started a closer examination of the 20 issues we identified as candidate blockers. We got through 5 issues, none of which we considered blockers.

Couple of experimental features added to Map::Tube.
Please check out the link below for more information.
https://theweeklychallenge.org/blog/map-tube-experimental
One of my pleasures in perl is learning the C language again. Something about the perl language makes it easier to write C, but while sharing the same space in my brain.
So how can I write a trivial program to write exactly one GB (2^30) of data to disk?
first in perl- (Of course you prototype in perl!)
But since my c program is cleaner, here’s the C program
Over the past year, I’ve been self-studying XS and have now decided to share my learning journey through a series of blog posts. This third post introduces you to list context in XS.
Lots has been going on. All of us showed up, though Aristotle had to join late and Philippe had to leave early, so the meeting was short but productive:
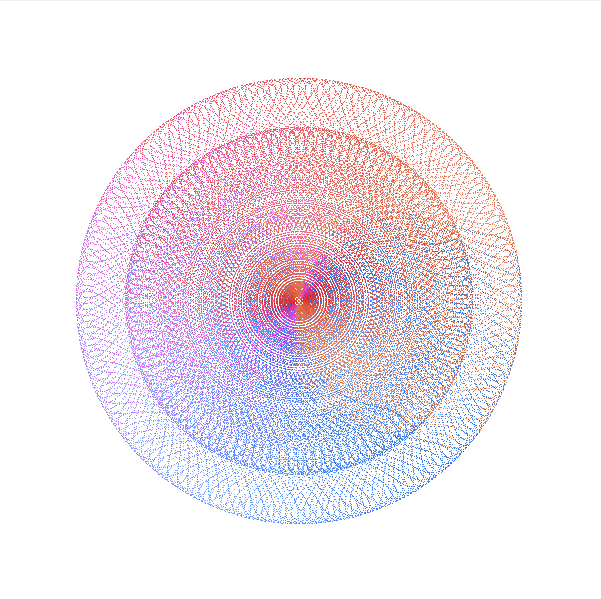
With the Harmonograph you can create beautiful and individual images within a few clicks. It's painting by pendulum. I already gave here an introduction. So let me just explain what is new:
My home page gives you access to:
o Perl TiddlyWiki V 1.25
o Mojolicious TiddlyWiki V 1.03
o Debian TiddlyWiki V 1.07
o Some other stuff...
Over the past year, I’ve been self-studying XS and have now decided to share my learning journey through a series of blog posts. This second post introduces the fundamentals of type checking variables in XS.
We were all present.
indirect and multidimensional: it’s a mistake we made that will remain part of older language versions but will not be included in future feature bundles.What's new?
An introduction to newbie in Perl.
Please checkout the post for more information:
https://theweeklychallenge.org/blog/welcome-to-perl
So, what exactly is a Readonly variable in Perl? A readonly variable is one that, once assigned a value, cannot be changed. Any attempt to modify it will trigger a runtime error. This mechanism enforces immutability, ensuring that critical values remain untouched and are protected from accidental or unauthorised alterations.
A meeting with full attendance.
readline again at length. We concluded that we are not yet sure about the big across-the-board change to I/O functions, and are definitely too far into the release cycle to undertake a fishing expedition. But we don’t want to leave this problem entirely unaddressed during this cycle, and the change proposed by Tony Cook is a strict improvement, even if only a minimal one. So we decided to ship it, possibly with a slightly different implementation that we may suggest.I started using DEV at the suggestion of Perl Weekly, and I was quite pleased with it - until I discovered that links to dev.to are effectively "shadowbanned" on several major platforms (Reddit, Hacker News, etc.). Posts containing DEV URLs would simply not be shown to users, making it impossible to share content effectively.
To work around this, I thought I would need a way to publish my DEV articles on my own domain so I could freely share them. There are some DEV tutorials out there that explain how to consume the API using frontend frameworks like React, however I don't enjoy frontend at all and I did not want to spend much time on that.
My solution was to get a simple Perl script that builds static versions of the articles, along with an index page. A Perl 5 script will run anywhere, including an old shared linux hosting account I still keep on IONOS, and I really like the speed of static sites.

Re-creating CVE-2024-56406 using docker container with affected Perl versions.
Please check out the link below for more information.
https://theweeklychallenge.org/blog/cve-2024-56406
blogs.perl.org is a common blogging platform for the Perl community. Written in Perl with a graphic design donated by Six Apart, Ltd.