Well leaving off from my last post I was a little frustrated with Moose but not as much as our Moose friend below.
So after a good night of sleep and a large pot of coffee I stumbled on a Moose solution.
Seems some-one else must of had the same problem, some time before my entry into the Moose space, and a quick search of the MooseX namespace and I found 'MooseX::Role::BuildInstanceOf'* which looked to be what I wanted. So here we go
Well in my creator class I started from scratch again with
I don't think syntax has much to do with readability. Joel Berger posted his thought on a Perl versus Python matchup, but I think that falls into the same trap that most of these arguments do. If we're stuck at the level of syntax, we're really not very good programmers. I don't think any of us choose a language based on the syntax, but that's all we seem to fight about in the comparisons.
I can't go into the full background and a couple of details have been changed to protect the innocent, but I was chatting with a company that I'll call Acme. They faced a situation that I've seen before and usually ends badly. The code base they have looks like this:
Roughly a million lines of legacy spaghetti code
Very little use of existing libraries ("not invented here" syndrome)
Siloed developers
Hard to maintain and extend
Prospective developers see the code and "nope" the heck out of there
I have spoken to quite a few companies in this mess and Acme had a solution for dealing with it: they were going to rewrite the code base in another language.
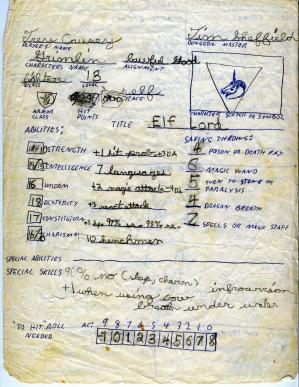
In my last post I attempted to use 'Class' as roles to weed out Grot characters that can never be used in the game as a PC. In the end I took the advice found in JT Smith's recent post and abandoned that idea.
While I want my program to be flexible enough to allow new races and classes to be added easily. What I do know that there will always be just six 'Ability' rolls, so why not just use them.
I will have to change a number of things in my 'Creator' class as I will drop my 6 Abilities them as simple Int 'Attributes' and I will try to use a class for each that has a 'roll' attribute for the values and on the 'BUILD' of each of these new classes I can see if the present score qualifies in one of the 'Character Classes' as that is all I really need to know.
It is known that one can label loops (or arbitrary blocks) in Perl 5, using
the syntax of MYLABEL: while (COND()) { BLOCK }
or MYLABEL: for my $x (@array) { BLOCK } and then one can
do last MYLABEL;, next MYLABEL;, or
redo MYLABEL; (for more information see
perldoc perlsyn).
However, I was unable to find how to do something
like that in Perl 6, despite some amount of searching. Luckily, the people
on the Perl 6 helped me.
The answer is that in Perl 6, it's essentially not different:
In a recent post, our own Buddy Burden expounds on the relative merits of readability vs flexibility (in the guise of Python vs Perl respectively). While he does not completely concede the point that Python is more readable than Perl, I will go so far as to negate it. In fact, I would say that the prettiness of Python can even mask some real readability issues.
I have been a Perl programmer for several years, but early this summer took a job writing Python. I’m glad I’ve learned it, there are several things that I would love to see added to Perl, most notably a set type and a proper in operator (~~ got close). That said I will absolutely not concede that Python is easier to read than Perl, as all too often is taken as the axiom that many believe it is.
In my last post I used 'Moose::Util::TypeConstraints' to limit my ability scores to a range between 3~18 now onto the next little test for Moose.
The next rule I want to enforce is, if the passed in ability scores are a Grot Character, (one that can never have a class as all the scores are too low) then I want an error to be thrown.
I could of course just add in a bunch of 'if' or 'given' s in the 'BUILD' or 'around BUILDARGS' but that is not a very elegant solution and as 'Race' is chosen before 'Class' I may have to apply these rules more than once as a 'Demi-Human Character' abilities are adjusted which may preclude a 'Class' as well.
Test::Class::Moose version 0.40 has been uploaded to the CPAN. Or you can get it now on github. It's a major improvement in many ways, including the fact that parallel testing is now in main branch and it works much better! Read on for the changes.
This is part 6 of an ongoing series where I explore my relationship with Perl. You may wish to begin at the beginning.
This week we look at the question of creativity in programming.
Last week I talked about how the linguistics baked into Perl allow for maximum programmer creativity. But of course all that discussion contains a hidden premise: that allowing for programmer creativity is something desireable. But is it really? Maybe programmer creativity isn’t that great an idea.
This week I received some special help on SO in understanding how the goatse operator works. I was very thankful for everyone's help. Thesetwo articles were also very helpful and I recommend reading them.
Part of my confusion over the goatse operator was not knowing the difference between list and scalar assignment operators, which both are indicated via '='. Further confusing is the fact that each can be used in either scalar or list context, so you can have list assignment in scalar context or scalar assignment in list context.
The type of assignment is determined by what is being assigned to. As ikegami says, assignment to an aggregate is a list assignment, aggregate meaning an array, a hash, a parenthetical expression, or a my/our/local variable declared with parens.
In my last post I said I was going to look at my 'Character Creation' part of my application and since then I have been doing a little digging and I believe that Moose will help me out here.
So I thought I might just want only one of these for my app and looked at 'MooseX::Singleton' but with a round of sober second thought I dropped that idea. Seems if I did that then I will have only one 'Instance' about which is good for say my DB connection but not so good if I want more than 1 user creating character's at a time. But at least I did see how Moose will help me.
As my BPM model indicates there are at maximum only 3 choices that must be made in character creation.
Most git wrappers on CPAN (Git::Wrapper, Git::Class and Git::Sub offer methods (or functions) based on the existing git subcommands (usually limited to a subset of the porcelain commands). Git::Repository is different.
Having thoroughly examined how Moose roles work, finding a good workable solutions to any problems I encountered, spec-ed out my basic Namespace, captured 90% of the roles I will need to create and mapped out the character creation process now I have t decide on how to put all the bits and pieces together.
So far I have these three 'Application' blocks Identified.
Character Creation
Character Instantiation
Game Play
I didn't bother to mention persistence as that is an obvious one but as seen below easy to implement.
So my dilemma now is to choose an appropriate design for the 'Application' as a whole.
From my diagram from an earlier post on character creation indicates that a simple Procedural style. The user starts with a set of dice rolls for abilities and is then presented with choices until a character comes out the end and is either persisted or dropped.
This post announces the release of Mojolicious::Command::nopaste, a clone of App::Nopaste using the Mojolicious toolkit.
I wrote it mostly as an example of using Mojolicious and its command system, but it has the side benefit of having a much lighter dependency chain than the venerable original (I already have the only required dependency on every box I use).
It also has a few bugfixes that the nopaste author either hasn’t tripped on, or had the time to fix (mostly in the Clipboard interaction on Linux) (sartak if you want to ping me I’d be happy to work with you on it). It has a slightly different list of services, including the very fun MathB.in but lacking Gist for now since the OAuth is something I don’t want to deal with yet. Any other services that people are interested in may be contributed via a PR or even a decent api spec.
By default, Pinto is configured to use cpan.perl.org and backpan.perl.org as the upstream repositories. But since cpan.perl.org is currently offline, Pinto will throw an exception if you try to pull a module or distribution from upstream.
You can work around this by setting the sources key in the repository configuration file to cpan.stratopan.com. That site is a full mirror of both CPAN and BackPAN. The configuration file is located at .pinto/config/pinto.ini within the repository directory.