Fisher's Creek Consulting
My consulting business is now at Fisher's Creek Consulting, for anyone that is interested.
My consulting business is now at Fisher's Creek Consulting, for anyone that is interested.
For the last few months I have been porting Spreadsheet::WriteExcel to the new Excel 2007+ file format.
The older Excel file format was comprised of sequential binary records whilst the new file format is a collection of XML files in a zip container.
The newer module maintains the same API as Spreadsheet::WriteExcel but is in a different namespace. It is called Excel::Writer::XLSX.
Some of the test driven development aspects of writing Excel::Writer::XLSX have been interesting and I'd thought that I'd blog about them here.
At its simplest an Excel XLSX file contains the following elements:
This is the first O'Reilly video I downloaded. Technically this course has been recorded in optimal conditions. You won't be disturbed by noise nor bad images. O'Reilly did a great job at mixing the video with full-screen laptop screen and the room.
By downloading the course you'll get more than 5 hours of interesting course. The course is divided in well-organized chunks. Each chunk handles a specific item of git, which makes it great for later review.
I'd like to publicly thank Bram, the previous owner of http://yapc.eu/.
I asked if we could transfer it over to the Perl NOC team so that it becomes an official community resource (he was already redirecting it to the yapceurope.org domain).
He was more than happy to do so, and has been so helpful in the process.
At the same time I'd like to thank the Perl NOC guys for taking this on. You probably don't realise just how much infrastructure these two guys run on our behalf, and how much more they are taking on!
I'd also like to thank the ACT team who run most of the Perl conferences websites and have setup yapc.eu on their server.
http://yapc.eu/ - points to the http://www.yapceurope.org/ site.
http://yapc.eu/ year will redirect you to the relevant historical sites.Today, I found out about a new release of Image::Thumbnail , which has support for Image::Epeg , a library coming from the Enlightenment desktop manager. Likely, epeg is quite fast, but it didn't build and test right under Windows. Conveniently though, Tokuhiro Matsuno maintains the module on github, so it was just a matter of forking and cloning his repository, and then trying to find out what made it break.
The breakage itself was three parts:
-DBUILDING_DLL , which I supplied as a cc_optimize_flag through Module::Install, because I couldn't find a better way.binmode() was not used with the test image files. Easily fixed.These two tests made it into v0.11 , released about 30 minutes after I told tokuhirom about the patches.
The remaining problem was that a function call crashed Perl with
Free to wrong pool ... at ...
I think, after a load of floundering around, that the way to use DBIx::Class::DeploymentHandler has finally clicked - I have no idea why it seems to have been so hard for my mind to work out how to use it, but this module has really made my head hurt!
So, I am aiming to put together a few blog posts on using Deployment Handler to manage upgrades (and theoretically downgrades, but I have never tried those). I should get something produced around the end of next week (minor issues like stage managing a play in theatre all next week allowing!).
codepad is an online compiler/interpreter, and a simple collaboration tool. One can test code and share results. Currently, it supports 13 programming languages including Perl.
I've been writing and rewriting Nama[1,2,3] for several years now. It's been my introduction to intermediate concepts in computer science.
Nama is an audio recording, mixing and editing application, using Ecasound[4] as the audio engine.
I'm proud of how it has evolved. At first it was all procedural, driven by a command processor loop. Then I added a Tk-based GUI, my first GUI. I added a text interface with a command grammar based on Parse::RecDescent. I introduced OO to separate the code for two different UIs. Then I added classes for tracks, buses and other entities. I added an event system (actually two), serialization, a help system, tests. I created a build system to automatically generate parts of the grammar, the help system, and to merge various files. The code for audio routing has gone through three different design interations: hardcoding, routing by rules, and now, routing by creating and transforming a graph.
A new Mojolicious plugin has been released, Mojolicious::Plugin::ConsoleLogger.
By default, Mojolicious will send debug messages to a log/[mode].log file; if the log directory does not exist, messages will default to the terminal console.
You can use any of the four logging groups for customized messages:
With Mojolicious::Plugin::ConsoleLogger, you can log these same messages directly to your browser console.
Declare the plugin:
And view all your log messages directly from your browser:
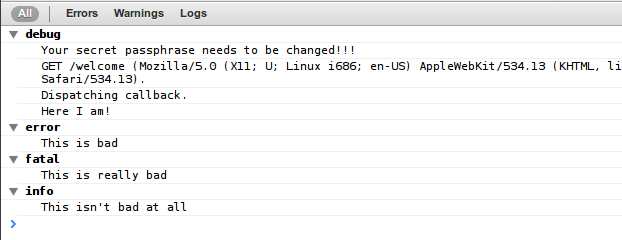
That's all well and good, but let's take it a step further. You can even see error messages when the template is missing:

Or when there's a template error:

Even when there's a Perl compilation error:

As always, Mojolicious installs in about a minute:
sudo -s 'curl -L cpanmin.us | perl - Mojolicious::Plugin::ConsoleLogger'
Disclaimer:
Implementation stolen from Plack::Middleware::ConsoleLogger
I had always wanted to perform some analysis on all the posts that Reddit gets. I searched CPAN for a module that does something similar, and found nothing. So, I decided to write my own. This is still a work in progress, and currently only allows you to fetch and parse the data in XML.
Please note that I have released Finance::QuoteDB 0.15 to CPAN.
Finance::QuoteDB is meant as a fullblown database application for
maintaining stock data. It allows anyone to easily create and update a
stock database. The information is gathered by using Finance::Quote
and the database is created and maintained by use of DBIx::Class.
The config-file for GeniusTrader use is generated automatically.
Interface to R is planned to be integrated.
Prompted by some comments about how to handle RAW files from cameras, I revisited App::imagestream , the program I use to automatically publish all images I touch to a gallery page on my website.
An experiment that I run with this program (and with App::fritzgrowl as well) is to specify the configuration information via POD. There is code in Config::Spec::FromPod and Config::Cascade that takes POD and turns it into a hash of hashes containing the configuration model. Then there is more code in App::ImageStream::Config to turn this model into a DSL for a config file, a parser for Getopt::Long or simply the defaults. Config::Cascade then fills out the values, starting with the most specific values coming from the command line, the less specific values coming from the config file and the least specific values coming from the application defaults, all driven by the documentation.
Does Perl run out of memory?
Today I got an email from someone saying “I was told by a person who used Perl for computational genomics applications that it was running out of memory, so he switched to C++. What’s your thoughts on running out of memory in Perl?”
Just for posterity here is my reply (please note I’m no expert on this sort of thing and have never had the problem) was…
Now that I have "almost" fixed the remaining compiler bugs, I wanted to use the existing framework to enable the possible speedup by using types, esp. low-level internal types. C-style integers and double scalars are used internally in B::CC instead of full Perl IV's / NV's if declared as such, and thus greatly improves execution speed. Esp. for inlinable arithmetic and comparison blocks.
Only at the end of such a block (and only when really needed) the calculated C vars are written back to the perl pad. So I needed better Opcodes flags to define which ops read or write pads, and more possible optimization hints. Most of these flags should be added to core later, when the time will come to speed up not only the B::CC compiler, but also the internal perl compiler.
I released perl 5.13.10 today. I might write more about that later. But one significant change in it is that Perl now has many more regex flags.
So I wrote a short one-off script to find out what words I cound construct from the flags.
Now it just gives you one word that contains as many of the flags as possible, and gives you the remainder. What would be more interesting would be to detect cases where multiple valid words can be made from the flags. E.g. "mix" and "uploads". It just detected that by accident.
I leave that as an exercise for the reader.
Ignited by comments on IRC and in the Israeli Perl Mongers mailing list, I've sat (for 10 minutes), wrote and published a new Plack middleware: Plack::Middleware::NoMultipleSlashes. Let me explain what it is.
Apparently you cannot count (by RFC, even) that the paths http://mysite/ and http://mysite// will lead to the same place. This is very tricky, because it means that the framework you're using (Dancer, right? :) shouldn't clean those multiple slashes for you.
So, I figured "why not let Plack take care of it?". I wrote Plack::Middleware::NoMultipleSlashes (a single line of code, really), that cleans those multiple slashes for you, wherever they are in the path.
To use it with Dancer, just add the following to your config.yml file:
plack_middlewares:
- [ NoMultipleSlashes ]
Done!
Thank you, Plack! :)
BTW, if you still haven't gotten around to reading Franck Cuny's latest post, it's right here (PSGIChrome).
Win32::Wlan has now escaped onto CPAN. I've redone the whole structure. There now is Win32::Wlan::API, which is a very thin layer over the Microsoft Wireless API. Win32::Wlan itself provides an object that handles the initialization and deinitialization of the API and provides convenient access to the first (and highly likely, only) wireless connection of the computer.
Now I have to write a convenient "snapshot" program to invoke to "mark" a place, and another program to recognize those wireless snapshots and to associate them with a location. When a location is then recognized, this could trigger scripts that configure other programs for the proper proxy settings.
A lot of work is currently underway to improve CPAN. One longstanding issue is the handing of external dependencies (the "libfoo" problem.) As I understand it, although CPAN distributions may test for external dependencies, existing build tools are unable to install non-perl libraries, header files or compilers.
Resources to solve these problems are available, but in places not usually considered by CPAN toolmakers. I'm referring to native OS package repositories. While natively packaged CPAN distributions necessarily lag current CPAN offerings, they meet non-perl as well as perl dependencies, and are generally troublefree to install.
To give the example I know best, Debian's perl repository covers roughly 10% of CPAN, including much of CPAN's best. This enormous investment in labor, toolchain development and community building results in high-quality packages that even new users can install easily.
As a developer of a perl audio application available for Debian, I've encountered problems managing dependencies when administering systems that mix distro and CPAN sources, even when using local::lib.
There is a lot of call for the ability to execute code at the end of runtime. An example of this is Moose when you call __PACKAGE__->make_immutable(). Wouldn’t it be nice if this were just automatic? Other places this can be useful are in testing frameworks such as Test::Class or Fennec. These testing frameworks use a ‘runner’ to run test structures defined in your tests.
Depending on your use-case for code that runs at the end of runtime, there are a couple possibilities. One possibility is to use an END block. Most people should know by now that END {} blocks are bad, simply read the perlmod section. There are just too many edge cases to account for, not to mention conflicting END blocks.
Caching is a tricky business. Having just one kind of cache won't work, because the production environment will greatly determine the most efficient caching system. A distributed production environment would be best-served with a distributed cache. A smaller, single-server environment could use a simple shared memory cache.
Enter Jonathan Swartz's CHI module, the greatest Perl module to provide a unified caching interface. CHI is the DBI of caching: It presents an API, and delegates to CHI::Driver modules to perform the heavy lifting. It provides a layered caching system, allowing you to have a faster, more volatile cache in front of a slower, more persistent cache. It also provides a variable expiration time, preventing a "miss stampede" where all processes try to recompute an expired cache item at the same time.
By integrating CHI cache into WebGUI, we have the ability to provide any caching strategy that CHI can provide. We get Memcached, FastMmap, and DBI drivers (and more drivers can be written).
blogs.perl.org is a common blogging platform for the Perl community. Written in Perl with a graphic design donated by Six Apart, Ltd.