On Monday we had our monthly meeting of Erlangen.pm. Because our usual establishement, the Trattoria Dolomiti, is closed for refurbishment we went to the restaurant Sofra. A nice turkish restaurant with lots of delicious mediterane food. There was a lot of road work outside of the restaurant so it took a while unless everyone of the seven attendencies arrived.
Sadly, one of our Mongers, gabimuc, is leaving the town. We all hope that she will find her way for the future. We hope that she will stick with Perl and that she will find a nice Perl Mongers group in her new home town. We want to thank her also for providing us with some appatisers that were allready close to a complete meal. For that I personally want to say to every Perl Monger, who couldn't make it to the meeting on monday: Ätschbätsch! ;-).
I wrote about speeding up Test::Class with subtests. That's worked extremely well for us, but it's raised an interesting problem: how can I filter subtests the way I can filter test methods? Explanation follows, suggestions welcome.
When considering whether to host a YAPC, potential organisers often have no idea what they are letting themselves in for. While it can be very rewarding, and a valuable experience, it is hard work. There are plenty of things to go wrong, and keeping on top of them can be quite daunting. However, when you first consider bidding you usually look to what's gone before, and over the past 10 years YAPC events have come on leaps and bounds. This year, YAPC::Europe in Pisa, Italy was no exception.
Since we've been porting CPAN to the iPhone via iCPAN, we've had the chance to re-imagine the CPAN a little bit. We've been thinking, what would we change about search.cpan.org if we were able? We've added the bookmarking, we save searches of recently viewed modules and now we've got syntax highlighting.
A lot of us see our code highlighted in our editors. That's how we're accustomed to viewing code. So why not view it that way in our module documentation? (Now, we're fully aware that this can be done with GreaseMonkey, but it would be nice to have this available for everyone without needing to use a special extension). A great example is perldoc.perl.org, which does have syntax highlighting, but it only (as far as I can tell) does so for core modules.
For a while there has been a problem in one of my modules - the tests for Postscript::TextDecode make use of Test::Most which it turned out most CPAN testers don't use by default. That's fair. It was on my list of things to fix, but never with high priority.
Shortly after YAPC::EU::2010 I received a RT request from Andreas Koenig alerting me to the issue. At YAPC I had heard about this utility called Dist::Zilla which was supposed to make the managing of distributions a lot easier.
Off to CPAN. D::Z took a while to install but the install itself had no problems. I started reading the CPAN page and read Dist::Zilla::Tutorial. Since this was however limited, I directed my attention to the tutorial on dzil.org.
This tutorial has the style of a 'make your own adventure' children's book which was amusing. I found out that I could either start anew or switch my current distrubution over.
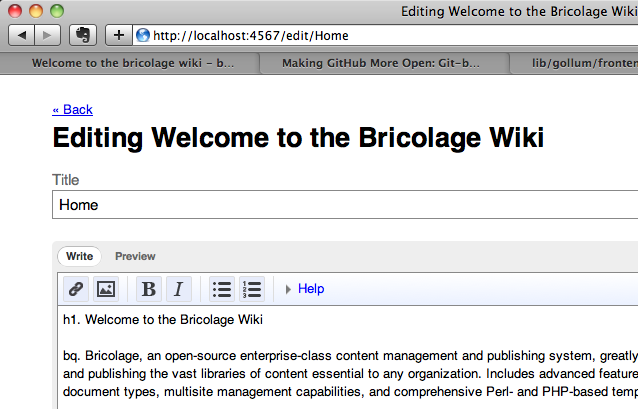
Last night I upgraded the Bricolage wiki on Github to the new git-backed wiki that Github rolled out last week. May sound like a trivial thing and not worth a blog post, but it’s quite the opposite, actually — the changes are (almost) revolutionary.
The first really interesting thing about the upgrade is that all of a project’s wiki pages are now simple text files in their own git repository. Now I can update these pages anyway I like, in any one of several markup languages, including POD. On it’s own, that’s pretty useful — now I can clone a project’s wiki along with the project itself and submit changes back as I would any other changes via Git.
In reading some code I ran across the expression s/^\s*|\s*$//g
which is a trim function. It is not the optimal way to write this. The
optimal way is two simpler expressions: s/^\s+//;
s/\s+$//. Justification follows.
Conclusion:
Use of + instead of * means regexps that will would do no
effective work will also fail to match. Failing to match when the
work would be useless yielded some 3x to 4x improvement.
Use of multiple simpler patterns like s/^...//;s/...$// instead of
compound patterns like s/^...|...$//g enabled boundary checking
optimizations.
This year, YAPC::Europe was reasonably well attended, with roughly 240 people. However, a few weeks prior to the event, the officially registered attendees for YAPC::Europe 2010 was considerably lower. Although every year it seems that many register in the last 2 weeks, there is usually a higher number registered before then. So why did we have such low numbers registering, until just before the conference this year? I'm sure there are several factors involved, but 2 strike me as significant.
Last month I wrote a post about Rakudo being ready for release. I ported a substantial framework from Perl 5 to Perl 6, and it just works. Surely, but sloooooowly!
I'd like to make the case that Rakudo is now ready for something else... A serious performance boost!
Git allows you to define a custom
hunk-header
which'll be used by git diff as the context line in diff
hunks. Git includes presets for several
languages
but no presets for Perl and Perl 6. I'd like to change that.
If you have no idea what these are, consider a file that contains
this code:
In Perl we can run user defined code blocks at different stages when running a program.
BEGIN blocks are run as soon as Perl finds them. If there is more than one block they get executed in the order they are found.
CHECK blocks are run as soon as Perl finishes compiling. If there is more than one CHECK block they get executed in the reverse order they are found.
INIT blocks are executed after CHECK blocks, and if more than one exists they get executed in the order they appear.
END blocks get executed before the program finishs running, and no errors where found. If more than one END block is found they are executed in the reverse order they appear.
So I wanted to install Dist::Zilla and give it try so I fired up the cpan client. A few of the tests failed in a dependency, Config::INI: http://www.nntp.perl.org/group/perl.cpan.testers/2010/08/msg7663252.html.
When I saw the failure, I traced it back to File::Temp::tempfile. I filled a bug report (https://rt.cpan.org/Ticket/Display.html?id=60340). Tim Jenness was quick to follow up on the bug and suggest that I try testing File::Spec::Win32 to see what it said with -T. (You'll see the results in the bug report previously mentioned.)
File::Spec::Win32 tries to use some weird paths that typically don't exist on Windows systems. Yes, C:\TEMP may or may not depending on number of variables such as version of Windows, what other software has been installed, etc.
The Perl activity on O'Reilly Answers has been a bit low, but with a little work, we can get it back up there along with the other topics on the front page.
And, unlike other sites, you can actually redeem the points you earn on O'Reilly Answers for valuable things like books and conference passes. Perl monger group leaders, speakers at O'Reilly events, and people in the book review blog program get starter points just for signing up.
Since plunging into the event-based programming world POE offers, I've been infatuated with combining the tests I've learned to write (Perl Testing Handbook FTW!), which proved to be a pesky task.
Writing tests was fun, writing POE was a bit difficult for me at first and combining them seemed close to impossible.
I started off by using MooseX::POE by (++Chris Prather) and it helped me instantaneously understand and write event-based code. However, with time I learned to separate Moose and POE (while still working with both at the same time) and have more control over the matter. Still, testing my event-based code looked like a far goal. It bugged me.
I set out to write a testing framework for this which dngor named POE::Test::Helpers. It used the power of Moose to provide your MooseX::POE-based event code with the ability to write rather complex tests in an almost-declarative manner.
I don't have the huge range of CPAN modules that some people are herding, so it may be thought that I don't need the substantial set of automation that others require to keep their interactions with PAUSE/CPAN under control.
However since I have to interact with PAUSE fairly rarely, as well as do the "pull everything together into a coherence CPAN release" dance infrequently, automating the whole process so I have fewer changes to get it wrong seems appealing.
I initially looked at Dist::Zilla a while back, but was having trouble getting my head round it properly. Although splitting the whole thing down into small plugins is great as a way of handling features, it can create problems when wanting to find out how to do things, or even finding out best practices, just because you have to locate the right plugin or plugin bundle from the huge selection. This isn't helped by the documentation - which appears to require some knowledge which I appear to be missing.
Perl 5.12 is alive and well. While Perl 6 is still on the horizon, ActiveState is using the in-between time to update its Perl Dev Kit (PDK) to version 9. Released on July 14, this new edition adds support for Perl 5.12, the most recent update to the language.
PDK 9 also supports HP-UX and 64-bit PerlNET (ActiveState's Perl component builder for the .NET Framework) for the first time.
Jeff Hobbs, director of engineering at ActiveState, said these new additions to PDK spread the appeal of Perl across all platforms. "In the latest PDK, we have updated the tools for full support of the new Perl 5.12 release," he said.