How do you start and daemonize your programs (PSGI apps, fastcgi apps, gearmand, several memcached instances, custom handcoded daemons)?
Do you write custom init scripts?
Use daemontools or upstart?
Do you simply invoke plackup in terminal? :)
Maybe you spawn your fcgi apps directly from your webserver?
Do you need watchdogs? Do you actually write them?
When I search CPAN, I frequently find it hard to tell which modules to choose. Unless my needs are very specialized, there can be lots of modules that do what I need. But how would I know which module is best to choose?
One factor that can help me decide is the number of CPAN dependents each module has. (Don't confuse "dependent" with "dependency"; I use the word "dependent" to mean: other modules that depend on it.) If a module has lots of other modules that depend on it, then I can be relatively certain that the module might be worth relying on.
The information about the modules' dependents is exposed by http://deps.cpantesters.org/depended-on-by.pl, which is rather cumbersome to use.
So, I created a greasemonkey script which dynamically shows the number of dependents for each module on the search.cpan.org search results. It then displays the list of distributions in order of their numbers of dependents.
For CPANPLUS users this just got a little bit easier.
Task::CPANPLUS::Metabase should make configuring CPANPLUS a lot easier. Simply install Task::CPANPLUS::Metabase, which will install all the necessary modules, then run the metabase_cpanp script to setup a Metabase ID file and configure CPANPLUS for sending test reports
I recently read a blog post by Alex Miller about Clojure multi-methods.
It described and answered a question his friend had asked him, as well as discussing some related problems. I'm going to showcase the different options Perl 6 provides for solving these same problems. Here's the initial question:
Is it possible to write a multimethod that has defmethods which handle ranges of values? For example, say that a person has an age. Can I write a multimethod that accepts a person as a parameter and returns "child" if age < 16, "adult" if 16 <= age < 66 and "senior" if age >= 66?
As in Clojure, the answer is "Sure." In keeping with TIMTOWDI, Perl 6 provides several ways to do this.
Like political views,
parsers are often divided into left and right.
Also like political views,
the left-right classification is more
hindrance than help in some cases.
Earley's algorithm (my main interest) is one
algorithm that does not fall into either category.
In this post I want to start to
talk about those parsers which can be neatly
classed as left or right.
First off, to say a parser is a left or right parser
does not describe
the direction in which the parser works.
The working direction of any parser
is always left-to-right,
except in the very rare cases that it is stated otherwise.
Every treatment of parsing theory I've seen follows this
convention.
Right-to-left parsing is useful sometimes in practice,
but the theory of right-to-left parsing
is simply a mirror image of the theory
for left-to-right parsing.
Uvar magic must die. Maybe it’s too late for a complete removal, but it’s use should at least be discouraged. One of the reasons is that it’s actually two very different things that don’t have all that much in common.
Scalar uvar magic
Scalar uvar magic isn’t actually evil, it’s just fairly useless. It’s a way to add get and set hooks to scalars. It may have been a useful interface back when it was introduced in 1993, but with the introduction of custom magic vtables in 5.8 it stopped particularly useful. The new interface is more powerful in many ways and in typical cases it that takes less code to use. There’s absolutely no reason why anyone should still be using scalar uvar magic unless you have to maintain compatibility with 5.6.
I try to encourage my students to join the Perl community as an aid of learning. I always stress that the community is such a learning benchmark, it is practically considered vital.
While showing a student how to work with Google Reader (since he already integrated much of his life into Gmail and the Google Calendar), I noticed something I overlooked before: you can specify search terms for subscription adding and it will search that through known RSS entries and let you pick which ones you want to subscribe to.
In Google Reading, click on "Add a subscription" and write down "Perl". Then you can skim through RSS feeds which have something to do with Perl. Some are websites that had an article on Perl (Wired, for example) and some are help forums (Experts Exchange - which I personally don't care for) but some are hardcore stuff like Ironman (one of the tops), blogs.perl.org, use.perl.org, etc.
I've added: PerlMonks, Reddit, RegexGuru.com, Ironman, Modern Perl Books, The Perl Foundation, Plack, Perlcast, freshmeat.net's Perl, Perl is Alive, Perlsphere, Tim Bunce's blog (just in case it's missing from any aggregator!) and Proud to Use Perl.
I asked Which Perl XML module should I use? on O'Reilly Answers to survey people about their XML module use, but my question was too general. Before you can recommend an XML module, you need to know what the task is.
I've refined the question into three more specific questions:
Maybe someone should start the same sort of questions for Perl web frameworks or any of the other topics that have multiple (hence, confusing) options.
I've been spending a bit of time this week looking at Pod enhancements for Dist::Zilla released modules, I have hit a bit of an impasse.
I quite like the [Availability] Pod::Weaver section plugin - Pod::Weaver::Section::Availability, however currently it hardwires some of the information to make it specific for the author (and unfortunately that means that the module name space is polluted by this). I'm just working out the best way to parameterise this information - although its a little tricky since really Pod::Weaver should work outside of Dist::Zilla, and the mechanisms I can see others using are grabbing information from Dist::Zilla for it...
Less controversial is the [BugsRT] module (Pod::Weaver::Section::BugsRT) which adds bug tracker information to the POD.
The two of these together should allow me to get released modules with pods how I like them.
In my recent post about promoting YAPCs, Gabor picked on something regarding the optimum number of attendees. I think he makes a good point that for a conference like a YAPC, 300-400 attendees is a good number to aim for. Anything more and it can become a logistical nightmare for organisers. It also means that the conferences themselves can become a little more impersonal, when a major aim of YAPCs is to bring people together.
0.12 Tue Aug 17 19:34:00 2010 PST
- New maintainer PHRED
- Thanks to Mark Stosberg for several patches for this version
- Die with an error string instead of carping and returning
- Skip tests in automated testing mode
- Skip tests unless user, pass, and sectoken environment vars set
- Fix failing test - base64binary => base64Binary namespace change
- Perltidy file contents and remove unnecessary package scope braces
- Handle undefined return values from SOAP client
- Fix Type => type doc error in create()
- Add describeSObjects method [tom@eborcom.com]
I blogged a small while back about converting Pod to ePub format for reading with iBooks or with other eBook readers.
The first release of App::Pod2Epub and pod2epub is now available on CPAN and GitHub and below are some screenshots.
This is a screenshot from an iPhone of four Perl eBooks along with some eBooks from the iBooks store. The Perl eBooks are displayed with the default cover image. User definable cover images will be enabled as soon as I have debugged it.
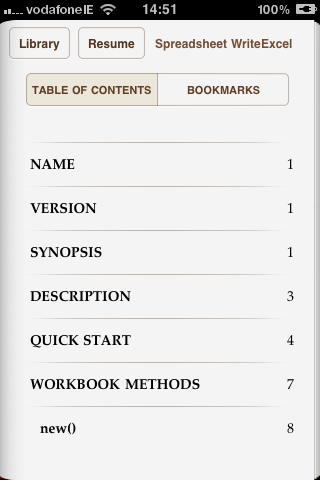
This image shows the table of contents for one of the eBooks showing chapters corresponding to Pod =head1 and =head2 levels.
Two book pages. The format of the text is configurable via user supplied CSS stylesheets. These images show the default pod2epub formatting.
I've been continually discouraged recently with various projects and endeavors. I've found that - while "stupid" is too strong of a word, "ignorant" should suffice - I will likely be unable to pursue certain paths while yielding positive results. "An intellectual FAIL," one might say.
It is not just in the realm of code, but well beyond it. I have a tendency for drama, I suppose, but it is still overwhelmingly clear that spreading oneself thin makes for... well, a rather thin layer. I've contemplated throwing the towel (and the water bottle, and the spit bucket, and half of the locker room) at my studies, my teaching and my projects and just hide under a rock, preferably with a lake-side view. Unfortunately there aren't a lot of lakes here.
If I would ever write a help book, I'd start it off with "Pace yourself." and end it there. That is clearly the most important lesson to teach, and the easiest for me to forget. However, does pacing actually relieve intellectual deficiencies? I'd like to see a test case that covers that, preferably in nice Devel::Cover colored HTML output.
The YAPC::Europe surveys have now been active for two weeks. In that time we've had received a total of 112 Conference Surveys submissions and 769 talk & course evaluations. Without a doubt this is a fantastic response already. However, in the past we've come close to a 70% reponse rate, and I'm hoping that in the remaining 2 weeks we can encourage another 56+ attendees to also respond.
If you haven't responded so far, please consider doing so, as it really does help to provide information for future organisers to make YAPCs better, and gives more weight to future attendees to persuade their bosses that YAPCs are a worthwhile and valuable event.
If you were an attendee, you should have received a mail containing your personal keycode login. If you haven't please check your spam filters first, but if still can't find a copy contact me directly (barbie [at] cpan.org). A further mail will be going out to those who have yet to complete the survey in a weeks time, as a final reminder. The official closing date of the surveys is Friday 3rd September.
Originally located at http://www.pphsg.org/cdsmith/types.html, this article explained some basic concepts of type systems. Unfortunately, that page is gone and I had to fetch it from the web archive of that page. The note at the bottom states that contents are in the public domain, so I think it's OK to reproduce here.
What follows is a short, brilliant introduction to the basic concepts of type systems, by Chris Smith.
Kephra is doing very well. Still 7 or 8 issues to be fixed till 0.5 plus some feature, but we will get there I think before the german perl-community workshop in Frankfurt. We now have 2 more edit tools, updated docs, links to the bug and wish tracker in help menu and lost of more tests. And 2 more localisations are under the way.
If your a Kephra user, please blog about it. Not that I can brag with it, but that mst will eventually mention it in the right places and the strawberry perl people see the necessity to include it into the PRO edition (not decided yet).
This is because the call to param is in list content. The bug is nasty because it often has security implications. The user can give multiple parameters to the web-script and then overwrite the parameters to the foo method.
This is an example:
$obj->foo( is_superuser =>0, name => $query->param("name") );
The user is able to call foo in superuser mode if he calls the script with the querystring
I have been so busy with other things, that I had forgotten to keep an eye on the Interesting Stats page of the CPAN Testers Statistics site recently. I knew it would be arriving soon after YAPC::Europe, but completely missed it.
Congratulations to Andreas for posting the 8 millionth report. It was a PASS for Convert-NLS_DATE_FORMAT-0.02.
We'll be having a group dinner for the August meeting, and have
a few drinks after for those interested. This will mostly
be a planning meeting for future meetings, but all are welcome
for Perl discussion and agreat food.
"Naan-N-Curry" at 336 O'Farrell Street, between Mason and Taylor.
This place has moved around a few times, and has many satellite
locations now, so look at that address carefully. This is across the
street from the Hilton, and next to the entrance to a large parking
garage.
From the Powell Street Bart station: walk two blocks north along Powell,
and 1.5 blocks west. Don't try to walk up Mason or Taylor, unless
you're in an adventurous mood.
The food is inexpensive, high quality Indian food. They have a buffet
these days, which makes things simpler. Free chai. The dining room
is double-sized, with large tables: there's no need to worry too much
about RSVPs.
Some weeks ago I posted a brain-dump that only got reaction like that looks interesting, but I have no idea what you’re talking about, so I’m going to try to explain what I was doing.
Since 5.10, perl supports uvar magic on hashes, though I called it magic hash key transformations because that gives at least tries to describe what it does. This was implemented to make fieldhashes possible. It’s an interface that does only one thing: when a hash element is accessed in any way the callback is called. The callback can’t change the semantics of the operation (unless it dies), all it can do is change the value of the key looked up. So it can transform $hash{A} into $hash{B}.
Nothing more, nothing less.
AFAIK, there are only 4 modules on CPAN that use it