Testing Insights from B::DeparseTree
rockyb’s recent post about B::DeparseTree contained several insights on testability and writing good tests. Here are my takeaways.
rockyb’s recent post about B::DeparseTree contained several insights on testability and writing good tests. Here are my takeaways.
Even more API fun day here in the Moose-Pen
When I left off yesterday I had everything working nicely but I was left with a little problem;
What should I do about the case of hash-keys returned from the DB?
Now in DBI I have three choices
while in most other NON SQL dbs I really do not have any choice. Though it seems in Mongo they always want you to use lower case for field names though you can used any case you want, while RethinkDB, at least when I used it some time ago, it only allowd lower case field names.
As part of my project to create a tutorial for XML::LibXML, I created an XPath Sandbox tool that allows you to try out different XPath expressions directly in your browser. I've recently enhanced that tool to add a couple of useful features:
When working with the built-in sample files, URL parameters can be used to: select a file, specify an XPath expression, override the default namespace prefix mappings. Here's an example link that does all three!
* I used the term upload in 'scare quotes' because it's a client-side app, nothing actually gets sent to the server.
In This Issue:
Get the TPC 2018 app by Infinity Interactive!
Volunteers Needed! Sign-up: http://bit.ly/tpcVolunteer
BoFs published http://bit.ly/TPCBoF
Lightning Talks registration available http://bit.ly/TPCLightningTalks
Conference schedule: http://bit.ly/TPCschedule
Sign up for a tutorial: http://bit.ly/TPCtutorials
Conference Tickets: http://bit.ly/TPCiSLC
Sponsor Spotlight: Grant Street Group
Become a sponsor
Stay in touch
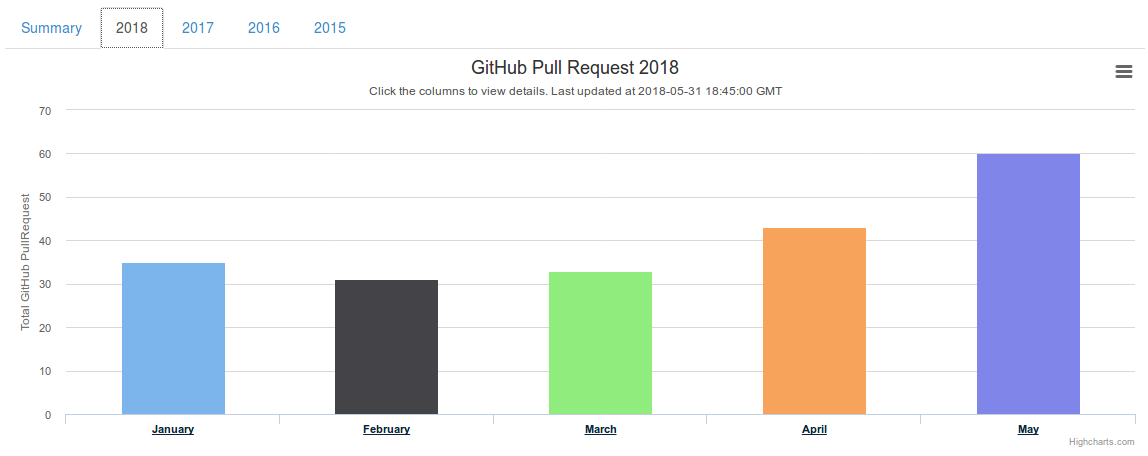
As we entered the sixth month of the year 2018. So what have I achieved in May 2018? In short, plenty. Let me share the details.
May 2018 has been the best month so far in the year 2018. In this month, I submitted 60 Pull Requests. Only two occasions in the past where I had better number than May 2018. It was 77 Pull Requests in December 2016 and 63 Pull Requests in January 2017.
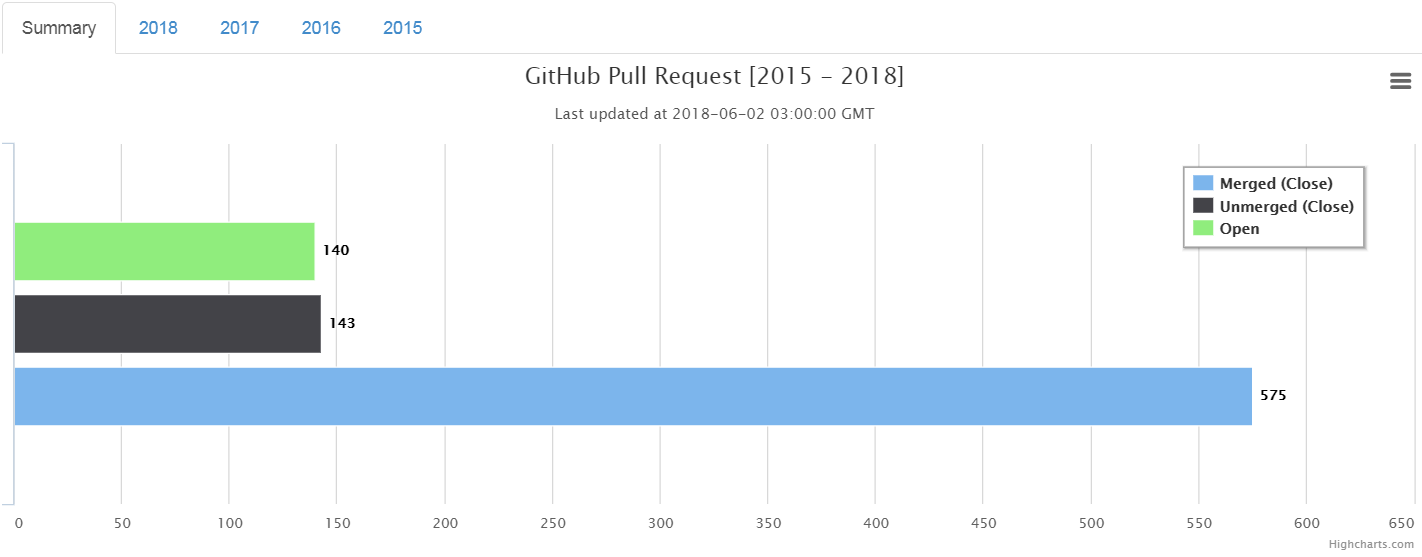
As of today, 2nd June 2018, I have submitted 858 Pull Requests. Of those 575 Pull Requests have been merged successfully. I am hoping to get to the magic number 1000 before the next London Perl Workshop, which is the 3rd Nov 2018. I am keeping my fingers crossed.
It still fix API day here in the Moose-pen
Yesterday I left off with a new attribute for may Database::Accessor and DAD, 'da_result_set' and I was just going to play with this in my Driver::DBI but before I go and do this I better change one test a little;
first I had this test near the end of my '20_dad_load.t' test case;
...
else {
my $dad = $da_new->result()->error;
ok($dad->is_ArrayRef ==1,"DAD is_ArrayRef is true")
}
I will be giving a talk on B::DeparseTree and its use in a debugger Devel::Trepan at the upcoming YAPC 2018
in Glasgow. As a result, I have been completely refactoring B::DeparseTree and have a number of thoughts on it and B::Deparse.
Here are some of them. This first part focuses more about B::Deparse and how it could be (or in a sense is) being rewritten. The second part if I get around to writing it will be about the cool features of B::DeparseTree from an application.
As someone who make a lot of mistakes, I’ve long wanted to improve the
precision of debugging and error reporting. Through Perlmonks, I was
directed upon the idea of using the OP address as means to get more
detailed information of where the program is. I was also pointed to
B::Deparse.
The first part of this series described Test Hierarchy, a hierarchy of test classes that mirrors the classes under test, and explained why it’s an antipattern. For how common it is, this practice doesn’t even produce good unit tests.
Perl::Build is a Perl Builder created by tokuhirom. You can build and install Perl by:
$ curl -L https://raw.githubusercontent.com/tokuhirom/Perl-Build/master/perl-build | perl - 5.26.2 /opt/perl-5.26/
Also, it is the backend of plenv-install:
$ git clone https://github.com/tokuhirom/Perl-Build.git $(plenv root)/plugins/perl-build
$ plenv install 5.26.2
Recently I became its maintainer, and have released a new version to CPAN. The new version contains the following changes:
#66, #67, #73, #74, #75, thanks Grinnz, anttilinno, djzort, sjn.
Now Perl::Build uses fastapi.metacpan.org to find available Perl versions and Perl tarball URLs. MetaCPAN indexer is quite fast. So, as soon as a new Perl is released, you should be able to install it by Perl::Build.
#72, thanks AnaTofuZ.
Its back to the API day here in the Moose-pen
As my practical tests against a real DB are humming along I noticed that I was missing some-thing quick basic on my API namely retrieving more that just a array-ref of data from the DB. Reading some of my earlier posts I did leave this part to latter so I better do it now before I get too close to my first release.
Now in the present Data::Accessor that Database::Accessor is based off of I noticed that I could pass in an optional $container on the 'retrieve' method and depending on the nature or the 'container' it would handle the results in different ways.
If it was not present that it just did as I do now return and array-ref of results. If a hash-ref was passed in then the the underlying DB would try to do a fetch for each key on the hash and the return an array-ref of hash-refs of the matched keys.
The newest entry on my Ocean of Awareness blog: "Is language just a set of strings?"
"The languages human beings use with each other are powerful, varied, flexible and endlessly retargetable. The parsers we use to communicate with computers are restrictive, repetitive in form, difficult to reprogram, and prohibitively hard to retarget. Is this because humans have a preternatural language ability?
"Or is there something wrong with the way we go about talking to computers? How the Theory of Parsing literature defines the term "language" may seem of only pedantic interest. But I will argue that it is a mistake which has everything to do with the limits of modern computer languages."
After TPC join me for The Hitch-Hiker's Guide to Perl 6 at The Little America in Salt Lake City.
It still expand Test day here in the Moose-Pen.
Carrying on with my extended 'xt' tests or as I like to call them practical test. I wanted to make sure that I can change the conditions on my Database::Accessor and and check that all the DB is correct in the 'person' table.
To accomplish this I added in the following;
$test_data = $user_db->people_data;
$da->reset_conditions();
$da->add_sort({name=>'id'});
$da->retrieve($dbh);
cmp_deeply( $da->result()->set, $test_data,
"All Persons result correct");
Today is GDPR Day, and to celebrate that, the PAUSE admins have added a Privacy Policy to PAUSE. This tells you:
The policy is linked off the sidebar in PAUSE, and the source is a markdown document in PAUSE's github repo.
Test::Class is particularly good at testing object-oriented code, or so it is said. You can create a hierarchy of test classes that mirrors the hierarchy of classes under test. But this pattern, common in Perl projects, is conspicuously missing from the rest of the xUnit world, and with good reason.
Quite some time back I was anxious to find a Perl module or two to work on and gain some experience in the process of releasing modules to the CPAN. Like I'm sure many of you do, I looked through the ADOPTME list to see what looked simple and or fun to work on.
WWW::Shorten and friends came on my radar and I started there. I reached out to the authors of many modules in the WWW::Shorten to see if they wouldn't mind joining me in the effort to bring them all to a similar point. I seem to recall everyone being happy and eager to work together, so this part went well. We created a GitHub organization to house the various modules.
Inevitably, though, I began working on other things and unfortunately have let WWW::Shorten and friends languish. This, however, opens the opportunity for you to take on the task of maintaining a family of modules and bring their test coverage up to date and add in modules for the new shortening services that are available now.
Please let me know if you're interested and I'll happily pass off some commit and PAUSE permissions!
Its Just a quick post-ette day here in the Moose-Pen
When we last met our hero she had gotten though most of the perils of the ever-changing API and the ever-increasing code base but found one other problem when working on the test in test case '10_crud_basic.t'
$da = $person->da();
$da->add_condition({
left => {
name => 'user_id',
},
right => { value => $new_person->{user_id }},
operator => '=',
});
$da->retrieve($dbh);
David Precious has just released a new trial version of Dancer. There are some rather significant changes under the hood, and community testing and feedback is welcomed and encouraged.
Please find us here, Github, Twitter, or on irc.perl.org#dancer with any questions, problems, or feedback.
Thanks! Keep dancing!
Simple desktop applications are generally not what one considers a Perl specialization. Its expertise lies in generating processing and transforming textual data, hence its use in the web, and in tools like GUIDeFATE. This 'duct tape' manages to parse text, extracting relevant data, and absorbing information and producing a meaningful output efficiently. Displaying this output in a desktop application shouldn't be too difficult.
blogs.perl.org is a common blogging platform for the Perl community. Written in Perl with a graphic design donated by Six Apart, Ltd.
{kind=link}