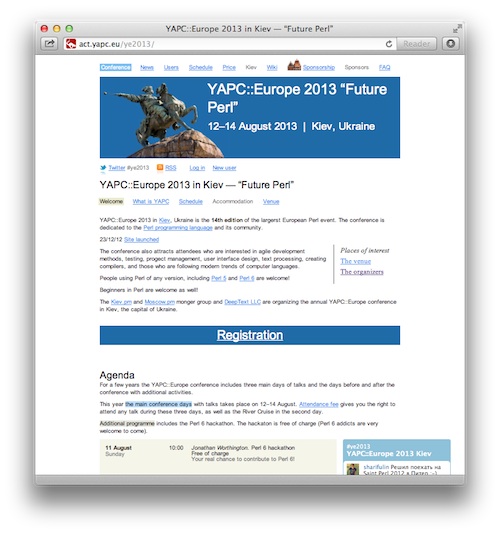
Dear YAPC::Europe attendees and those who would like to come to Kiev in August 2013,
We are very happy to announce the launch of the conference site: yapc.eu/2013.
Together with that, I am correcting the week countdown counter: there's no week minus 34, and the week -35 is followed by the week -33. The dates of the conference are 12-14 August 2013. There's a negligible small change that the dates will be changed, so we will make additional announcement when we are ready. It's Christmas and New Year time, that's why we have to wait a little bit more to be 100% sure. Vyacheslav vti and Anatoly sharifulin have just returned from Saint Petersburg where they attended the celebration of the 25th birthday of Perl, which is a good excuse :-)
A few days ago, I announced the release of Mojolicious::Plugin::ModuleBuild. After some thinking I realized that without much (any?) changes it would work more generally, even with the ExtUtils::MakeMaker toolchain. Therefore I am now announcing the availability of Mojolicious::Plugin::InstallablePaths.
The general concept is that Mojolicious applications assume a certain directory structure for use locally. To make a CPAN-installable distribution out of that application one must move some directories. Further, if packaging using Module::Build, even more changes had to be applied.
Mojolicious::Plugin::InstallablePaths allows a consistent usage in all phases of development and with either build tool (EUMM or Module::Build). Hopefully this helps encourage people to think of their Mojolicious apps as candidates for CPAN and makes it easier for them to share them with the world that way!
The old module will be marked for deletion and the old blog entry will be removed as well, so don’t try to use it, its going away.
GitHub now holds a pmtools Git repository. Since I have some time right now to attend to pmtools (and other personal programming), I thought it would make my life easier to move my pmtools development into Git while making pmtools development more collaborative.
(Yes, I will accept pull requests, but I reserve the right to review all changes before making a formal release.)
I generally have no problem understanding what's in a CPAN distribution and why, but lately (for years, now), it seems that tools are building files that I don't know about. Is there a canonical place to find information about what absolutely, definitely needs to be in a CPAN distribution? I generally rely on my tools to do this stuff for me, but honestly, what's META.json, MYMETA.json, META.yml,MYMETEA.yaml? And then I wind up with files like MANIFEST.bak and MANIFEST.SKIP.bak and I honestly don't know the format of many of these files, why they're duplicated or where to look up this information. Which of these files should I commit to source control and which of these files should git ignore?
It's an embarrassment because honestly, I should know this stuff, but I don't. Surely there's a place where I can find all of this explained at once, perhaps in conjunction with a description of the files in my .cpan, .cpanm directories?
Most of you love programming and shut ears when its only starts to buzzing anywhere but please hold on, its for a good cause and maybe even you might benefit from it.
Assuming someone would like to help with Windows, how could he generate a list of modules that are especially problematic on Windows?
Is there a way to fetch all the distributions that have no successful test reports on Windows?
Is there a way to create the ratio of (failed test reports)/(all test reports) on MSWin32 for each distribution, and then show the top 100 of that list?
Tomorrow is the 25th birthday of Perl. The Perl programming language.
When I've first heard about it, it was named PERL, the spelling that now is a nice indicator of awareness in the row with Perl and perl. Honestly, I never thought of Perl as of a practical extracting and reporting language, I simply had no clue about which reports and which extractions were mentioned in that definition.
I have first seen the name of the language on the book covers in a book shop in my home town years ago. I cannot tell you when exactly, but it was definitely before 1998. At that time it was only something related to web and programming for me.
Perl is not my first programming language. The first one was C++ (with ++ from the start), and I still find it one of the best languages and tend to use it as soon as there's a small need.
OK, so I decided to hack in support for submitting CPAN testers reports into cpanminus. I've uploaded the result to CPAN in case anybody else wants to use it. After CPANPLUS and cpanminus, the logical name for it was cpantimes.
As a Perl programmer on Windows, I've often had moments of supreme frustration. I can't use SSH or SFTP from Perl, and I can't use some of the mail handling modules. When I got started back in the early years of the century, I couldn't even use CPAN; I had to compile my own Perl and accept the fact that tests just mostly had no chance of working. Over the past year or two, however, especially as I've come to rely on CPANtesters for my own modules, I've started to realize that one reason for this is the lack of dense testing of modules on Windows. (Yeah, Paul Evans had something to do with that realization, too.)
But then Gábor Szabó posted on Google+ that he hoped to make it to #20 on the Windows smoke tester leaderboard. (As of today, he's at #19 - congrats!)
A few times every month someone asks me how is it to work at booking.com. People know that I worked there some time ago and they tend to gather more information about the company in which they are going to be interviewed for a position of a developer.
The dates before the 21 December 2012 are the best ones to stop thinking about the company where I spent 1.5 years. Although both booking.com and I are strongly related to the Perl programming language and its community, the text below the cut-line is not about any technical issue in Perl, but is about the way booking.com stops the contracts with their employees. I intentionally use the feature of MovableType that allows splitting the abstract and the body. So, please do not read further if you don't want to read things that are there.
In this article, we'll develop a basic search application using Dancer and
Sphinx. Sphinx is an open source search engine
that's fairly easy to use, but powerful enough to be deployed in high-traffic
sites, such as Craigslist and Dailymotion.
In keeping with this year's Dancer Advent Calendar trend, the example app will
be built on Dancer 2, but it should work just as well with Dancer 1.
This week I didn't fix the countdown week counter but I think I will do it next time. This week Viacheslav (vti) was negotiating the contract with the venue, and I am happy to tell you that he managed to save a few thousand euros by reorganising the room configuration that was initially proposed. We did not lose any space, and we still have the big and nice concert hall, so no worries. Huge thanks to vti! We hope to sign the contract next week.
It is very likely that we will have no extra paid classes around the conference. But still, if you are reading this and would like to give a class, please contact us.