I used to worry, now, not so much. Here is my journey to less stress and worry.
Sometimes programmers have to develop applications for production environments that are less than ideal. By less than ideal I mean things like having a Perl version that was End of Life (EOL) December 16 2008, I am looking at you RHEL/CentOS 5.x. Add to that not being able to install CPAN modules or make other changes to the system. The setup I just described is far too common for developers (think shared hosting) and it is frustrating every time you run into it.
Getopt::Long has a Configure() function to let you customize its parsing behaviour, e.g. whether or not to be case-sensitive, whether or not unknown options are passed unmodified or generate an error, etc. However, this customization is global: it affects every piece of code using Getopt::Long.
Since I use Getopt::Long in a utility module, which might conflict with the module user using Getopt::Long along with my module, I need to localize my Configure() effect. I was about to submit an RT wishlist ticket pertaining to this, but some quick checking revealed that Configure() already has this feature.
Configure() returns an arrayref containing all the current options. If you pass this arrayref to it, it will set all the options. This way, you can save and restore options.
Thanks to the Getopt::Long author, Johan Vromans, who apparently has maintained this module since 1990!
Having spent many years working jobs that involved no Perl programming I felt I was getting rusty so I re-read "Perl Best Practices". It is 2011 now, I should checkout what new things have developed in the Perl world. I was pointed towards Task::Kensho .
Task::Kensho is a glimpse at an enlightened Perl. After reading that I decide to see what it could do for me right now.
I was writing a script and I need to slurp a few files. Under Task::Kensho::Hackery I see "IO:All combines all of the best Perl IO modules into a single nifty object oriented interface to greatly simplify your everyday Perl IO idioms." With boasting like that I expected a fast and simple solution. I was not disappointed.
use warnings;
use strict;
use IO::All qw(slurp);
my @rcfile = io('rcfile')->slurp;
my @delta_data = io('delta_data')->slurp;
my @log_data = io('log-488')->slurp;
That little work and I was on my way to getting things done. I look forward to seeing what else Task::Kensho can help me with.
I plan on discontinuing support for Firefox 3.0 due to moving to the native JSON encoder that exists starting with Firefox 3.5.
If you are a Firefox 3.0 user (for compatibility testing?), and really, /really/ need the support, please talk to me so that we can work on a solution that keeps the code small and maintainable for me. If nobody speaks up, I'll interpret that as nobody using Firefox 3.0 anymore, which is fine by me as well.
In other news, I now got several "portable" Firefox instances installed and modified the test files to test against all installed instances. This now tests Firefox versions 3.5, 4.0, 5.0 and 6.0 Beta.
Just after Sawyer X gave a quick review on my chapter 2, on Modern OO programming, I am making the second chapter PDF file available on the book website.
Before leaving you reading the document, I would like to make it clear that i really want to make this chapter this way, presenting first Moo, then Mouse, and finally Moose. I know that the order is not cronological. It is just the order of presenting, each time, a more complex module. I didn't know Moo, Mouse or Moose. I had to learn them all from scratch, and I did it in this order. And I liked it.
Other than that, please, comment and suggest any correction you find relevant.
Gisle split out HTTPS support from libwww-perl into LWP::Protocol::https earlier this year when I wasn't paying attention. I needed HTTPS support for one of my Perl 5.14 applications and I wasn't reading the error message closely because I assumed it was business as usual with Crypt::SSLeay. Previously, I just installed that module and everything worked. Now I have to install LWP::Protocol::https to get everything to work. If I haven't done that, I get the error:
501 Protocol scheme 'https' is not supported (LWP::Protocol::https not installed) <URL:https://www.example.com>
That's not the end of the story though, because the fancy new stuff is a bit more strict with the SSL stuff. For libwww-perl-5.837 and earlier, hostname checking was off by default. Now it's on by default. I can't just connect to any HTTPS server. By default, LWP::UserAgent wants to verify the certificates and so on. That can be a problem if the Certificate Authority root certificate isn't around:
I've moved all my code to Github, including cpXXXan and CPANdeps. I also split the monolithic repo that used to contain all my perl modules into 41 separate repos, one per distribution, using a recipe provided by Paul Johnson.
Not sure how likely I am to actually succeed in giving regular updates, but I'm going to give it a go... Here is a synopsis of perlish things I’ve been working on in the past week.
The Perl Foundation (Treasurer)
Trying to track down some old contractual agreements to straighten out some payment details.
We’ve got some unfinished infrastructure refinement that needs to get done. (more details later)
Trying to close out all the details from YAPC this year. At this point, I’m comfortable saying it certainly ended in the black, though I don’t have the final number yet.
All checks that I received at YAPC were mailed to the bank weeks ago (I swear!). But I got a report just yesterday that some of them possibly didn’t get processed. I’m investigating that.
Up to date on all payment requests.
Working on a Q1, Q2 financial statement for the board. Have to get some issues worked out with our bookkeeper.
Nearly finished with the 2010 tax return.
Pittsburgh Perl Workshop (Organizer)
We’re starting to announce talks for PPW. But we still need more proposals. Please send in more talks!
MJD is coming to PPW!
No word on Damian yet.
The Perl Ops track is going to be a really big deal. Trying to get the word out any way we can.
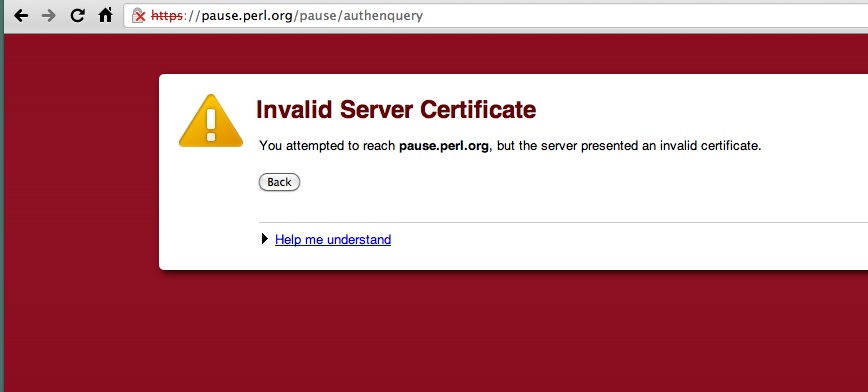
Went to ship a new module today but Google Chrome wouldn't let me visit PAUSE
Firefox indicates that the cert is from an untrusted issuer, but allows me through after adding an exception. 'Error code: sec_error_untrusted_issuer'. This is disappointing that the Chrome developers could not match Firefox in this regard. I'm hoping that it is just a missing use case rather than a planned feature.
But alas, the PAUSE ssl certificate is still self signed signed by CACert. PAUSE admins, if you are reading this, I will buy you a signed ssl cert for pause.cpan.org. Comment on this blog post to get a hold of me, or email me on my PHRED cpan page email address. I know you guys have lot of stuff going on, but hit me up and I'll cover this part of it.
Edward Tufte's "Slopegraphs" look like an interesting addition to the chart-maker's toolkit (and we all have had to create charts at one time or another).
For some reason Dancer was able to attract a few trolls (though we only suspect it's 2-3 people overall). Those 2-3 people have been trying to destroy Dancer and its community by flooding our IRC channel, writing plenty of disgusting remarks on Reddit, HackerNews, Twitter and recently by flooding our CPANRatings page.
Unfortunately none of this worked and the community had only flourished thanks to both hardcore Perl devs and beginner users who came out of the woodwork of dark Perl web programming into the funhouse that is Dancer and its community.
We've had a lot of awesome contributors, a lot of great feedback (some was "you're just awesome", some "you're missing this or that" - which were both very helpful!) and we've seen more and more users coming out, talking to us about how much they enjoy Dancer and how we could improve it and even lending a hand in everything from code, documentation to even helping other community members. It is really really inspiring.
The Portuguese Perl Workshop is back. This year's event will be held in the 22nd and 23rd of September in sunny Lisbon, where the grass is green and the girls are pretty.
Recently I put up some apps for YAPC::Asia 2011 online. <plug>Yes, YAPC::Asia Tokyo 2011 is happening, and it's on Oct 13-15. Tickets will go on sale sometime mid-August. Call for papers is now open, please submit your talks!</plug>
Then I got this following conversation with @rblackwe:
rblackwe: @lestrrat are you running Act on dotcloud?
lestrrat: @rblackwe nope. bunch of small custom psgi apps.
rblackwe: @lestrrat you hade me excited and hopeful.
... which is, well, understandable. By coincidence, I'd just had a conversation on IRC #act about this very fact on irc with Maddingue. I was being asked if we were using Act or not, and if not, why.
The short answer was: No, we haven't been using act since YAPC::Asia 2010, and the reason for that was 1) latency, and 2) admin burden.
I just released the Acme::CPANAuthors::India today, Its based on the Acme::CPANAuthors. There are similar pre-existing modules for other countries and especially extensive ones for most of europe in the Acme::CPANAuthors::* namespace but surprising India was missing in the list despite the large group or perlers here.
This also gave me the chance to use Dist::Zilla or dzil for the first time to do my module packaging. I like all the additional features that the plugins add to your distribution. especially the auto versioning, auto Generation of Module's README, MakeFile, Pod tests, METAs from your pod documentation is very cool. I do miss the more filling module template that ModuleMaker generates for the module itself however. I am sure there must be a way to generate a more comprehensive module template here. I am still looking and will update this thread with more soon.
Acme::CPANAuthors::India seeks to get all the CPAN Authors in India together into a single list for reference and link ups.
If you are supposed to be on this list and aren't then you can raise a bug at RT for this module at http://rt.cpan.org/NoAuth/Bugs.html?Dist=Acme-CPANAuthors-India with your Full Name and CPAN ID/HANDLE.
Today I'm signing up an account at Dangdang, a large Chinese e-commerce site (previously I've ordered Chinese books from Amazon.cn/Joyo, thought I'd try other sites). Their URLs have ".aspx" in them, but when I get a registration confirmation email, it says:
It's been several weeks since the first mojocast, and the response has been quite positive.
What started out as an excuse to use iMovie has turned into something useful and galvanizing. Especially encouraging are the comments from folks currently learning Perl; presenting n00b information in an easily consumable and pleasant manner solidifies new users' decisions that Perl is an excellent choice.
The second mojocast is forthcoming, delayed only by the process of moving; sleeping on couches en route has a negative effect on finding quiet locations with decent acoustics, and girls always want attention when you're in their house. Go figure.
Never fear, though, the second mojocast is nearly complete.
Anyone who wants to contribute to its launch and the marketing of Perl through mojocasts, please contact me directly - via comments, email, or in the #mojo irc channel. The comments for the first episode indicate that even the Ruby folk are surprised and impressed with a taste of Modern Perl, so the more people that are onboard, the better; there's every reason to work together to make an impact on Perl's impression in the open source community as a whole.