While I was focused on the social aspects of the PR Challenge, such as the IRC channel (opping literally everyone), the guides (wrote several), the repo (plus organization), and lately even a small parser for the web page Neil created (which will appear in another post), I still had my own responsibilities - mainly, my own PR challenge, and taking care of others' PR challenge contributions that fell under my purview.
As Neil categorized it in the title of this post, My first PR Challenge ( Poe::Component::DirWatch ) was definitely short , sweet and packed with value. When I attempted to work on this module I didn't find any issues to work on via the bug list. This lead me to jump into the PR Challenge irc chat where I got help from rjbs and ether on what I can do to submit my first pull request for this module. Of course the obvious answer was "Use the module" but while in the chat room rjbs did point out a bug ( documented here Moose::Classes ) that I ( without much experience on Moose) would not have been able to point out right away. After knowing this, I read some more Moose documentation and worked on my PR Challenge code .
This PR Challenge allow me to learn about Moose, namespace::clean and Test::CleanNamespaces ( The last 2 modules seem to be a better solution for my PR but I haven't installed the modules yet ) .
Thanks to everyone who pointed me in the right direction for my first PR Challenge.
Oh my bad! I missed to post here that I made a Grant proposal.
It often happens. It obviously happens so obviously often during the last 15-20 years that the other day a guy (C# programmer) on Facebook commented: "CMS in Perl?!? "It will scale with your business" hahahaha".
We obviously miss to say explicitly obvious things.
Yes, he does not know this is just a "Piece of cake" for us. Yes, it is so much "Piece of of cake" that almost nobody in the Perl community bothers to do it. Yeah, we have CPAN, we have CPANTESTERS, We have tied variables that some languages find very cool and trendy, and we even find them old fashioned, We are modern, we have Mo/o/se, ORMs and all the stuff, BUT "We suck at marketing".
Here is another, a bit less formal and more personal version.
Here I am
I took over the position of the Grants Committee secretary at the beginning of this year. I wanted to try a lot of things, some of which went great, but others were challenging.
People change
Besides me,
Daisuke Maki joined the committee as the first voting member from Japan. Perl community in Japan is often "invisible" and TPF is invisible in Japan due to the language barrier and he has been working hard to increase the visibility.
Mark Jensen joined us as a grant manager. I am sure a number of you enjoy his grant updates already. Behind the scene, he spends good amount of time to help the grants run smoothly.
Grant rules change
The grant evaluation is conducted every 2 months. It was quarterly until 2013.
The grant limit was raised from $3,000 to $10,000.
CLPM is my “Command Line Project Manager”. It’s a tool I wrote and have been using myself for several years now, and I am releasing it in the hope that others might find it useful.
Also, if you have been looking for an open source project to contribute to, here’s your chance! I don’t care what your level of experience is, if you think you have a useful comment or contribution, I’d like to hear from you!
There is a Todo section in the README, but I want to add a couple notes here:
It’s currently not packaged, nor does it have an installer. This probably makes it much less likely to be adopted.
I’m not sure how to promote it to make sure its audience (developers/sysadmins maybe) at least get a chance to see it, even if it ends up that it’s useful to nobody but me.
Firstly, some history:
Many, many years ago, I released a module called X500::DN. It was very crudely written,
and only handled the few DNs I had personally seen.
When I was reading through Perl Weekly newsletter the other day, I realized that there is a challenge named 'CPAN Pull Request Challenge'. Everyone was invited to join, and I decided to give it a go. It was organized by Neil Bowers, who explained the details right here.
The idea was simple: For each month in 2015, each participant will be assigned a CPAN module. Then they will be asked to contribute to the code. Be it improving documentation, writing more tests to improve test coverage, fixing a bug or actually implementing a new feature, you were to do something and then submit a pull request on GitHub. As this challenge was open to 'anyone', there were several documents explaining how GitHub works, and how to submit your first pull request and what not. If you have a look at blogs.perl.org, you'll see several of them. Even if you're not going to participate, they are still pretty decent how-to documents, and having a look will not hurt.
So I've done a very little (and to some extent very monkey-typing) patch for January.
I was assigned to Test::Pod.
The story of my first fail is here, and a little summary of what has been merged is here.
As pointed out in my previous post (here), in the January assignment on the Pull Request Challenge, I got the Data::ObjectDriver module.
For this module I created two very simple pull requests. One regarding its management with Module::Install, that is quite dependent on the author's taste. That one wasn't merged yet and who knows if it will. The second one, also very simple, just fixed a test that relied on a DBD::SQLite error message that changed with recent versions. This PR was merged, and a development version of the module just hit CPAN.
Meanwhile, I think the most interesting achievement on this month challenge was that with this we got SIXAPART guys, that use this module heavily, to adopt it. Therefore, the current maintainer that did not have much time for it can now rest, and the module will get updated in the future. Also, the SIXAPART guys just resurrected their CPAN account.
This all to say that this challenge can be useful in quite different way.s
Still, people discourage from Findbin usage, either because they don't know about the fix, or because 5.16 is not used everywhere yet. (Or because of any other reason? tell me)
Most of my READMEs are lame. I have stuff that no one will really ever use. As I'm cleaning up my distros, I starting thinking about what should be in there. To do that, I have to think about the people who would read such a thing.
A long time ago in an internet far, far away, READMEs were small documents that you could inspect before you committed to the full download. After that, we neglected them for a long time. Then GitHub started formatting them, so now they are interesting again.
But who would read them?
Some people turn the embedded module documentation into text and put that in the README, but that's so much easier to get on CPAN Search or MetaCPAN.
I don't think people read the file to get installation instructions or to discover my email address.
Looking around CPAN, I saw that I wasn't doing so poorly relative to everyone else. We, as a group, keep this thing around without really making it useful.
The CPAN Pull Request challenge has had way more signups than I was expecting:
343 so far! Some are very experienced Perl programmers and CPAN contributors;
some are long-term Perl programmers using this as a way to "give back";
a few are new to everything.
I wouldn't have predicted 300 pull requests in the entire year. Now we might
get that in January alone!
I know some people are concerned of the effect that this wave of locusts
enthusiastic contributors might have, particularly if authors have to start
dealing with pull requests that don't really add much value.
As a result I think it's probably helpful to give some more details on
the challenge, give CPAN authors a chance to comment, and even to opt out.
Update: Thanks for all of the replies. However, I now need to block further replies due to the huge amount of spam this post is getting.
I'm writing a talk for Fosdem entitled "Perl 6 -- A Dynamic Language for Mere Mortals." The talk is about Perl 6 and is aimed at programmers, not just Perl devs. As a result, I'd love to find examples in Java, Python, Ruby, and so on, which are roughly equivalent to the following Perl 6 class.
class Point {
subset PointLimit of Real where -10 <= * <= 10;
has PointLimit $.x is rw = 0;
has PointLimit $.y is rw = 0;
method Str { "[$.x,$.y]" }
}
I've been playing with the Makefile.PL modulino idea this week as part of my CPAN cleaning. It's dangerous to have so much fun because I'll keep working on it. Someone might need to take my GitHub away.
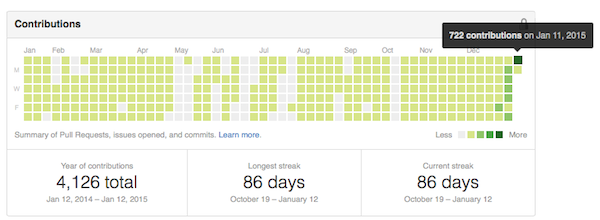
Before I go on, I'm disappointed to report that the green boxes in my GitHub activity are relative to me. I was happy to make dark green boxes each day this month, showing the highest level of commit(ment)s. But then I made a few changes to about 120 repositories and pushed about 700 commits one night. Some of that was turning on GitHub pages for everything, I think. That box turned dark green, but all of my other dark green boxes disappeared because the extent is relative to me and not some level set across all of GitHub.
Note: this was written off the cuff and is not comprehensive. In correspondence, Yves noted that such an article could/should cover more formats, e.g. MsgPack.
I [feel strongly] that Data::Dumper is generally unsuitable as a serialization tool. The reasons are as follows: